
【新智元導讀】阿里Qwen3凌晨開源,正式登頂全球開源大模型王座!它的性能全面超越DeepSeek-R1和OpenAI o1,採用MoE架構,總參數235B,橫掃各大基準。這次開放原始碼的Qwen3家族,8款混合推理模型全部開源,免費商用。
就在今天凌晨,備受全球期待的阿里新一代通義千問模型Qwen3開源!
一經問世,它立刻登頂全球最強開源模型王座。
它的參數量僅為DeepSeek-R1的1/3,但成本大幅下降,性能全面超越R1、OpenAI-o1等全球頂尖模型。
Qwen3是國內首個「混合推理模型」,「快思考」與「慢思考」整合進同一個模型,對簡單需求可低算力「秒回」答案,對複雜問題可多步驟「深度思考」,大大節省算力消耗。
它採用混合專家(MoE)架構,總參數量235B,啟動僅需22B。
它的預訓練資料量達36T ,並在後訓練階段多輪強化學習,將非思考模式無縫整合到思考模型中。
一經誕生,Qwen3立刻橫掃各大基準。
而且,性能大幅提升的同時,它的部署成本還大幅下降,僅需4張H20即可部署Qwen3滿血版,視訊記憶體佔用僅為性能相近模型的1/3!
亮點總結:
各種尺寸的稠密模型和混合專家(MoE)模型,包括0.6B、1.7B、4B、8B、14B、32B以及30B-A3B和235B-A22B。
- 能夠在思考模式(用於複雜的邏輯推理、數學和編碼)和非思考模式(用於高效的通用聊天)之間無縫切換,從而確保在各種場景中實現最佳性能。
- 推理能力顯著增強,在數學、程式碼生成和常識邏輯推理方面,超越了之前處於思考模式下的QwQ和處於非思考模式下的Qwen2.5 instruct模型。
- 更符合人類偏好,擅長創意寫作、角色扮演、多輪對話和指令遵循,從而提供更自然、引人入勝和更真實的對話體驗。
- 精通AI智能體能力,支援在思考和非思考模式下與外部工具的精確整合,並在複雜的基於智能體的任務中,在開源模型中實現了領先的性能。
- 首次支援119種語言和方言,具有強大的多語言指令跟隨和翻譯能力。
目前,Qwen 3已同步上線魔搭社區、Hugging Face、GitHub,並可線上體驗。
全球開發者、研究機構和企業均可免費下載模型並商用,也可以通過阿里雲百煉呼叫Qwen3的API服務。個人使用者可立即通過通義APP直接體驗Qwen3,夸克也即將全線接入Qwen3。
魔搭社區:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
Hugging Face:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
GitHub:https://github.com/QwenLM/Qwen3
至此,阿里通義已開源200余個模型,全球下載量超3億次,千問衍生模型數超10萬個,徹底超越美國Llama,成為全球第一開源模型!
