•
【Deepseek】Deepseek R1可能找到了超越人類的辦法
我本來想寫一篇關於DeepSeek R1 的科普文,但發現很多人僅僅把它理解為OpenAI 的複製品,而忽略了它在論文中揭示的“驚人一躍”,所以,我決定重寫一篇,講講從AlphaGo 到ChatGPT,再到最近的DeepSeek R1 底層原理的突破,以及為什麼它對所謂的AGI/ASI 很重要。作為一名普通的AI 演算法工程師,我可能無法做到非常深入,如有錯誤歡迎指出。
AlphaGo 突破人類上限
1997 年,IBM 公司開發的國際象棋AI 深藍,擊敗了世界冠軍卡斯帕羅夫而引發轟動;接近二十年後的2016 年,由DeepMind 開發的圍棋AI AlphaGo 擊敗了圍棋世界冠軍李世石,再次引發轟動。
表面上看這兩個AI 都是在棋盤上擊敗了最強的人類棋手,但它們對人類的意義完全不同。西洋棋的棋盤只有64 個格子,而圍棋的棋盤有19x19 個格子,假如我們用一盤棋能有多少種下法(狀態空間)來衡量複雜度,那麼二者對比如下:
1. 理論上的狀態空間
- 西洋棋:每局約 80 步,每步有 35 種走法→ 理論狀態空間為
- 圍棋:每局約 150 步,每步有 250 種走法→ 理論狀態空間為
2. 規則約束後的實際狀態空間
- 西洋棋:棋子移動受限(如兵不能倒退、王車易位規則) → 實際值
- 圍棋:棋子不可移動且依賴「氣」的判定→ 實際值
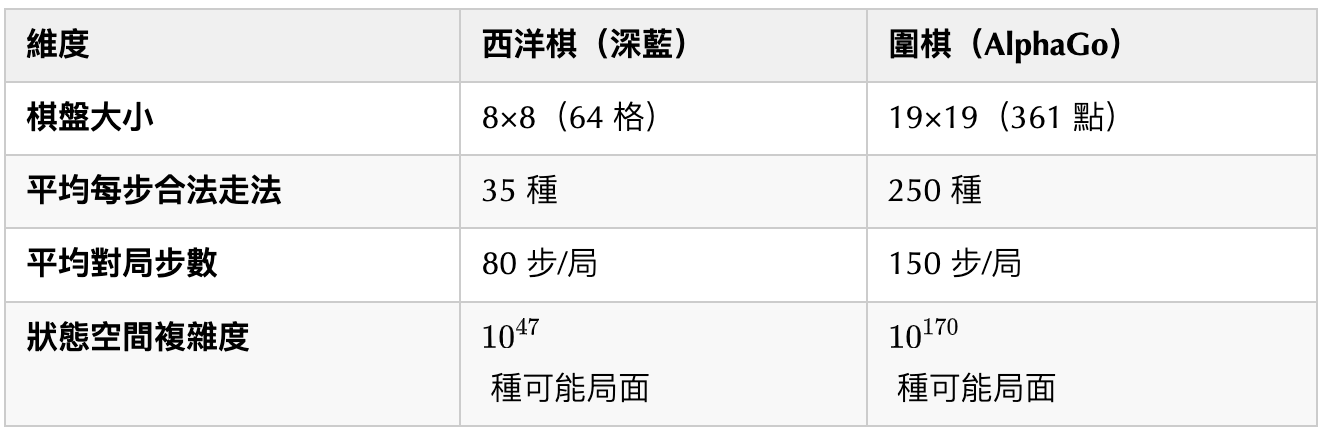
儘管規則大幅壓縮了複雜度,圍棋的實際狀態空間仍是國際象棋的 倍,這是一個巨大的量級差異,要知道,宇宙中的所有原子數量大約是 個。在範圍內的計算,依賴IBM 電腦可以暴力搜尋計算出所有可能的走法,所以嚴格意義上來講,深藍的突破和神經網路、模型沒有一點關係,它只是基於規則的暴力搜尋,相當於一個比人類快得多的計算器。
但的量級,已經遠遠超出了當前超級電腦的算力,這迫使AlphaGo 放棄暴力搜尋,轉而依賴深度學習:DeepMind 團隊首先用人類棋譜進行訓練,根據當前棋盤狀態預測下一步棋的最佳走法。但是,學習頂尖棋手走法,只能讓模型的能力接近頂尖棋手,而無法超越他們。
AlphaGo 先用人類棋譜訓練神經網路,然後透過設計一套獎勵函數,讓模型自我對弈進行強化學習。和李世石對弈的第二局,AlphaGo 的第19 手棋(第37 步[^1])讓李世石陷入長考,這步棋也被很多棋手認為是“人類永遠不會下的一步”,如果沒有強化學習和自我對弈,只是學過人類棋譜,AlphaGo 永遠無法下出這步棋。
2017 年5 月,AlphaGo 以3:0 擊敗了柯潔,DeepMind 團隊稱,有一個比它更強的模型還沒出戰。 [^2] 他們發現,其實根本不需要給AI 喂人類高手的對局棋譜,只要告訴它圍棋的基本規則,讓模型自我對弈,贏了就獎勵、輸了就懲罰,模型就能很快從零開始學會圍棋並超越人類,研究人員稱這個模型為AlphaZero,因為它不需要任何人類知識。
讓我重複一遍這個不可思議的事實:無需任何人類棋局作為訓練資料,僅靠自我對弈,模型就能學會圍棋,甚至這樣訓練出的模型,比喂人類棋譜的AlphaGo 更強大。
在此之後,圍棋變成了比誰更像AI 的遊戲,因為AI 的棋力已經超越了人類的認知範圍。所以,想要超越人類,必須讓模型擺脫人類經驗、好惡判斷(哪怕是來自最強人類的經驗也不行)的限制,只有這樣才能讓模型能夠自我博弈,真正超越人類的束縛。
AlphaGo 擊敗李世石引發了狂熱的AI 浪潮,從2016 年到2020 年,巨額的AI 經費投入最終收穫的成果寥寥無幾。數得過來的可能只有人臉辨識、語音辨識和合成、自動駕駛、對抗生成網路等——但這些都算不上超越人類的智慧。
