•
被Manus驚到了?OpenAI深夜發佈Agent開發三劍客!開源一個新的SDK,現場手搓三個Agent!還抖了一個內部的料
“2025年將是Agent之年,這一年,ChatGPT和我們的開發工具將從僅僅回答問題,轉變為真正為你在現實世界中做事。”
上周Manus通用智能體的發佈之後帶火了Claude的MCP框架之後,OpenAI終於坐不住了,今天凌晨一點通過直播的形式,一口氣把自己內部工程人員在用的Agent開發工具發佈了出來。
整體直播不長,只有20分鐘,但足以讓外界從OpenAI的視角來見識一番以全球最先進的基座模型來做出來的Agent的效果。
這次直播發佈了三款Agent開發工具:一系列內建工具、一個新的API以及一個開源SDK。
最大的一個感受是:此次OpenAI演示的Agent,不同之處已經突破了文字形式的檢索和輸出,強大的多模態理解的能力加上computer use工具,可以說打造的Agent的表現體驗是超過了Manus的Demo用例的。
話不多說,這就為大家總結一下。
OpenAI Agent開發者:拼湊低級API太難受了
OpenAI工程人員將Agent定義為一個能夠獨立行動、為您完成任務的系統。2025新年伊始,OpenAI在ChatGPT中發佈了兩種Agent。第一種是“Operator”,它可以瀏覽網頁並為使用者在網路上完成任務。第二種是“Deep Research”,它可以為你生成任何主題的詳細報告,你只需要提供一個主題,它就可以在15分鐘內完成可能需要一周時間的研究並給出答案。
於此同時,OpenAI也推出一系列新工具,能夠讓開發者能夠輕鬆建構可靠且有用的Agent。OpenAI希望將這些工具以及更多功能通過API提供給開發者。
不過在剛剛過去的3個月裡,OpenAI正在與世界各地的開發者交流,探討如何讓他們更輕鬆地建構代理。
而據開發者反饋,主要有兩點,一是模型已經準備就緒。憑藉先進的推理能力和多模態理解能力,我們的模型現在能夠完成代理所需的複雜多步驟工作流。但另一方面,開發者們表示,他們不得不拼湊來自不同來源的低級API,這不僅困難、速度慢,而且常常顯得脆弱。
因此,OpenAI做了這樣一個決定:今天把這些工具整合成一系列工具、新的API以及新的開源SDK,讓這一切變得更加容易。
內建工具好用到絲滑:兩個search、一個computer use
開發者體驗團隊的工程師lan、API團隊的工程師Steve、API產品團隊人員Nick分別介紹了今天OpenAI所推出的所有內容。
先從內建工具說起。正如上面圖中所演示的,分別是網路搜尋工具Web search和檔案搜尋工具File search。