Qwen 3家族登場
8款「混合推理」模型全開源
這次,阿里一口氣開源了8款混合推理模型,包括2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款稠密模型,均採用 Apache 2.0許可。
其中,每款模型均斬獲同尺寸開源模型SOTA。
Qwen3的30B參數MoE模型實現了10倍以上的模型性能槓桿提升,僅啟動3B就能媲美上代Qwen2.5-32B模型性能。
Qwen3的稠密模型性能繼續突破,一半的參數量可實現同樣的高性能,如32B版本的Qwen3模型可跨級超越Qwen2.5-72B性能。
同時,所有Qwen3模型都是混合推理模型,API可按需設定「思考預算」(即預期最大深度思考的tokens數量),進行不同程度的思考,靈活滿足AI應用和不同場景對性能和成本的多樣需求。
比如,4B模型是手機端的絕佳尺寸;8B可在電腦和汽車端側絲滑部署應用;32B最受企業大規模部署歡迎,有條件的開發者也可輕鬆上手。
開源模型新王,刷新紀錄
Qwen3在推理、指令遵循、工具呼叫、多語言能力等方面均大幅增強,即創下所有國產模型及全球開源模型的性能新高——
在奧數水平的AIME25測評中,Qwen3斬獲81.5分,刷新開源紀錄。
在考察程式碼能力的LiveCodeBench評測中,Qwen3突破70分大關,表現甚至超過Grok3。
在評估模型人類偏好對齊的ArenaHard測評中,Qwen3以95.6分超越了OpenAI-o1及DeepSeek-R1。
具體來說,旗艦模型 Qwen3-235B-A22B與其他頂級模型(如DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro)相比,在編碼、數學、通用能力等各項基準測試中,成績都相當亮眼。
此外,小型混合專家模型Qwen3-30B-A3B雖然啟動參數隻有QwQ-32B的十分之一,但性能卻更勝一籌。
甚至是Qwen3-4B這樣的小模型,也能媲美Qwen2.5-72B-Instruct的性能。
經過微調的模型,如Qwen3-30B-A3B,及其預訓練版本(如 Qwen3-30B-A3B-Base),現在都可在Hugging Face、ModelScope 和Kaggle等平台上找到。
對於部署,阿里推薦使用SGLang和vLLM等框架。對於本地使用,強烈推薦Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具。
無論研究、開發還是生產環境,Qwen3都可輕鬆整合到各種工作流程中。
利多智能體Agent和大模型應用爆發
可以說,Qwen3為即將到來的智能體Agent和大模型應用爆發提供了更好的支援。
在評估模型Agent能力的BFCL評測中,Qwen3創下70.8的新高,超越Gemini2.5-Pro、OpenAI-o1等頂尖模型,這將大幅降低Agent呼叫工具的門檻。
同時,Qwen3原生支援MCP協議,並具備強大的工具呼叫能力,結合封裝了工具呼叫範本和工具呼叫解析器的Qwen-Agent框架。
這將大大降低編碼複雜性,實現高效的手機及電腦Agent操作等任務。
主要特點
混合推理模式
Qwen3模型引入了一種混合問題解決方式。它們支援兩種模式:
1. 思考模式:在該模式下,模型會逐步推理,然後給出答案。這適合需要深入思考的複雜問題。
2. 非思考模式:在該模式下,模型會快速給出答案,適用於對速度要求較高的簡單問題。
這種靈活性,讓使用者可以根據任務的複雜程度,控制模型的推理過程。
例如,難題可以通過擴展推理來解決,而簡單的問題可以直接回答,而不會延遲。
至關重要的是,這兩種模式的結合,大大提高了模型穩定高效地控制推理資源的能力。
如上所示,Qwen3表現出可擴展且平滑的性能改進,這與分配的計算推理預算直接相關。
這種設計使使用者能夠更輕鬆地組態特定於任務的預算,從而在成本效率和推理質量之間實現更最佳化的平衡。
多語言支援
Qwen3模型支援119種語言和方言。
如此廣泛的多語言能力,也意味著Qwen 3有極大潛力建立風靡全球的國際應用。
更強大的智能體能力
阿里對Qwen3模型進行了最佳化,以提高編碼和智能體能力,並且還加強了對MCP的支援。
下面這個示例,很好地展示了Qwen3是如何思考並與環境互動的。
36兆token,多階段訓練
作為千問系列最強模型,Qwen3究竟是如何實現如此驚豔的表現?
