
在閱讀本篇文章之前,建議先閱讀半導體晶片系列的往期文章,這樣知識會有一個連貫性:
2.電晶體工作原理
4.記憶體的構成原理
5.暫存器的組成原理
之前我們已經聊了電晶體到CPU的結構、製程工藝和工作原理。那麼今天,我們來聊聊另一個與之密切相關的重要硬體——GPU(圖形處理單元)。
1.GPU的誕生:為何而生?
如果說CPU是電腦的“大腦”,善於處理各種通用型計算任務,但在面對大規模平行計算時,CPU 就有點力不從心了。尤其是在圖形渲染、遊戲畫面處理、人工智慧訓練等場景中,需要處理成千上萬的像素、頂點和矩陣運算,CPU 的序列處理方式明顯效率不夠。
於是,GPU 應運而生。最早的 GPU 被設計用於圖形渲染,一說到圖形渲染,聰明的你一定會想到顯示卡,沒錯,GPU就是顯示卡的核心元器件,關於顯示卡,我們後續再說。GPU的目標就是通過成百上千個小而高效的運算單元,實現對圖像的快速平行處理。
2.GPU製造流程簡述
2.1 前言
之前我們在晶片製造過程那篇,詳細講了晶片的製造過程, GPU就是晶片的一種,跟CPU只是設計架構不同而已,製造過程類似。
先解釋一下常說的3奈米、5奈米、7奈米晶片到底是什麼意思。早期製程節點(如90nm以上時代),直接對應PN接面晶體管柵極物理長度,如上圖所示,但隨技術發展,節點命名逐漸轉為等效工藝密度描述,不單是一個柵極物理指標了,而是一種行銷術語,是因為所有工藝的改進,柵極漏極源極這些整體尺寸的變小,在同樣大小的晶片上可以塞下更多的電晶體,在數量上相當於柵極變成之前尺寸的3奈米了,實際上,現在3奈米晶片的晶片,柵極的長度在12-14nm之間,5奈米晶片的柵極長度在21-24nm之間。
如果對PN接面電晶體不瞭解的朋友,建議先看這兩篇文章:
2.2下面我們簡要說一下GPU晶片的製造過程:
Step 1:電路設計與驗證
GPU的架構極為複雜,通常包含數千個計算核心(CUDA Core、Stream Processor 等),需要大量EDA工具完成邏輯設計、版圖佈局(Layout)、驗證等工作。
Step 2:光掩模製備
設計完成後生成“光掩模”(Mask),用於光刻。7nm以上的GPU使用DUV(深紫外光刻),而3nm/5nm等級的新一代GPU則採用EUV(極紫外)光刻。
Step 3:晶圓製造
使用300mm高純度矽晶圓,通過以下步驟完成數十層電路疊加:
光刻(Photolithography)
- 刻蝕(Etching)
- 材料沉積(Deposition)
- 離子注入(Doping)
- 金屬互聯(Metallization)
GPU電晶體多、面積大(動輒500~800 mm²),良率控制更為困難,導致生產成本極高。
Step 4:切割與封裝(Die Packaging)
製造完成的晶圓被切割成一個個獨立的GPU裸芯(Die),然後進行封裝。高端GPU常採用多晶片封裝(MCM)或Chiplet架構,通過TSV(矽通孔)或EMIB(嵌入式多晶片互聯橋)進行互聯。
Step 5:測試與驗證
封裝完成後需進行多輪測試,包括:
功能測試(確保每個核心能正常運算)
- 功耗測試(是否在熱功率設計範圍內)
- 頻率測試(是否能穩定運行在標稱頻率)
- 良率篩選(決定是旗艦型號還是次級型號)
2.3 晶片巨獸的成長之路:GPU中的摩爾定律
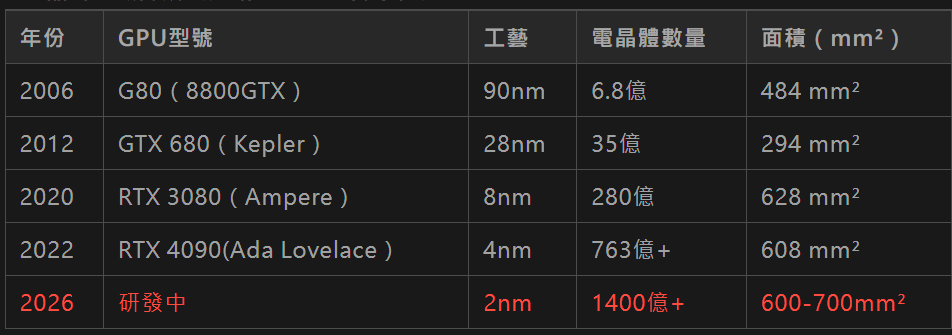
近年來,人們常說摩爾定律“失效”了,原因包括:
