DeepSeek R1新版本,幻覺驟降50%
中國國產大模型DeepSeek R1-0528悄悄完成重大升級,核心突破在於幻覺率大幅降低45%-50%。在改寫潤飾、摘要產生、閱讀理解等場景中,新版R1的準確度顯著提升,提供使用者更可靠的輸出。
此次升級並非簡單“打補丁”,而是基於深度思考能力強化的後訓練優化。模型在數學、程式設計等複雜任務中表現特別亮眼:在權威數學測驗AIME 2025中,準確率從舊版的70%飆升至87.5%,解題過程平均消耗token量從12K增至23K,說明其思考深度與邏輯嚴謹性顯著增強。
更令人驚訝的是,新版R1展現了技術普惠的野心:透過蒸餾自身思維鏈訓練出的8B小模型(DeepSeek-R1-0528-Qwen3-8B),在AIME 2024測試中性能直逼Qwen3-235B大模型,為工業界輕量化部署提供新可能。
寫作能力也同步升級。針對議論文、小說等文體,R1可生成結構更完整、文風更貼近人類的長篇內容,同時支援JSON輸出與工具調用(如網頁總結、代碼生成),實用性大幅提升。
目前大模型競爭已進入「可靠性攻堅戰」階段。使用者對幻覺的容忍度持續走低,尤其在學術、商業等嚴肅場景。先前SuperCLUE評量顯示,中文推理模型的平均幻覺率高達22.95%(非推理模型為13.52%),而舊版R1的幻覺率約21%。
DeepSeek R1的幻覺問題曾經是其最大軟肋。 2025年初的測試顯示,其幻覺率(14.3%)顯著高於前代V3模型(3.9%),根源在於強化推理與創造力的副作用:
任務錯配:長思維鏈設計本為提升複雜問題解決能力,卻導致簡單任務(如摘要)被過度複雜化,滋生虛構內容;
獎勵機制偏差:文科類任務訓練中,系統更偏好創造性輸出,弱化了事實查核。
此次升級透過定向優化後訓練流程,在保留強推理能力的同時,對事實性任務施加約束,實現「創造力」與「真實性」的再平衡。
橫向對比全球頂尖模型,新版R1展現出差異化競爭力:
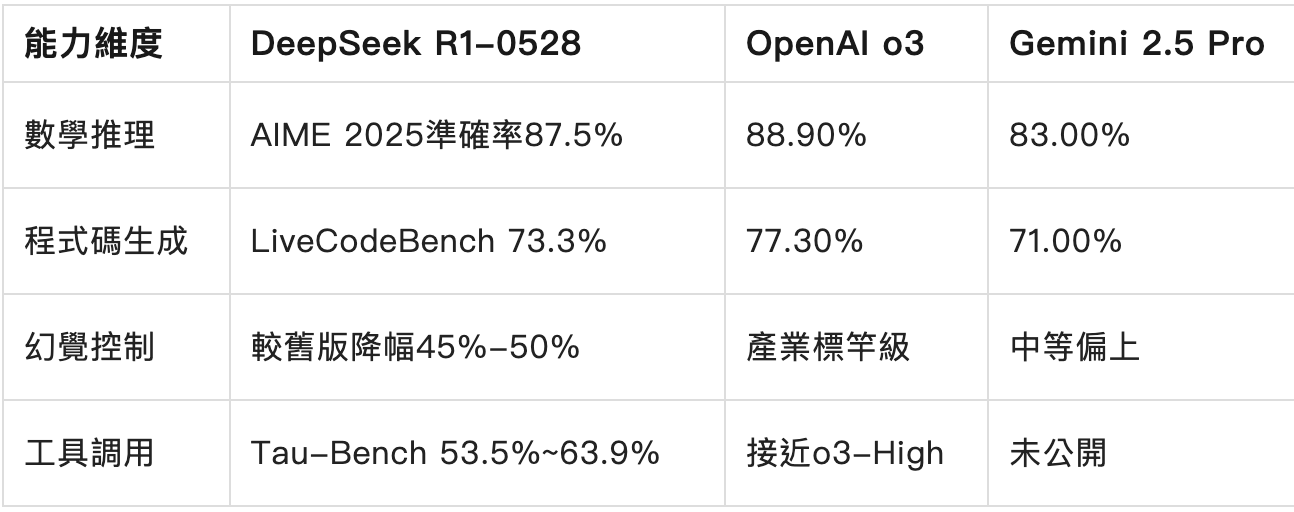
可見,R1在數學與程式碼領域已逼近o3,幻覺控制躍居國產模型首位,但工具呼叫能力仍落後頂尖閉源模型。
DeepSeek R1-0528的升級,不僅是技術參數的提升,更是國產大模型從「能用」到「可靠」的關鍵轉折。幻覺率驟降50%的背後,是團隊對使用者痛點的精準洞察與複雜技術矛盾的巧妙平衡。儘管在工具調用等場景仍需追趕國際頂尖水平,但其在推理深度、事實性保障上的突破,已讓開源模型首次具備與閉源巨頭「掰手腕」的底氣。
大模型的競爭終將回歸價值本質——誰更能為用戶提供穩定、可信賴的智慧服務,誰就能贏得未來。而DeepSeek這次「低調卻硬核」的進化,無疑為這場持久戰注入了新的變數。 (智創獅)