為何如此強大的超越人類的能力,卻沒有在其他領域大放異彩?人們發現,圍棋這種規則明確、目標單一的封閉空間遊戲最適合強化學習,現實世界是個開放空間,每一步都有無限種可能,沒有確定的目標(比如「贏」),沒有明確的成敗判定依據(例如佔據棋盤更多區域),試錯成本也很高,自動駕駛一旦出錯後果嚴重。
AI 領域冷寂了下來,直到ChatGPT 的出現。
ChatGPT 改變世界
ChatGPT 被The New Yorker 稱為網路世界的模糊照片( ChatGPT Is a Blurry JPEG of the Web[^3]),它所做的只是把整個網路的文字資料送進一個模型,然後預測下一個字是_
這個字最有可能是"麼"。
一個參數量有限的模型,被迫學習幾乎無限的知識:過去幾百年不同語言的書籍、過去幾十年網際網路上產生的文字,所以它其實是在做資訊壓縮:將不同語言記載的相同的人類智慧、歷史事件和天文地理濃縮在一個模型裡。
科學家驚訝地發現:在壓縮中產生了智慧。
我們可以這麼理解:讓模型讀一本推理小說,小說的結尾"凶手是_",如果AI 能精準預測凶手的姓名,我們有理由相信它讀懂了整個故事,即它擁有“智能”,而不是單純的文字拼貼或死記硬背。
讓模型學習並預測下一個字的過程,被稱之為預訓練( Pre -Training),此時的模型只能不斷預測下一個字,但不能回答你的問題,要實現ChatGPT 那樣的問答,需要進行第二階段的訓練,我們稱之為監督微調(Supervised Fine-Tuning, SFT),此時需要人為建構一批問答資料,例如:
# 例子一人類:第二次世界大戰發生在什麼時候?AI:1939年
# 例子二人類:請總結下面這段話....{xxx}AI:好的,以下是總結:xxx值得注意的是,以上這些例子是人工建構的,目的是讓AI 學習人類的問答模式,這樣當你說"請翻譯這句:xxx"時,送給AI 的內容就是
人類:請翻譯這句:{xxx}AI:你看,它其實仍然在預測下一個字,在這個過程中模型並沒有變得更聰明,它只是學會了人類的問答模式,聽懂了你在要求它做什麼。
這還不夠,因為模型輸出的回答有時好、有時差,有些回答還涉及種族歧視、或違反人類倫理( "如何搶銀行?" ),此時我們需要找一批人,針對模型輸出的幾千筆資料進行標註:給好的答案打高分、給違反倫理的回答打負分,最終我們可以用這批標註資料訓練一個獎勵模型,它能判斷模型輸出的回答是否符合人類偏好。
我們用這個獎勵模型來繼續訓練大模型,讓模型輸出的回答更符合人類偏好,這個過程稱為透過人類回饋的強化學習(RLHF)。
總結一下:讓模型在預測下一個字的過程中產生智能,然後透過監督微調讓模型學會人類的問答模式,最後透過RLHF 讓模型輸出符合人類偏好的回答。
這就是ChatGPT 的大致思路。
大模型撞牆
OpenAI 的科學家們是最早堅信壓縮即智能的那批人,他們認為只要使用更海量優質的數據、在更龐大的GPU 叢集上訓練更大參數量的模型,就能產生更大的智能,ChatGPT 就是在這樣的信仰之下誕生的。 Google 雖然做了Transformer,但他們無法進行新創公司那樣的豪賭。
DeepSeek V3 和ChatGPT 所做的事差不多,因為美國GPU 出口管制,聰明的研究者被迫使用了更有效率的訓練技巧(MoE/FP8),他們也擁有頂尖的基礎設施團隊,最終只用了550 萬美元就訓練了比肩GPT-4o 的模型,後者的訓練成本超過1 億美元。
但本文重點是R1。
這裡想說的是,人類產生的數據在2024 年底已經被消耗殆盡了,模型的尺寸可以隨著GPU 叢集的增加,輕易擴大10 倍甚至100 倍,但人類每一年產生的新數據,相比現有的幾十年、過去幾百年的數據來說,增量幾乎可以忽略不計。而依照Chinchilla 擴展定律(Scaling Laws):每增加一倍模型大小,訓練資料的數量也應增加一倍。
