OpenAI推出語音智能體全家桶:可以實現前所未有的精細化教AI說話
就在剛剛,OpenAI 發佈了一系列新模型和工具,具體來說OpenAI在API 中推出三種新的先進音訊模型:
🗣️ 兩種語音轉文字模型 - 表現優於 Whisper
💬 新的 TTS (文字轉語音)模型——你可以教AI如何說話
核心只有一個:讓開發者輕鬆建構強大的「語音智能體」!
在直播中,據OpenAI 平台負責人 Olivier Godement 說他們一直在積極建構 AI 智能體,而現在,他們要將重點從文字拓展到語音
為什麼是語音? Olivier 認為,語音是人類最自然的互動方式,相較於讀寫,語音溝通更加便捷和人性化。 因此,打造可靠、精準、靈活的語音智能體,將極大地拓展 AI 的應用場景
第一時間給大家劃個重點
三大模型齊發力,打造「聲控AI」基石
為了實現這一願景,OpenAI 祭出了三大法寶:
1.兩款全新「語音轉文字」模型:GPT-4o-transcribe 和 GPT-4o-mini-transcribe
這兩款模型號稱“地表最強”,性能全面超越之前的 Whisper 模型,並且在各種語言的轉錄精準率上都實現了質的飛躍。這意味著,AI 聽得更清、更準了!
2.全新「文字轉語音」模型:GPT-4o-mini-tts
這款模型首次讓開發者可以精細控制 AI 的發聲方式,不僅能決定 AI 說什麼,更能控制 AI 怎麼說!語調、情感,都能由你掌控,打造更富有人性的聲音體驗
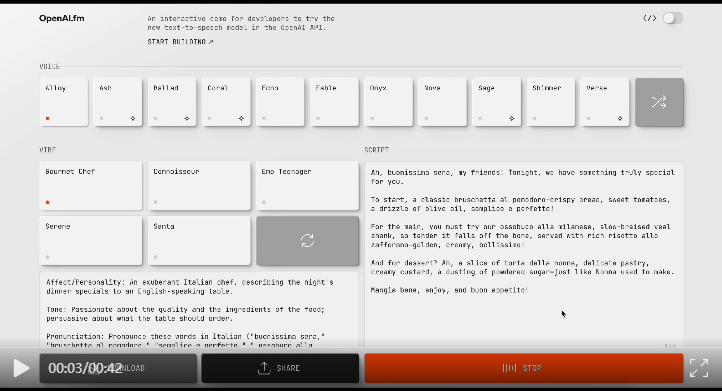
為了讓大家更容易得使用這個模型,OpenAI為這個模型建了新的網站,http://OpenAI.fm,一個供開發人員嘗試 OpenAI API 中的新文字轉語音模型的互動式演示,OpenAI已經預先生成了各種演示文字,可以選擇不同的聲音,不同的情緒來表達你的文字,你也可以自己輸入文字,體驗選擇不同聲音和情緒來表達
3.升級版 Agent SDK
為了讓開發者更便捷地建構語音智能體,OpenAI 對之前發佈的 Agent SDK 進行了重大更新,讓文字智能體“一鍵升級”為語音智能體成為可能!這次升級亮點頗多:
語音能力加持: Agent SDK 深度整合了 OpenAI 最新的「語音轉文字」和「文字轉語音」模型,開發者無需複雜組態,即可為智能體賦予“耳朵”和“嘴巴”。
流式處理最佳化: 升級後的 SDK 支援雙向流式傳輸,音訊輸入和語音輸出都更加即時,大幅提升了語音互動的流暢性。
開箱即用,快速上手: Agent SDK 提供了豐富的示例程式碼和詳盡的文件,即使是新手開發者也能快速上手,將文字智能體輕鬆轉化為語音智能體
偵錯利器: Agent SDK 與 OpenAI 偵錯 UI 無縫整合,開發者可以直觀地追蹤語音互動全過程,分析音訊輸入、文字轉錄、模型推理、語音合成等各個環節,Debug 效率直線提升!
建構語音智能體,兩種主流方案
OpenAI 的專家 Jeff Harris 在直播中分享了建構語音智能體的兩種主要方法:
方法一:即時 API 直連「語音-語音」模型
這種方式更加前沿,直接使用「語音-語音」模型,讓 AI 直接理解音訊並輸出語音,速度更快,體驗更流暢。 這也是 ChatGPT 高級語音模式背後的技術
方法二:鏈式呼叫音訊模型與文字模型
這是一種更易上手、更可靠的方案,也是 OpenAI 此次重點推薦的方式。 它通過以下步驟實現:
- 語音轉文字模型 (Speech-to-Text): 將使用者語音轉化為文字。
- 文字大模型 (Text-based LLM): 例如 GPT-4o,理解文字並生成合適的回覆。
- 文字轉語音模型 (Text-to-Speech): 將文字回覆轉化為自然流暢的語音。
Jeff 強調,鏈式方案的優勢在於:
- 模組化: 各個環節的模型可以靈活替換,選擇最適合的元件。
- 高可靠性: 文字模型的智能程度依然是目前的“黃金標準”,鏈式方案能保證更高的可靠性。
- 易上手: 開發者可以基於已有的文字智能體項目,快速加入語音功能
模型背後的技術
使用真實音訊資料集進行預訓練
新音訊模型基於 GPT‑4o 和 GPT‑4o-mini 架構,並在專門的以音訊為中心的資料集上進行了廣泛的預訓練,這對於最佳化模型性能至關重要。這種有針對性的方法可以更深入地洞察語音細微差別,並在與音訊相關的任務中實現出色的性能
先進的蒸餾方法
增強蒸餾技術,使知識從最大的音訊模型轉移到更小、更高效的模型。利用先進的自我對弈方法,我們的蒸餾資料集有效地捕捉了真實的對話動態,複製了真正的使用者-助手互動。這有助於小型模型提供出色的對話質量和響應能力
強化學習範式
對於語音轉文字模型,整合了強化學習 (RL-heavy) 重度範式,將轉錄精準度推向了最先進的水平。這種方法大大提高了準確度並減少了幻覺,使語音轉文字解決方案在複雜的語音識別場景中具有極強的競爭力
性能炸裂,價格親民
GPT-4o 系列「語音轉文字」模型的驚人性能:在 FLEURS 基準測試中,錯誤率遠低於上一代 Whisper 模型,真正做到了“更上一層樓”
更令人驚喜的是,價格方面也十分良心:
- GPT-4o-transcribe: 每分鐘 0.6 美分,與 Whisper 模型價格一致
- GPT-4o-mini-transcribe: 每分鐘僅需 0.3 美分,性價比更高!
- GPT-4o-mini-tts: 文字轉語音模型,每分鐘 1 美分,經濟實惠
參考:
https://openai.com/index/introducing-our-next-generation-audio-models/
https://www.youtube.com/watch?v=lXb0L16ISAc (AI寒武紀)