接下來,一起扒一扒Qwen3背後技術細節。
預訓練
與Qwen2.5相比,Qwen3預訓練資料集規模幾乎是上一代兩倍,從18兆個token擴展到了36兆個token。
它覆蓋了119種語言和方言,不僅來源於網路,還包括從PDF等文件中提取文字內容。
為了確保資料質量,團隊利用Qwen2.5-VL提取文件文字,並通過Qwen2.5最佳化提取內容的精準性。
此外,為了提升模型在數學和程式碼領域的表現,Qwen3還通過Qwen2.5-Math和Qwen2.5-Coder生成大量合成資料,包括教科書、問答對和程式碼片段。
Qwen3預訓練過程,一共分為三個階段,逐步提升模型的能力:
第一階段(S1):基礎語言能力建構
使用超30兆個token,以4k上下文長度進行預訓練。這一階段為模型奠定了紮實的語言能力和通用知識基礎。
第二階段(S2):知識稠密型最佳化
通過增加STEM、編碼和推理任務等知識稠密型資料的比例,模型在額外5兆和token上繼續訓練,進一步提升專業能力的表現。
第三階段(S3):上下文能力擴展
利用高品質上下文資料,將模型的上下文長度擴展至32k,確保其能夠處理複雜、超長輸入。
得益於模型架構最佳化、資料規模擴展和更高效的訓練方法,Qwen3 Dense基礎模型展現出亮眼的性能。
如下表所示,Qwen3-1.7B/4B/8B/14B/32B-Base可以媲美Qwen2.5-3B/7B/14B/32B/72B-Base,以更小的參數量達到更大模型的水平。
尤其是,在STEM、編碼和推理等領域,Qwen3 Dense基礎模型甚至優於更大的Qwen2.5模型。
更令人矚目的是,Qwen3 MoE模型僅用10%啟動參數,即可實現Qwen2.5 Dense基礎模型相似的性能。
這不僅大幅降低了訓練和推理成本,還為模型的實際部署提供了更高的靈活性。
後訓練
為了打造一個既能進行複雜推理,又能快速響應的混合模型,Qwen3設計了一個四階段後訓練流程。
1. 長思維鏈冷啟動
使用多樣化的長思維鏈資料,覆蓋數學、編碼、邏輯推理和STEM問題,訓練模型掌握基本的推理能力。
2. 長思維鏈強化學習
通過擴展RL的計算資源,結合基於規則的獎勵機制,提升模型在探索和利用推理路徑方面的能力。
3. 思維模式融合
使用長思維鏈資料和指令微調資料進行微調,將快速反應能力融入推理模型,確保模型在複雜任務中既精準又高效。