這就導致了預訓練撞牆的事實:模型體積雖然增加了10 倍,但我們已經無法獲得比現在多10 倍的高品質資料了。 GPT-5 遲遲不發布、國產大模型廠商不做預訓練的傳聞,都跟這個問題有關。
RLHF 並不是RL
另一方面,基於人類偏好的強化學習(RLHF)最大的問題是:一般人類的智商已經不足以評估模型結果了。在ChatGPT 時代,AI 的智商低於普通人,所以OpenAI 可以請大量廉價勞動力,對AI 的輸出結果進行評測:好/中/差,但很快隨著GPT-4o/Claude 3.5 Sonnet 的誕生,大模型的智商已經超越了一般人,只有專家級的標註人員,才有可能幫助模型提升。
且不說聘請專家的成本,那專家之後呢?終究有一天,最頂尖的專家也無法評估模型結果了,AI 就超越人類了嗎?並不是。 AlphaGo 對李世石下出第19 手棋,從人類偏好來看,這步棋絕不會贏,所以如果讓李世石來做人類反饋(Human Feedback, HF)評價AI 的這步棋,他很可能也會給出負分。這樣,AI 就永遠無法逃出人類思維的枷鎖。
你可以把AI 想像成一個學生,給他打分數的人從高中老師變成了大學教授,學生的程度會變高,但幾乎不可能超越教授。 RLHF 本質上是一種討好人類的訓練方式,它讓模型輸出符合人類偏好,但同時它扼殺了超越人類的可能性。
所以我才說,RLHF 並不是RL,最近Andrej Karpathy 也發表了類似的看法[^4]。
OpenAI 的解法
丹尼爾‧卡尼曼在《思考快與慢》裡提出,人腦對待問題有兩種思考模式:一類問題不經過腦子就能給出回答,也就是快思考,一類問題需要類似圍棋的長考才能給答案,也就是慢思考。
既然訓練已經到頭了,那可否從推理,也就是給予回答的時候,透過增加思考時間,從而讓回答品質變好呢?這其實也有先例:科學家很早就發現,給模型提問時加一句:「讓我們一步一步思考」("Let's think step by step"),可以讓模型輸出自己的思考過程,最終給出更好的結果,這被稱為思維鏈(Chain-of-Thought, CoT)。
2024 年底大模型預訓練撞牆後,使用強化學習(RL)來訓練模型思維鏈成為了所有人的新共識。這種訓練大大提升了某些特定、客觀可測量任務(如數學、編碼)的表現。它需要從普通的預訓練模型開始,在第二階段使用強化學習訓練推理思維鏈,這類模型被稱為 Reasoning 模型,OpenAI 在2024 年9 月發布的o1 模型以及隨後發布的o3 模型,都是Reasoning 模型。
不同於ChatGPT 和GPT-4/4o,在o1/o3 這類Reasoning 模型的訓練過程中,人類回饋不再重要了,因為可以自動評估每一步的思考結果,從而給予獎勵/懲罰。 Anthropic 的CEO 在昨天的文章中[^5]用轉折點來形容這一技術路線:存在一個強大的新範式,它處於Scaling Law 的早期,可以快速取得重大進展。
雖然OpenAI 並沒有公佈他們的強化學習演算法細節,但最近DeepSeek R1 的發布,向我們展示了一種可行的方法。
DeepSeek R1-Zero
我猜DeepSeek 將自己的純強化學習模型命名為R1-Zero 也是在致敬AlphaZero,那個透過自我對弈、不需要學習任何棋譜就能超越最強棋手的演算法。
要訓練慢思考模型,首先要建構品質夠好的、包含思考過程的數據,並且如果希望強化學習不依賴人類,就需要對思考的每一步進行定量(好/壞)評估,從而給予每一步思考結果獎勵/懲罰。
如上文所說:數學和程式碼這兩個資料集最符合要求,數學公式的每一步推導都能被驗證是否正確,而程式碼的輸出結果以透過直接在編譯器上執行來檢驗。
舉個例子,在數學課本中,我們常看到這樣的推理過程:
