
Google的Gemini 2.5 Pro在視訊理解領域又有了重磅進展,現在可以一口氣處理長達6小時影片了!
首先,硬實力槓槓的! Gemini 2.5 Pro 在十幾個學術視訊基準測試中取得了新的SOTA(業界最佳)成績,而且是在零樣本或少樣本訓練的情況下,直接叫板那些經過精細調優的專業模型。例如在YouCook2密集字幕生成和QVHighlights高光時刻檢索這類高難度任務上,表現都相當驚艷
Gemini 2.5首次實現了原生多模態模型能夠將音訊視訊資訊與程式碼等其他資料格式無縫結合。不是簡單地「看懂」視頻,而是能基於視頻內容進行更深層的理解和創造。
Gemini 2.5不僅在傳統影片分析上表現卓越,還解鎖了許多我幾個月前想都不敢想的新玩法,下面幾個例子,感受一下Gemini 2.5的視頻理解能力
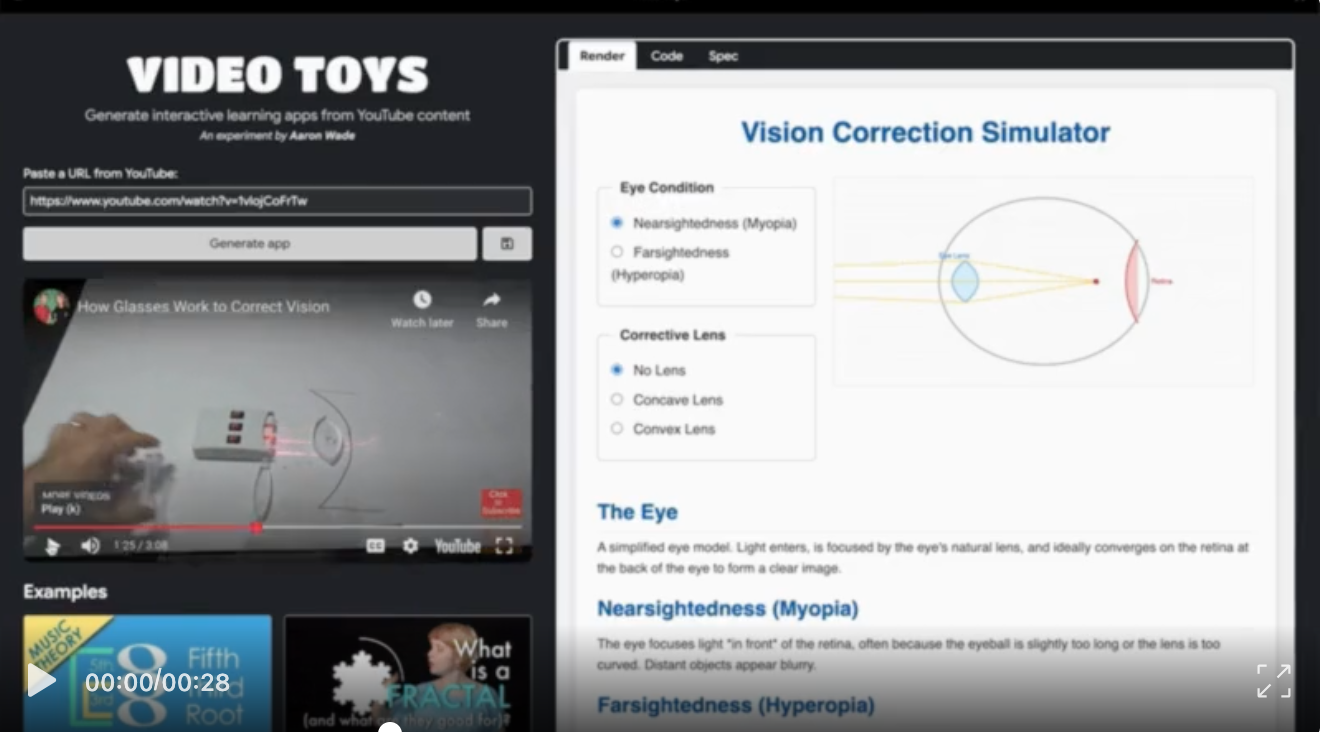
直接把影片變身網頁互動應用
怎麼玩? 給Gemini 2.5 Pro一個YouTube影片連結和一段文字提示(例如告訴它如何分析影片)。模型會先分析視頻,產生一個詳細的“學習應用規格說明書”,提煉視頻中的關鍵點
然後呢? 這份規格說明書再餵給Gemini 2.5 Pro,它就能直接產生這個學習應用的程式碼!
實例: 看影片實現「視力矯正模擬器」應用
影片一鍵產生p5.js動畫
想幹嘛? 想要快速產生影片的動態摘要,或是進行自動化內容創作?
Gemini 2.5 Pro: 只需一個提示,就能從影片中產生動態動畫,並保持與原始影片相同的時間順序
實例:輸入一段倫敦地標遊覽影片(油管連結:https://youtube.com/watch?v=hIIlJt8JERI),Gemini就能產生p5.js程式碼,輸出一個動態動畫效果

精準檢索與描述影片片段
痛點: 從長影片找特定片段太費力?
Gemini 2.5 Pro: 利用音視覺線索,辨識精準度遠超過過去。例如,在一個10分鐘的Google Cloud Next '25開幕演講影片中,它能準確識別出16個與產品演示相關的不同片段,並給出帶有時間戳的描述

強大的時序推理能力(計數):
挑戰: 不僅要看懂,還要理解時間序列上的微妙關係,例如計數
Gemini 2.5 Pro: 例如它成功找出了主角使用手機的17個不同場景。這對於理解影片中的行為和模式至關重要

最後,還有一個重磅實用更新:低媒體解析度(low media resolution)功能正式上線!
這個功能現在已經登陸Gemini API,很快也會在AI Studio和Vertex AI上線
它的牛X之處在於,能在性能損失極小的情況下,將每幀影片的視覺token從258個銳減到66個!這意味著什麼?在200萬token的限制下,以前能處理2小時的視頻,現在能處理長達6小時!處理效率大幅提升,成本也下來了!
注意:Gemini 2.5 Pro & Flash視訊理解都很強 (AI寒武紀)