
在人工智慧浪潮席捲全球的當下,專用計算硬體已成為定義勝負的關鍵戰場。Google 的 Tensor Processing Unit(TPU)作為AI領域的標誌性ASIC(Application-Specific Integrated Circuit),以其脈動陣列架構和極致能效,深刻影響著從模型訓練到即時推理的全流程。
最近隨著第七代TPU Ironwood的正式發佈,Google挑戰了輝達的GPU霸權, 在中國A股市場,這一波“Google鏈”熱潮已然點燃,光庫科技、德科立、騰景科技等概念股應聲暴漲,對應出本土企業深度嵌入AI基礎設施的潛力。
一、TPU的起源與全球影響:從Google內部工具到生態引擎
TPU的誕生可追溯至2013年Google對AI計算瓶頸的深刻洞察。當時,RankBrain和Google Photos等項目面臨海量矩陣運算的挑戰,傳統CPU/GPU的馮·諾依曼架構難以滿足低延遲、高吞吐的需求。 僅用15個月,Google團隊便推出第一代TPU(v1),於2015年內部部署。這不僅是硬體創新,更是資料流計算範式的復興,借鑑了上世紀80年代的脈動陣列(systolic array)思想。
從v1的整數推理專用,到2025年v7 Ironwood的4.7倍性能躍升(峰值4614 TFLOPS),TPU已迭代七代。 其全球影響力體現在:AlphaGo的蒙特卡洛樹搜尋、Gemini 3的訓練均依賴TPU Pod超大規模叢集。 2025年11月,Google與Meta的TPU合作傳聞進一步放大其效應,Meta擬部署百萬級TPU晶片,挑戰輝達供應鏈。 這波“偷家”行動,不僅推升Google股價破300美元,還波及A股“Google鏈”類股。
在中國語境下,TPU的興起加速了本土AI硬體自主化。A股公司如寒武紀,其思元系列NPU(Neural Processing Unit)在架構上與TPU高度相似,均採用脈動陣列最佳化矩陣乘法。 同時,光庫科技作為GoogleOCS(Optical Circuit Switching)交換機核心代工廠,份額超70%,直接受益TPU Pod的互聯升級。 2025年Q3,光庫科技訂單激增30%,市值一度翻番,也成為從被動供應鏈到主動創新的雙重角色。
二、TPU核心架構剖析:脈動陣列與資料流革命
TPU的魅力在於其“為AI而生”的設計,無法運行通用任務,卻在神經網路負載上碾壓對手。 核心是TensorCore,包括矩陣乘法單元(MXU)、向量/標量單元,以及高頻寬記憶體(HBM)整合。這些元件協同,實現從資料注入到結果輸出的無縫流水線。
2.1 MXU:脈動陣列的計算心臟
MXU是TPU的靈魂,採用256x256(v7)脈動陣列,每周期執行海量乘累加(MAC)操作。 資料如心跳般“脈動”流動:權重從HBM載入,啟動值逐行注入,避免傳統架構的記憶體瓶頸。v7支援FP8精度,峰值吞吐達4614 TFLOPS,頻寬7.37 TB/s。
對比A股寒武紀,其MLU系列NPU同樣嵌入脈動陣列,支援BF16/INT8混合精度,適用於雲端訓練。 2025年,寒武紀發佈MLU290,性能逼近TPU v6,訂單覆蓋阿里雲和華為鯤鵬生態,年營收增長45%。 這表明,中國ASIC設計已從模仿到平行,填補TPU在本土部署的空白。
2.2 輔助單元與互聯:高效擴展的基石
向量單元處理啟動函數(如GELU),標量單元管理控制流。 TPU的infeed/outfeed佇列實現主機-加速器零複製傳輸,延遲低至微秒級。互聯方面,ICI(Inter-Chip Interconnect)支援9216晶片Pod,採用3D立方拓撲。