此資料由第二階段的增強思考模型生成,確保推理和快速響應能力的無縫融合。
4. 通用強化學習
在20多個通用領域任務,如指令遵循、格式遵循和智能體能力中應用RL,進一步提升模型的通用性和魯棒性,同時糾正不良行為。
全網好評如潮
Qwen3開源不到3小時,GitHub狂攬17k星,徹底點燃了開源社區的熱情。開發者們紛紛下載,開啟了極速測試。
項目地址:https://github.com/QwenLM/Qwen3
蘋果工程師Awni Hannun宣佈,Qwen3已經得到MLX框架支援。
而且,不論是iPhone(0.6B, 4B),還是MacBook(8B, 30B, 3B/30B MoE)、M2/M3 Ultra(22B/235B MoE)消費級裝置,均可本地跑。
他在M2 Ultra上運行了Qwen3 235B MoE,生成速度高達28 token/s。
有網友實測後發現,與Qwen3大小相同的Llama模型,簡直不在一個等級上。前者推理更深入,保持更長上下文,還能解決更難的問題。
還有人表示,Qwen3就像是一個DeepSeek時刻。
官方指南
如何用Qwen3進行開發
這次,阿里還放出了在不同框架上使用Qwen3的簡單指南。
首先,這是一個在Hugging Face transformers中使用Qwen3-30B-A3B的標準示例:
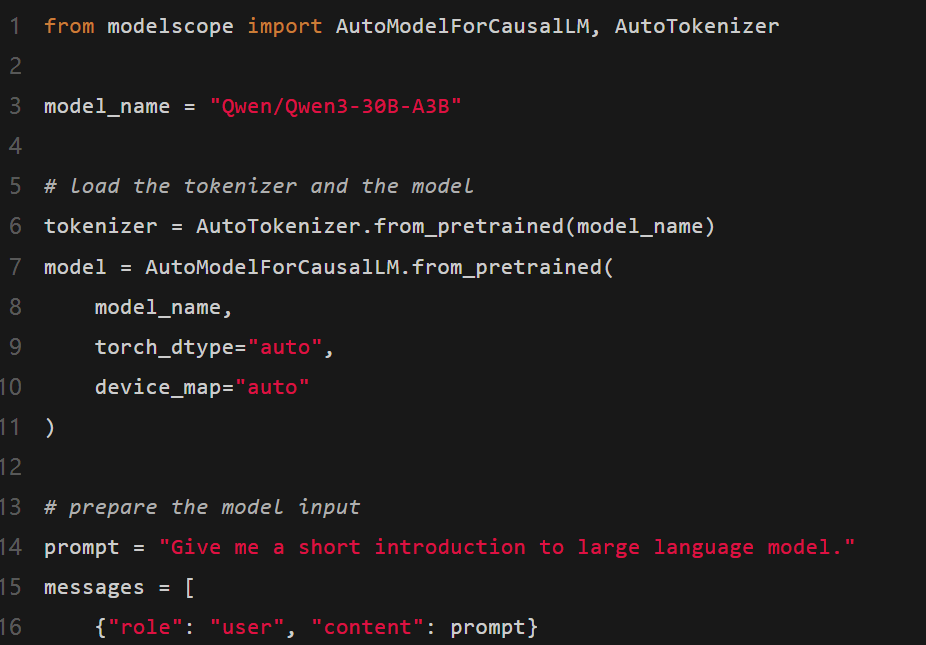
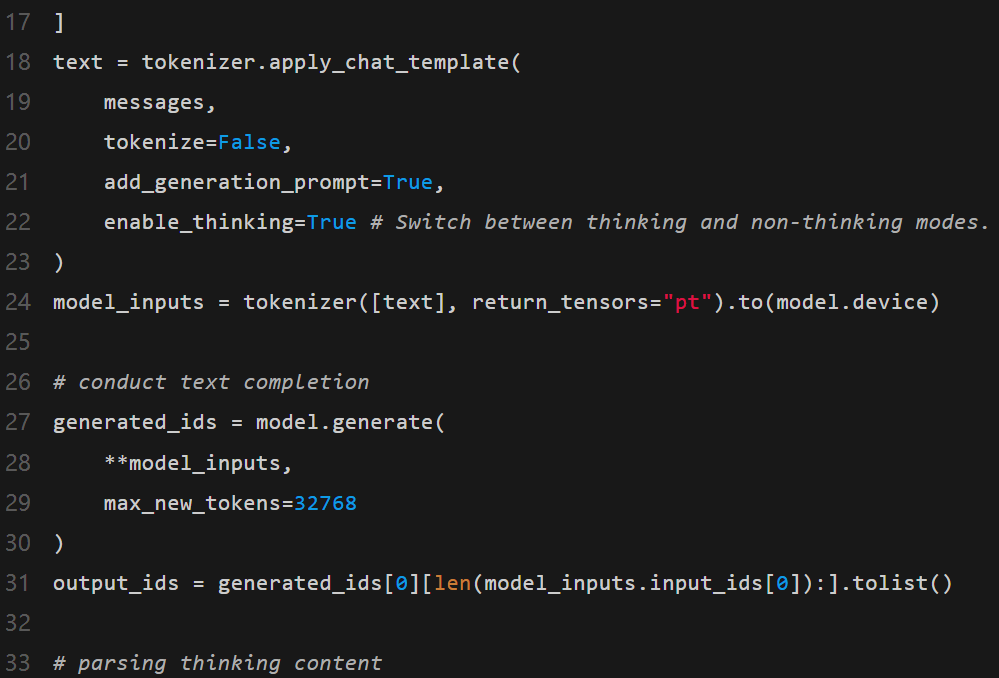
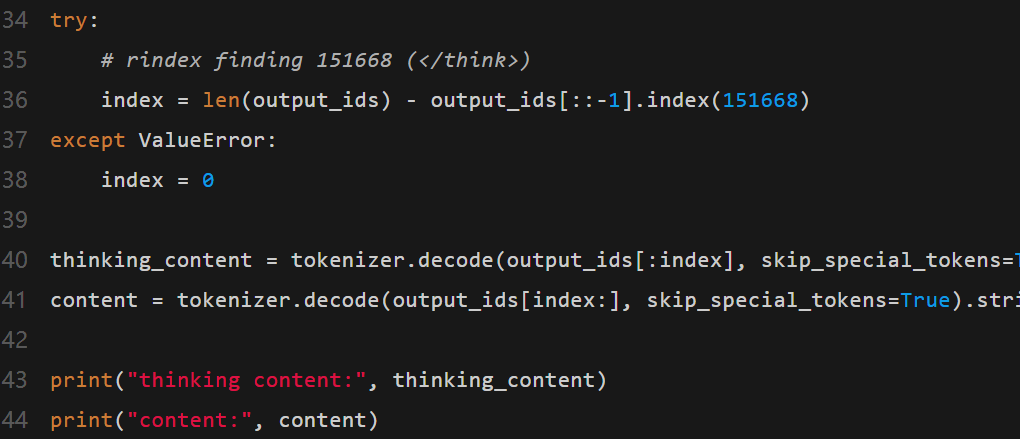
要關閉推理功能,只需更改參數enable_thinking,如下所示:

- 對於部署,可以使用sglang>=0.4.6.post1或vllm>=0.8.4建立與OpenAI相容的API端點:
SGLang:
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3vLLM:
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1如果將其用於本地開發,則可以通過運行簡單的命令ollama run qwen3:30b-a3b來使用ollama運行模型,或者,也可使用LMStudio、llama.cpp和ktransformers在本地進行建構。
高級用法