<思考> 設方程根為x, 兩邊平方得: x² = a - √(a+x) 移項得: √(a+x) = a - x² 再次平方: (a+x) = (a - x²)² 展開: a + x = a² - 2a x² + x⁴ 整理: x⁴ - 2a x² - x + (a² - a) = 0</思考><回答>x⁴ - 2a x² - x + (a² - a) = 0</回答>上面這段文字就包含了一個完整的思考鏈,我們可以透過正規表示式來匹配出思考過程和最終回答,從而對模型的推理結果進行定量評估。
和OpenAI 類似,DeepSeek 的研究者基於V3 模型,在數學和程式碼這兩類包含思維鏈的資料上進行了強化學習(RL)訓練,他們創造了一種名為GRPO(Group Relative Policy Optimization)的強化學習演算法,最終得到的R1-Zero 模型在各項推理指標上相比DeepSeek V3 顯著提升,證明僅透過RL 就能激發模型的推理能力。
這是另一個AlphaZero 時刻,在R1-Zero 的訓練過程,完全不依賴人類的智商、經驗和偏好,僅靠RL 去學習那些客觀、可測量的人類真理,最終讓推理能力遠強於所有非Reasoning模型。
但R1-Zero 模型只是單純地進行強化學習,並沒有進行監督學習,所以它沒有學會人類的問答模式,無法回答人類的問題。並且,它在思考過程中,存在語言混合問題,一會兒說英語、一會兒說中文,可讀性差。所以DeepSeek 團隊:
- 先收集了少量高品質的Chain-of-Thought(CoT)數據,對V3 模型進行初步的監督微調,解決了輸出語言不一致問題,得到冷啟動模型。
- 然後,他們在這個冷啟動模型上進行類似R1-Zero 的純RL 訓練,並加入語言一致性獎勵。
- 最後,為了適應更普遍、廣泛的非推理任務(如寫作、事實問答),他們建構了一組資料對模型進行二次微調。
- 結合推理和通用任務數據,使用混合獎勵訊號進行最終強化學習。
這個過程大概就是:
監督學習(SFT) -> 強化學習(RL) -> 監督學習(SFT) -> 強化學習(RL)
經過以上過程,就得到了DeepSeek R1。
DeepSeek R1 給世界的貢獻是開源世界上第一個比肩閉源(o1)的Reasoning 模型,現在全世界的用戶都可以看到模型在回答問題前的推理過程,也就是"內心獨白",並且完全免費。
更重要的是,R1-Zero向研究者揭示了OpenAI 一直在隱藏的秘密:強化學習可以不依賴人類回饋,而純RL 也能訓練出最強的Reasoning 模型。所以在我心目中,R1-Zero 比R1 更有意義。
對齊人類品味VS 超越人類
幾個月前,我讀了Suno 和Recraft 創始人們的訪談[^6][^7],Suno 試圖讓AI 生成的音樂更悅耳動聽,Recraft 試圖讓AI 生成的圖像更美、更有藝術感。讀完後我有一個朦朧的感覺:將模型對齊到人類品味而非客觀真理,似乎就能避開真正殘酷的、性能可量化的大模型競技場。
每天跟所有對手在AIME、SWE-bench、MATH-500 這些榜單上競爭多累啊,而且不知道哪天一個新模型出來自己就落後了。但人類品味就像時尚:不會提升、只會改變。 Suno/Recraft 們顯然是明智的,他們只要讓行業內最有品味的音樂人和藝術家們滿意就夠了(當然這也很難),榜單並不重要。
但沒有客觀真理作為Benchmark的壞處也很明顯:你的努力和心血帶來的效果提升也很難被量化,例如,Suno V4 真的比V3.5 更好嗎?我的經驗是V4 隻是音質提升了,創造力並沒有提升。並且,依賴人類品味的模型注定無法超越人類:如果AI 推導出一個超越當代人類理解範圍的數學定理,它會被奉為上帝,但如果Suno 創造出一首人類品味和理解範圍外的音樂,在一般人耳朵裡聽起來可能只是單純的噪音。
對齊客觀真理的競爭痛苦但讓人神往,因為它有超越人類的可能。
對質疑的一些反駁
DeepSeek 的R1 模型,是否真的超越了OpenAI?