1.物理極限逼近:電晶體尺寸接近原子級,繼續縮小越來越難。
2.成本急劇上升:先進製程如 3nm 的製造成本是天價。
3.散熱與功耗問題嚴重:電晶體太密,功耗暴漲,難以控制溫度。
所以今天的摩爾定律,不再是“1.5年翻一番”,而可能是 3~4 年才有較大的提升。
3.GPU的工作原理
3.1 GPU為什麼快?
高計算並行:與CPU相比,GPU將更大比例的晶片面積分配給流處理器(如NVIDIA的CUDA核心),相應地減少控制邏輯(control logic)所佔的面積,從而在高平行負載下獲得更高的單位面積性能。
低記憶體延遲:記憶體訪問導致的延遲也是影響性能的一大因素,GPU通過在其每個核心上運行大量執行緒的方式,來應對並掩蓋因全域記憶體訪問導致的延遲。這種設計使得GPU即使在面臨較慢的記憶體訪問時,也能維持高效的計算性能。具體來說,每個SIMT核心同時管理多組執行緒(多個warp,一個warp 32個執行緒),當某個warp因為等待記憶體資料而暫停時,GPU可以迅速切換到另一個warp繼續執行。這種快速切換使得GPU能夠在等待記憶體資料返回的同時,保持高利用率,從而有效地“隱藏”了記憶體訪問延遲。
特化記憶體與計算架構:GPU通常配備高頻寬的視訊記憶體(如GDDR6或HBM),能夠快速讀取和寫入資料。如NVIDIA A100使用HBM2e視訊記憶體最高可達到1.6TB/s頻寬,是普通DDR5記憶體(51.2GB/s)的31倍。計算架構方面,GPU整合專用計算單元實現硬體級加速,例如,NVIDIA的Tensor核心針對結構化稀疏計算做專門設計,在低精度損失的情況下,可以極大地提升計算性能。
有多快?
理論算力計算:GPU算力常以FLOPS(Floating-Point Operations Per Second,每秒浮點運算次數)來表示,通常數量級為T(兆),也即是大家聽到的TFLOPS。最常見的計算方式為CUDA核心計演算法。
# CUDA核心計演算法
算力(FLOPS)= CUDA核心數 × 加速頻率 × 每核心單個周期浮點計算係數
# 以A100為例
A100的算力(FP32單精度)= 6912(6912個CUDA核心) × 1.41(1.41GHz頻率) × 2(單周期2個浮點計算) = 19491.84 GFLOPS ≈ 19.5 TFLOPS3.2 GPU的結構及工作原理
GPU(圖形處理器)最初是為圖像渲染而設計,但如今早已演化為通用的平行計算平台,廣泛應用於遊戲、AI、巨量資料、科學計算等領域,說到這裡,突然想到天氣預報,大家有沒有覺得現在天氣預報比小時候准了呢?沒錯,這就是晶片工藝的進步,製造出了更好的GPU,天氣預報其實是需要大規模的GPU去模擬的(全球大氣層需劃分成1公里級網格,單次模擬涉及10^15次(1000000000000000)運算),成本非常大,所以大家不要再罵天氣預報了,它們是用愛在發電。
如果說CPU像一個精明強幹的項目經理,那GPU就是一個擁有成百上千“螺絲釘工人”的大型流水線。來看一張對比圖:
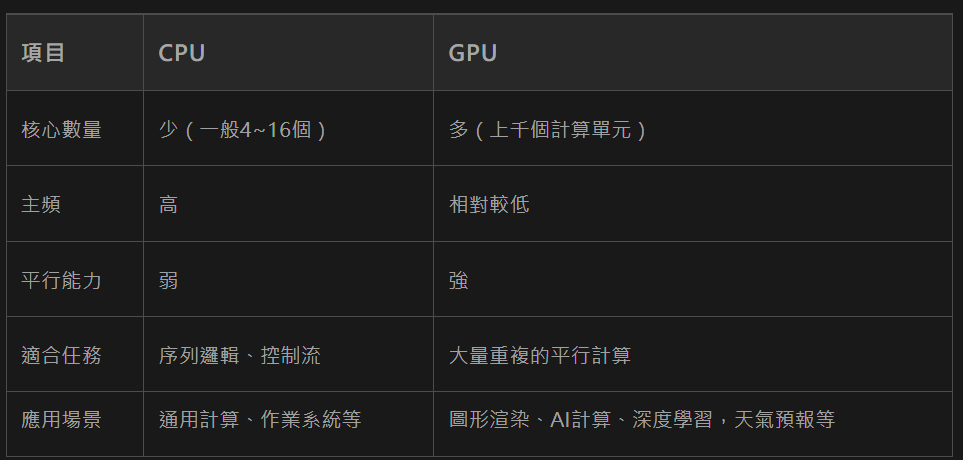
GPU核心結構主要包括:
流處理器(Streaming Processors / CUDA Cores)
GPU 的“螺絲釘工人”,負責執行浮點數運算、整數計算等基本指令,數量通常成百上千個。