其中網路搜尋工具可以允許OpenAI的模型訪問網際網路上的資訊,從而確保使用者的回答和輸出內容是最新的。
據介紹,網路搜尋工具是為ChatGPT搜尋提供動力的工具,它由一個經過微調的GPT-4o或4o mini模型來驅動。它非常擅長從網路上檢索大量資料,找出相關資訊,並在回答中清晰地引用這些資訊。在衡量這類功能的基準測試中,例如簡單問答的測試中,GPT-4o的得分達到了90%的頂尖水平。
而第二個工具,檔案搜尋工具則是Steve的最愛。去年,OpenAI在輔助API中推出了檔案源工具,方便開發者上傳、嵌入他們的文件,並輕鬆地在這些文件上進行RAG操作。而今天,OpenAI則在檔案搜尋工具中推出兩個新功能。
第一個是中繼資料過濾。通過中繼資料過濾,使用者可以為檔案加入屬性,以便輕鬆篩選出與使用者查詢最相關的檔案。第二個是直接搜尋端點。即,使用者現在可以直接搜尋向量儲存庫,而無需讓模型填充使用者查詢。
這兩個工具可為最強搭檔,網路搜尋工具用於公共資料,檔案搜尋工具則用於私有資料。
第三個工具是電腦使用(Computer Use)工具。在API中,它被稱為operator,它允許使用者控制所正在操作的電腦。這可以是一台虛擬機器,也可以是一個只有圖形使用者介面的遺留應用程式,但使用者通常沒有API存取權。
如果你想自動化這類任務並在此基礎上建構應用程式,就可以使用電腦使用工具,它配備了電腦使用模型。這個模型與ChatGPT中的Operator使用的是同一個模型。它在OS世界網路、網路航海家等基準測試中表現出色,早期使用者對該模型的反饋也非常積極。
新的API:足夠靈活的響應API
在開發這些工具並考慮如何推出它們時,OpenAI還從第一性原理出發,設計了最適合這些工具的API。
OpenAI在2023年3月與GPT3.5 Turbo一起發佈了“聊天實現”功能,當時的每個API互動都只是輸入文字和輸出文字。
很快,OpenAI就引入了多模態模型,圖像、音訊也都具備了理解能力。此外,OpenAI也正在引入工具,還有像o1 Pro、Deep Research、Operator這樣的產品,它們在幕後進行了多次模型互動和多次工具呼叫。
因此,OpenAI想要建構一個足夠靈活的API原語,它支援多輪互動,支援工具,我們稱這個新的API為“響應API”。
Steve在現場手搓了一個新API的Agent演示。操作非常簡單,如果你之前使用過“聊天實現”功能,看起來將非常熟悉:選擇一些上下文,選擇一個模型,然後得到一個回答。只需要在response欄位中的補充instruction的內容即可。
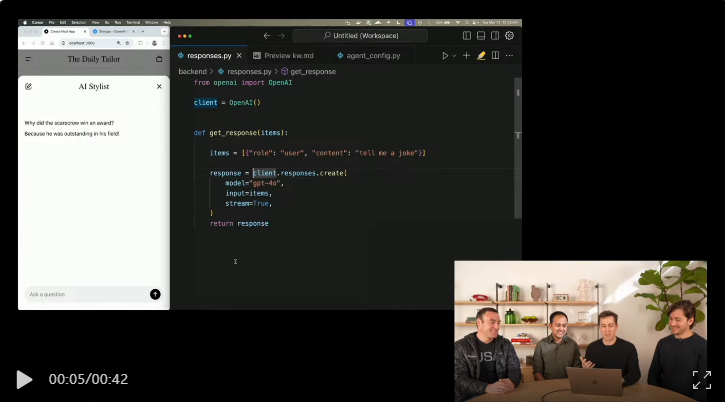
為了展示響應API的強大功能,Steve打算建構一個個人時尚助手。