在A股,德科立專注光互聯模組,供應GoogleOCS整機核心,助力TPU Pod的低功耗擴展。 2025年11月Meta合作消息後,德科立股價大漲,Q3淨利潤預增60%。 類似地,天孚通訊提供矽光子晶片,最佳化TPU的頻寬瓶頸,與TPU v7的7nm工藝高度契合。
2.3 與本土架構的異同:啟發與差距
TPU的確定性執行(無快取亂序)確保99%尾延遲穩定,功耗僅為GPU的1/3。 A股芯原股份作為ASIC設計服務商,助力企業定製類似TPU的加速器。 其VeriSilicon平台支援脈動陣列IP,2025年AI訂單佔比90%,營收同比增85%。 然而,國內公司仍面臨生態壁壘:TPU深度繫結TensorFlow,而寒武紀的Cambricon CNDK更相容國產框架。
三、TPU世代演進:技術躍遷與中國鏡像
TPU七代迭代體現了工藝縮小、精度提升與規模擴展的邏輯,每代均針對AI痛點最佳化。
3.1 v1-v3:奠基與浮點轉型
v1(28nm,92 TOPS)專注8位整數推理。 v2(16nm,45 TFLOPS)引入BF16訓練,Pod達180 TFLOPS。 v3(123 TFLOPS)最佳化液冷,1024晶片Pod。
同期,中國企業起步:曙光資訊推出“星雲”伺服器,整合國產NPU,模擬TPU Pod。
3.2 v4-v5:7nm革命與效率焦點
v4(7nm,275 TFLOPS)Pod 4096晶片。 v5e/v5p(197/459 TFLOPS)強調推理/高記憶體。
A股工業富聯作為富士康子公司,代工TPU伺服器,2025年AI產能擴至30%。 其訂單受益v5稀疏核心,淨利潤預增25%。
3.3 v6-v7:Trillium與Ironwood巔峰
v6e(918 TFLOPS)4.7倍v5e。 v7(4614 TFLOPS,FP8)定義2025標準。
騰景科技專注PCB,供應TPU封裝,11月連續漲停。 寒武紀則推出“雲端智算一體機”,性能對標v6,助力“東數西算”。
性能對比表(含本土鏡像):
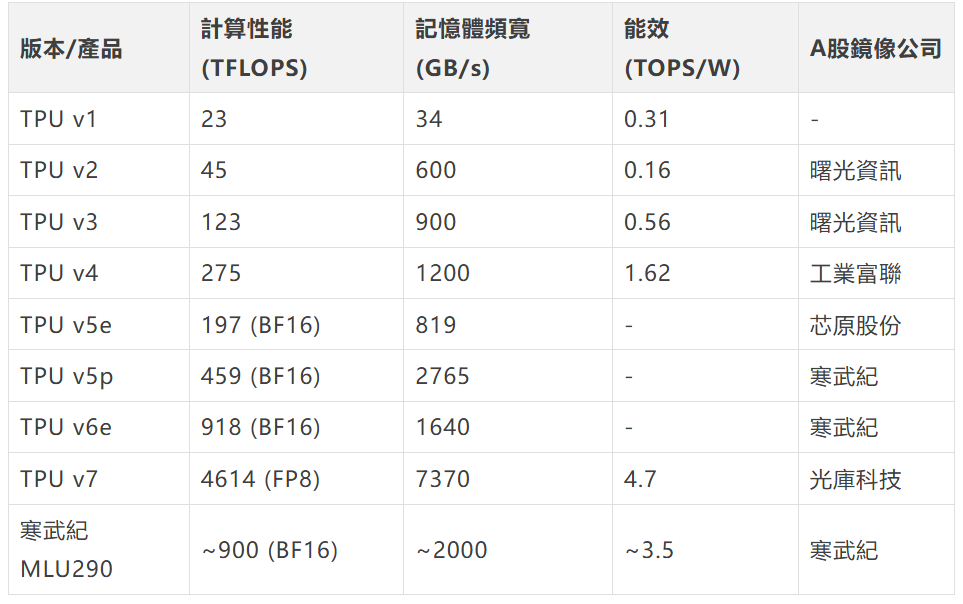
從表可見,A股產品性能追趕迅猛,但規模化仍需時日。
四、性能實測與本土應用:TPU vs. A股加速器
v1在CNN/LSTM上快GPU 15-30倍,能效80倍。 v7在Gemini 3訓練中,吞吐提升4倍。
寒武紀NPU在阿里“通義千問”推理中,延遲低20%,成本降30%。 芯原的ASIC服務助力中小企定製TPU-like晶片,2025訂單12億。 侷限:TPU生態封閉,A股需強化XLA相容。
五、相關公司案例:Google鏈與自主創新雙軌
5.1 供應鏈受益者:光通訊與封裝
光庫科技:OCS代工70%,TPU Pod互聯關鍵,2025市值翻倍。
德科立:整機供應,Q3淨利增60%。
勝宏科技:高多層PCB,TPU伺服器板卡。
5.2 自主加速器先鋒:寒武紀與芯原
寒武紀:NPU架構仿TPU,MLU雲平台支援萬卡叢集,營收45%增長。
芯原股份:IP授權費99% QoQ,AI ASIC訂單主導。
5.3 伺服器整合:曙光與富聯
曙光資訊:國產伺服器整合NPU,模擬TPU Pod。
工業富聯:TPU代工,AI產能30%。
這些公司2025年集體市值增超500億,ETF如159363漲3.45%。
六、TPU vs. 競爭:全球格局與中國突圍
TPU不僅是架構,更是AI民主化的催化劑。其在能效上勝GPU,但靈活性遜色。 A股寒武紀填補國產空白,芯原橋接自研。v8或破10 PFLOPS,融入光子計算,從鏈條末端向核心進軍,寒武紀等或領跑“TPU中國版”。
希望相關公司借勢而上,助力中國智算強國夢。 (Visionary Future Keys)