團隊提供了一種軟切換機制,當enable_thinking=True時,使用者可以通過該機制動態控制模型的行為。
具體來說,可以將/think和/no_think加入到使用者提示或系統消息中,以逐輪切換模型的思考模式。該模型將遵循多輪對話中最近的指令。
下面就是一個多輪對話的示例:
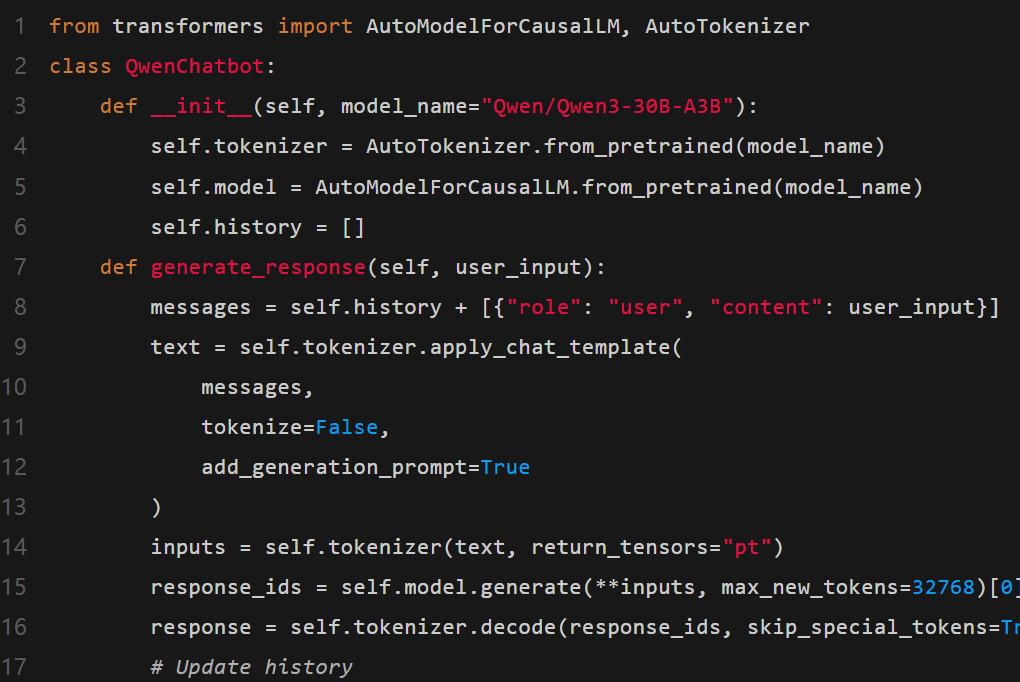
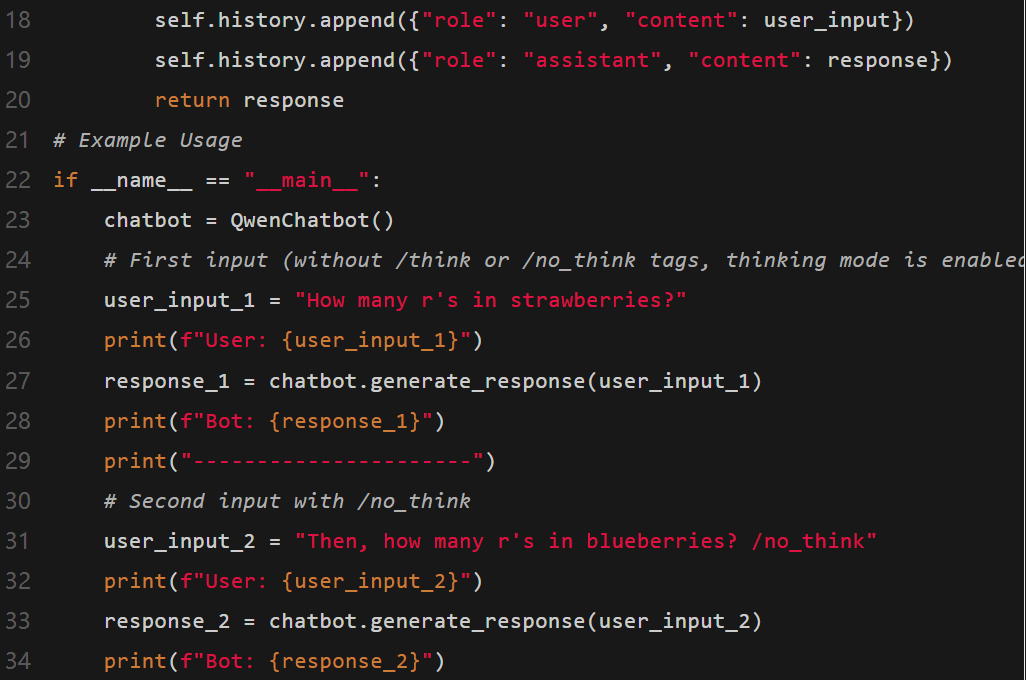

智能體功能的使用
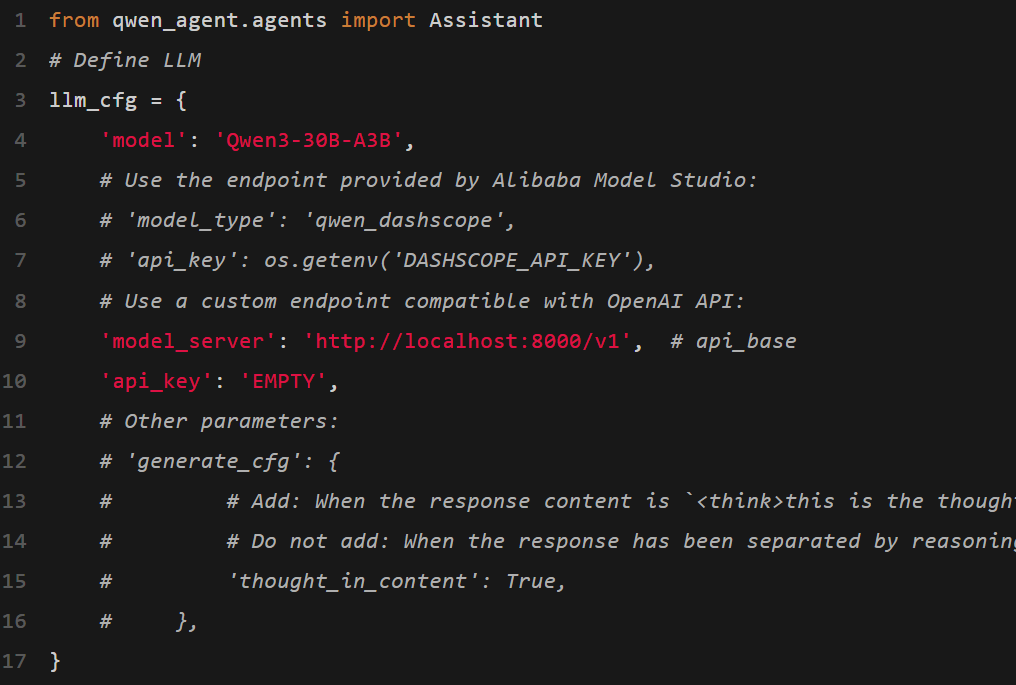
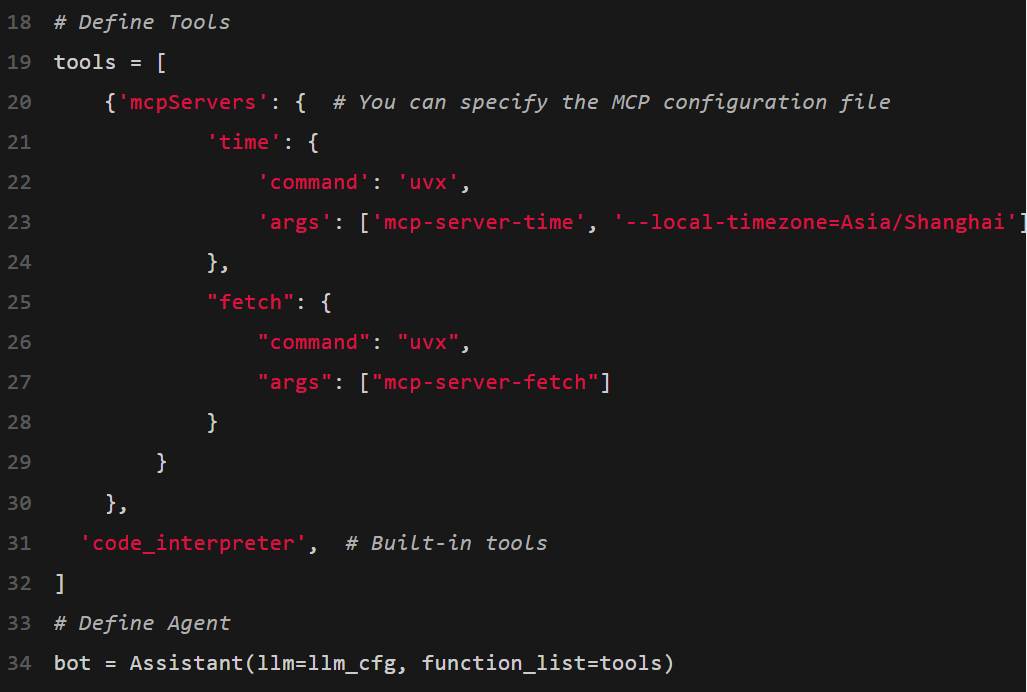
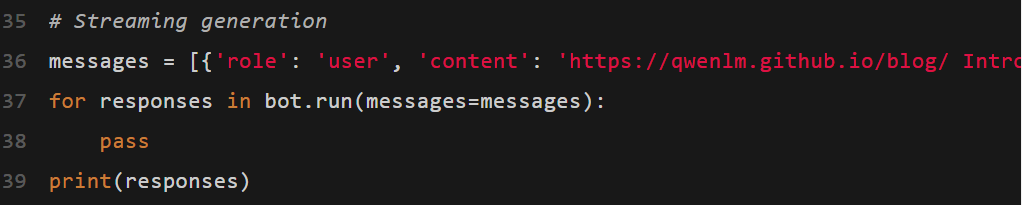
Qwen3在工具呼叫方面的表現非常出色。
團隊建議開發者使用Qwen-Agent,來充分利用Qwen3的智能體功能。
Qwen-Agent在內部整合了工具呼叫範本和解析器,從而大大降低了編碼的複雜程度。
要定義可用的工具,可以使用MCP組態檔案,使用Qwen-Agent的整合工具,或者自己整合其他工具。
(新智元)