這個例子很有代表性,個人時尚助手首先肯定要瞭解使用者的喜好。
為此,Steve建立了一個向量資料庫,為了直播效果,Steve還爆料稱其中的一些條目是自己團隊成員的穿著記錄,他們為此一直在辦公室裡跟蹤人們,瞭解他們的動態和穿搭。
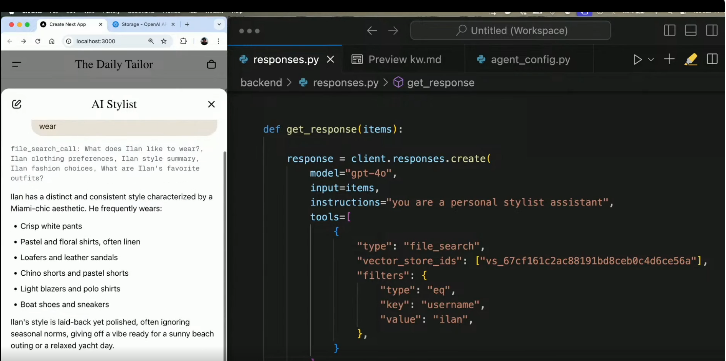
演示說明:“我們有一個完整的業務團隊在研究這個,所以我會加入檔案搜尋工具,並複製其向量儲存ID。在這裡,我實際上可以將儲存庫中的檔案篩選到與你想要的風格相關的檔案。所以,我們先從ilan開始。我們將篩選到他的名字,然後返回到這裡,我們會刷一下並說‘可以’。”
不過這些資料庫裡的資料也有可能是陳舊的。這時候瀏覽器工具是一個很好的方式,可以將使用者的最新的資訊帶入你的應用程式。“所以為了為這個個人時尚助手建立一個真正好的應用程式,我們希望能夠從網路上獲取最新資料,以便我們既有最新資訊,也有與你的使用者真正相關的內容。”
為了展示這一點,Steve演示了加入網路搜尋工具的過程。“網路搜尋工具真的很棒,因為你還可以加入關於你使用地點的資訊。”
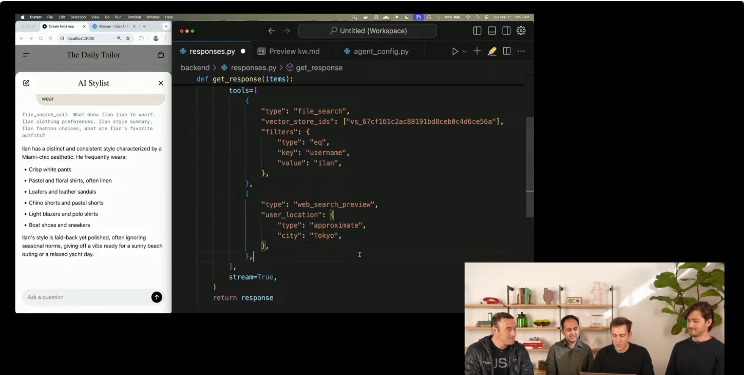
響應API理解起來非常簡單,因為它可以呼叫檔案搜尋工具,也可以呼叫網路搜尋工具,並且可以在一次API響應中給出最終答案。為了告訴它我們到底想要什麼,讓我們給它一些指令。
比如:我們希望模型在被要求推薦產品時,可以使用檔案搜尋工具瞭解Kevin的喜好,然後使用網路搜尋工具找到他所在位置附近的一家商店,他可能會對那裡感興趣。所以,我們可以回去在對話方塊中提示:“找一件夾克”。
這樣,模型將發出檔案搜尋呼叫,以瞭解Kevin過往喜歡穿什麼樣的東西。然後,它將發出網路搜尋工具呼叫,以找到基於他所在位置的他可能會喜歡的東西。所以,模型能夠在一次API呼叫的範圍內,找到很多Patagonia,這實際上與Kevin的偏好相符。“他一直在辦公室裡穿很多Patagonia,但一個個人時尚助手如果不為你代購就不算完整。”
接下來就是重頭戲,computer use。使用電腦使用預覽模型和電腦使用預覽工具也非常簡單,見下面的現場操作視訊。
只需要在resonse欄位中生命model為computer-use-preview模型即可。
在直播中的例子,該模型要求電腦提供一個截圖,並在這個電腦上運行一個本地Docker容器。在電腦上傳完截圖後,該API將查看電腦的狀態並行出另一個動作:點選、拖動、移動、輸入,然後電腦將執行那個動作。再截一個圖,把它發回模型,然後它將繼續以這種方式進行,直到它認為任務已經完成,然後返回一個最終答案。
開放原始碼的代理SDK: 更複雜的Agent怎麼辦?