從指標來看,R1 的推理能力超越了所有的非Reasoning 模型,也就是ChatGPT/GPT-4/4o 和Claude 3.5 Sonnet,與同為Reasoning 模型的o1接近,遜色於o3,但o1/o3 都是閉源模型。
許多人的實際體驗可能不同,因為Claude 3.5 Sonnet 在對使用者意圖理解上更勝一籌。
DeepSeek 會收集使用者聊天內容來訓練
錯。很多人有個誤解,認為類似ChatGPT 這類聊天軟體會透過收集用戶聊天內容用於訓練而變得更聰明,其實不然,如果真是這樣,那麼微信和Messenger 就能做出世界上最強的大模型了。
相信你看完這篇文章就能意識到:大部分一般使用者的日常聊天資料已經不重要了。 RL 模型只需要在非常高品質的、包含思考鏈的推理資料上進行訓練,例如數學和程式碼。這些數據可以透過模型自己生成,無需人類標註。因此做模型資料標註的公司Scale AI 的CEO Alexandr Wang 現在很可能正如臨大敵,未來的模型對人類標註需求會越來越少。
DeepSeek R1 厲害是因為偷偷蒸餾了OpenAI 的模型
錯,R1 最主要的效能提升來自於強化學習,你可以看到純RL、不需要監督資料的R1-Zero 模型在推理能力上也很強。而R1 在冷啟動時使用了一些監督式學習數據,主要是用來解決語言一致性問題,這些數據並不會提升模型的推理能力。
另外,很多人對蒸餾有誤解:蒸餾通常是指用一個強大的模型作為老師(Teacher),將它的輸出結果作為一個參數更小、性能更差的學生(Student)模型的學習對象,從而讓學生模型變得更強大,例如R1 模型可以用於蒸餾LLama-70B,蒸餾的學生模型性能幾乎一定比老師模型更差,但R1 模型在某些指標性能比o1 更強,所以說R1 蒸餾自o1是非常愚蠢的。
我問DeepSeek 它說自己是OpenAI 的模型,所以它是套殼的。
大模型在訓練時並不知道當前的時間,自己究竟被誰訓練、訓練自己的機器是H100 還是H800,X 上有位使用者給出了精妙的比喻[^8]:這就像你問一個Uber乘客,他坐的這輛車輪胎是什麼品牌,模型沒有理由知道這些資訊。
一些感受
AI 終於除掉了人類回饋的枷鎖。 DeepSeek R1-Zero 展示瞭如何使用幾乎不使用人類回饋來提升模型性能的方法,這是它的AlphaZero 時刻。很多人曾說“人工智慧,有多少人工就有多少智能”,這個觀點可能不再正確了。如果模型可以根據直角三角形推匯出勾股定理,我們有理由相信它終有一天,能推匯出現有數學家尚未發現的定理。
寫程式碼是否仍然有意義?我不知道。今早看到Github 上熱門項目llama.cpp,一個程式碼共享者提交了PR,表示他透過對SIMD 指令加速,將WASM 運行速度提升2 倍,而其中99%的程式碼由DeepSeek R1 完成[^9] ,這肯定不是初級工程師等級的程式碼了,我無法再說AI 只能取代初級程式設計師。
當然,我仍然對此感到非常高興,人類的能力邊界再次被拓展了,幹得好DeepSeek!它是目前世界上最酷的公司。
參考資料
[^1]: Wikipedia: AlphaGo versus Lee Sedol
[^2]: Nature: Mastering the game of Go without human knowledge
[^3]: The New Yorker: ChatGPT is a blurry JPEG of the web
[^4]: X: Andrej Karpathy
[^5]: On DeepSeek and Export Controls
[^6]: Suno 創辦人訪談:至少對音樂來說,Scaling Law 不是萬靈藥
[^7]: Recraft 專訪:20 人,8 個月做出了最好的文生圖大模型,目標是AI 版的Photoshop
[^8]: X: DeepSeek forgot to censor their bot from revealing they use H100 not H800.
[^9]: ggml : x2 speed for WASM by optimizing SIMD (波斯兔子)