- SM(Streaming Multiprocessor)流式多處理器
類似一個“小型CPU叢集”,每個SM下轄多個CUDA核心,負責調度和執行指令。 - 暫存器和共用記憶體
每個SM都有自己的高速暫存器和共用記憶體,用於執行緒之間的資料共享。 - 視訊記憶體(VRAM)
儲存紋理、頂點、模型參數等資料,相當於CPU的記憶體。 - 圖形渲染專用單元
包括紋理單元、光柵化引擎、像素著色器等,專門服務於圖形渲染任務。
GPU的工作方式:高度平行計算
1. 平行計算模型
GPU採用SIMT(Single Instruction, Multiple Threads)架構,也就是多個執行緒執行同一個指令,只是操作的資料不同。這就像是一群工人在同時擰不同位置的螺絲,效率極高。
在CUDA中(NVIDIA 的通用計算平台),你可以將任務切成若幹個“執行緒塊”(Thread Block),每個塊分配到一個SM中,每個SM再調度執行這些執行緒。整個過程高度自動化,極大地提升了平行效率。
2. 圖形渲染流程
在圖形渲染中,GPU大致遵循以下流程:
頂點處理:將3D物體的頂點坐標投影到2D螢幕坐標。
圖元裝配與光柵化:將幾何圖形轉化為像素。
像素著色:根據光照、材質等資訊決定像素顏色。
幀緩衝輸出:最終圖像輸出到螢幕。
這整個過程對浮點運算要求極高,恰好是GPU的強項。
GPU的架構
如上如所示:CPU與GPU的架構圖,可以看到CPU的架構運算單元少,GPU的架構運算單元非常多,而且快取單元、控制單元也被分的更小更多。
舉個例子再解釋一下,如下圖,有這樣一張一億像素的圖片需要渲染:
1. CPU處理方式
SIMD指令集(如AVX-512):單條指令同時處理多個像素(例如一次處理16個像素)
- 多核平行:現代CPU通常有4-32個核心,可分割任務到多個核心
CPU以順序執行為主,但會通過以下方式最佳化:
- 例如:若使用16核CPU + AVX-512(16個像素/指令),處理1億像素的理論最低周期數為:
2. GPU處理方式
例如A100 GPU有6912個CUDA核心,但實際平行度更高(通過執行緒級平行)
- GPU採用 SIMT(單指令多執行緒) 模式,每個核心可同時管理多個執行緒(類似分時復用)
- 實際執行流程:
執行緒組織:將1億像素劃分為 執行緒塊(如每塊256執行緒)
硬體調度:即便物理核心只有6912個,GPU通過 Warp調度器 動態分配執行緒塊到流多處理器(SM)
- 執行效率:每個SM可同時處理多個Warp(32執行緒為一組),通過隱藏記憶體延遲實現高吞吐
- 時間估算舉例:
假設A100的每個SM每周期完成1個Warp(32執行緒):
實際受記憶體頻寬限制(A100視訊記憶體頻寬1.6TB/s,處理1億像素需約0.25毫秒)
看到了嗎,CPU需要序列39萬次,而GPU只需要序列72次,這就是GPU的優勢。
4.總結:GPU 與 CPU,誰更強?
實際上,GPU 並不是用來“取代” CPU 的,而是用來“協同”工作的。在未來的計算架構中,CPU 繼續負責任務調度、邏輯控制,GPU 負責高吞吐的資料處理,二者缺一不可。
正如 CPU 是大腦,GPU 就是“肌肉”,在面對圖像處理、AI 模型訓練、科學模擬等“體力活”時,GPU 是不可或缺的生產力工具。 (碼農不禿頭)