對於那些建構更複雜應用程式的人來說,比如你正在建構一個客戶支援代理,處理退款的代理應用程式,還有另一個處理客戶支援常見問題查詢的,還有處理訂單和帳單的等等。考慮到這一類的Agent,OpenAI去年發佈了一個名為Swarm的SDK,Swarm使代理編排變得容易。
“這本該是一個實驗性和教育性的東西,但企業使用者中很多人都將其投入生產了。”
因此,在使用者的倒逼之下,OpenAI決定將Swarm打造成一個生產級的產品,增加許多新功能,並且我們將重新將其命名為代理SDK(Agents SDK)。
據開發Swarm的工程師ilan介紹,他花了很多時間與企業和建設者合作,幫助他們建構代理體驗,並親眼看到一些簡單的想法在實際實施時會變得多麼複雜。
因此,代理SDK的理念是保持簡單想法的簡單性,同時允許你以一種相當簡單的方式建構更複雜、更健壯的想法。
初體驗上跟上面的Response API有些類似,需要定義代理,有一些指令,同樣需要檔案搜尋和網路搜尋這兩個工具。
默認情況下,該SDKh會使用Response API,但OpenAI實際上支援多個供應商,任何真正符合“聊天實現”功能的都可以與代理SDK一起工作。
不過問題在於,比如,你想在個人時尚代理上加入“退貨”,“訂單”等不同的業務邏輯,就會讓代理的測試變得困難。
所以,推薦還是按照“多Agent”的思路來進行設計,這樣可以真正分離關注點並分別開發和測試它們。
而在新的SDK中,已經預置了客戶支援代理,可以支援獲取過往訂單並提交退款要求。表面上這些只是普通的Python函數,但實際上都是Swarm中非常受喜歡的功能。
OpenAI將其這些Python函數帶到了代理SDK中,並查看其類型推斷或類型簽名,然後自動生成模型需要使用的JSON模式以執行這些函數呼叫。然後,一旦完成這些,Agent就可以運行程式碼並返回結果。
當然,這些Python函數使用者也可以自訂。
多個代理之間如何互動通訊呢?OpenAI提出了“交接”的概念,即一個代理熟悉後,然後將其傳遞給另一個代理。在幕後,你保持整個對話的完整性,只是替換指令和工具,這為你提供了一種方式來分流對話並載入正確的上下文。
所以,還需要在原有的代理之上再建立了一個分流代理,它可以將對話傳遞給時尚助手代理或客戶支援代理。
開發者肯定關心系統幕後究竟發生了什麼。通常往往需要開發者手動加入一些偵錯語句,但代理SDK不需要,它的監控和追蹤功能是開箱即用的,非常簡潔。
通過OpenAI的追蹤UI,可以看出剛剛每一步都發生了什麼。比如:刷新了頁面;從分流代理開始,傳送了一個請求,進行了交接,然後切換到客戶支援代理,它呼叫了一個函數;這裡值得一說的是,交接在這裡是一個一級對象,所以你可以看到我們實際上將它交給了那個代理,以及它沒有選擇的其他選項,這實際上是一個非常有用的偵錯功能。
一旦進入客戶支援代理,你就可以看到它呼叫了“獲取過往訂單”函數。最後,我們得到了一個回覆。
此外,代理SDK還推出了一些其他內建的防護欄,你可以啟用它們,我們有生命周期事件,最重要的是,這是一個開源框架,所以我們會繼續建構它,你很快就可以安裝它。
現在你可以通過pip install OpenAI-middle-dash-agents來安裝,據悉,OpenAI很快也會推出JavaScript版本。
One More Thing:舊API計畫停用
一、OpenAI此次引入了Response API,但“聊天實現”功能API並不會消失。OpenAI將繼續用新模型和能力支援它。不過後續OpenAI發佈的一些需要這些功能的模型和產品,將僅在Response API中提供。
二、Response API的功能是聊天實現API支援功能的超集。所以,使用者遷移到Response API時的過程將非常簡單。
三、Assistance API即將遷移。OpenAI根據所有測試使用者提供的反饋建構了Assistance API。“沒有在AssistanceAPI階段學到的經驗,我們也不會走到今天。”
OpenAI將為Response API增加更多功能,使其能夠支援Assistance API所做的一切。一旦完成,該公司就會發佈一個遷移指南,讓應用程式無損地從AssistanceAPI遷移到ResponseAPI。
一旦完成,OpenAI計畫停用輔助API。
最後,對於今天的深夜發佈:兩個內建工具web search/file search、一個新API(Response)、一個開放原始碼的代理SDK,大家如何看待呢?
會不會跟一些網友一樣,覺得有點小遺憾:為什麼不是GPT5呢?
不管怎樣,從純對話的Agent到能真正用於生產提效率的高級自主Agent,註定會發生在2025。 (51CTO技術堆疊)