
DeepSeek OpenSourceWeek 的第二天,發布專家並行通訊庫DeepEP:首個面向MoE模型的開源EP通訊庫,支援實現了混合專家模型訓練推理的全端優化!感覺繼續深度綁定老黃的GPU,又和老黃對著乾😁
DeepEP 的核心亮點
✅ 高效優化的All-to-All 通訊: DeepEP 提供了高性能、低延遲的GPU 集群內和集群間all-to-all 通信內核,這正是MoE 模型中專家路由和組合的關鍵所在。 你可以把它理解為MoE 模型資料高速公路的升級版!
✅ 叢集內(Intranode) 與叢集間(Internode) 全面支援: 無論是單機多卡,或是多機多卡,DeepEP 都能完美駕馭。 它充分利用 NVLink 和 RDMA 等高速互聯技術,最大化通訊頻寬
✅ 訓練與推理預填(Prefilling) 的高效能內核: 對於模型訓練與推理預填階段,DeepEP 提供了高吞吐量的內核,保證資料傳輸速度,加速模型迭代和部署
✅ 推理解碼(Decoding) 的低延遲內核: 針對對延遲敏感的推理解碼場景,DeepEP 也準備了低延遲內核,採用純RDMA 通信,最大限度減少延遲,讓你的模型響應更快!
✅ 原生FP8 精確度支援: 跟上前緣技術,DeepEP 原生支援FP8 低精度運算,進一步提升運算效率,節省顯存
✅ 靈活的GPU 資源控制,實現計算-通信重疊: DeepEP 支援精細化的SM (Streaming Multiprocessors) 數量控制,並引入了基於Hook 的通信-計算重疊方法,巧妙地在後台進行通信,不佔用寶貴的GPU 計算資源! 這意味著什麼? 你的GPU 可以更專注於運算,通訊交給DeepEP 在幕後默默加速!
性能實測
DeepSeek 官方給出了DeepEP 在H800 伺服器上的實測數據,效果驚艷!
正常核心效能(NVLink + RDMA Forwarding):
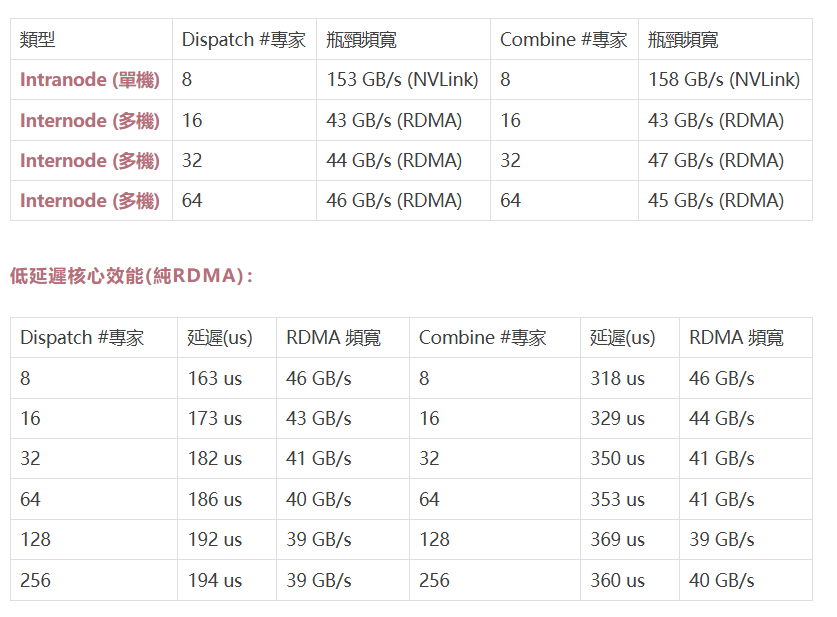
數據清晰地表明,DeepEP 在各種場景下都能提供出色的通訊效能! 無論是追求高吞吐量還是低延遲,DeepEP 都能滿足你的需求
快速上手DeepEP!
DeepEP 的使用也非常友好,官方提供了詳細的 快速開始(Quick Start) 指南和豐富的程式碼範例。 你只需要:
安裝完成後,你就可以在你的Python 專案中輕鬆匯入 deep_ep 庫,開始享受DeepEP 帶來的加速體驗!
github:https://github.com/deepseek-ai/DeepEP
網路配置和流量隔離,專業級的考量
DeepEP 充分考慮了實際應用場景中的網路環境,支援 InfiniBand 網絡,並且理論上相容於 RoCE (RDMA over Converged Ethernet)。 同時,DeepEP 也支援 Virtual Lanes (VL) 流量隔離,你可以根據不同類型的工作負載(普通核心、低延遲核心、其他負載) 分配不同的虛擬通道,避免互相干擾,確保通訊質量
自適應路由和擁塞控制,更智慧的網路管理!
DeepEP 也支援 自適應路由(Adaptive Routing) 功能(目前僅低延遲核心支援),可以更均勻地分配網路流量,避免網路擁塞。 當然,DeepEP 也考慮了 擁塞控制(Congestion Control),雖然目前預設為停用,但在未來的版本中可能會根據實際情況進行調整和最佳化
寫在最後:
一些重要提示(Notices):
MIT開源協定
DeepEP 程式碼庫基於 MIT License 開源,非常友善! 除了部分引用NVSHMEM 的程式碼外,你可以自由地使用、修改和分發DeepEP 程式碼
參考:https://github.com/deepseek-ai/DeepEP
~AI寒武紀