
DeepSeek又發論文了。
這次的主題有點意思:他們發現,現在的大模型在浪費大量算力做一件很傻的事——用計算來模擬查字典。
論文叫《Conditional Memory via Scalable Lookup》,核心是一個叫Engram的模組。
這個名字有點意思。Engram是神經科學術語,最早由德國生物學家Richard Semon在1904年提出,指的是大腦中儲存記憶痕跡的物理結構——當你記住"巴黎是法國首都"這個事即時,這條資訊就以某種物理形式(可能是特定的神經連接模式)儲存在你的大腦裡,這個物理痕跡就叫engram。
DeepSeek用這個名字,顯然是想說:我們要給大模型裝上真正的"記憶"。
說實話,看完之後我挺興奮的——這篇論文的思路非常優雅,而且解決的是一個很根本的問題。更重要的是,它觸及了一個認知科學的經典命題:記憶和思考是什麼關係?
先說問題:大模型在浪費算力做"背書"
你有沒有想過,當大模型看到"Diana, Princess of Wales"(戴安娜王妃)這個詞的時候,它內部發生了什麼?
DeepSeek在論文裡引用了一個很有意思的研究(PatchScope):模型需要消耗多層Attention和FFN,才能逐步把這個實體識別出來。
具體來說,模型處理"Wales"這個詞時的內部狀態演變:

看到沒?模型用了6層計算,才把一個固定的歷史人物識別出來。
問題在於:這個資訊是靜態的、固定的,根本不需要每次都"計算"出來。
"亞歷山大大帝"就是"亞歷山大大帝","四大發明"就是"四大發明","張仲景"就是"張仲景"。這些固定搭配、命名實體、慣用表達,每次都用神經網路重新計算一遍,是不是有點傻?
這就像你每次需要查"中國首都是那"的時候,不是直接查字典,而是從頭推理一遍——中國是個國家,國家有首都,中國的政治中心在...
DeepSeek的核心觀點是:大模型浪費了大量的"網路深度"在做這種重複性的靜態知識重建。這些算力本來可以用來做更有價值的事——比如推理。
Engram的核心思想:給模型發一本字典
想像你在考試。
以前的規則是:什麼都不能帶,全靠腦子現場推。"亞歷山大大帝是誰?"你得從頭想——亞歷山大,希臘名字,大帝說明是君主,歷史上有名的希臘君主...
現在新規則:允許帶一本字典進考場。字典裡寫著"亞歷山大大帝 = 馬其頓國王,公元前356-323年,征服了波斯帝國"。你直接翻到這一頁,抄上去,省下來的時間做後面的推理題。
Engram就是這本字典。
具體怎麼查?很簡單:
模型看到"Alexander the Great"這三個詞連在一起,就像看到字典的索引詞條。它用一個很快的方法(雜湊)定位到字典裡對應的那一頁,直接把預先存好的資訊拿出來用。
整個過程不需要"思考",只需要"翻頁"。
但這裡有個問題:同一個詞在不同場合意思不一樣。
比如"蘋果",可能是水果,也可能是那家科技公司。字典裡存的是那個意思?
Engram的解決方案很聰明:查完字典之後,先看看上下文,再決定用不用。
如果前面在聊水果,字典裡查出來的"蘋果公司"就不太對勁,模型會自動忽略這個查表結果,繼續用自己的推理。如果前面在聊手機,那字典裡的資訊就很有用,直接採納。
這就像一個聰明的學生:帶了字典進考場,但不是無腦抄,而是先判斷字典裡的答案和題目對不對得上。
關鍵發現:U型縮放定律
這裡是論文最有意思的部分。
DeepSeek研究了一個問題:如果總參數量固定,應該把多少參數分配給MoE專家,多少分配給Engram記憶?
他們定義了一個"分配比例"ρ:
- ρ = 100% 表示純MoE(所有稀疏參數都給專家)
- ρ < 100% 表示把部分參數從專家轉移到Engram
實驗結果讓人驚訝:
驗證損失呈現U型分佈:
- 純MoE(ρ=100%)不是最優的
- 分配約20-25%給Engram(ρ≈75-80%)效果最好
- 把太多參數給Engram(ρ<50%)效果又變差
這個U型曲線說明了什麼?
MoE和Engram是互補的:
- MoE擅長動態的、需要上下文推理的任務
- Engram擅長靜態的、固定模式的識別
兩者缺一不可。純MoE缺少記憶能力,純Engram缺少推理能力。
插一段:博爾赫斯早就寫過這個
看到這個U型曲線的時候,我突然想起博爾赫斯的一個短篇:**《博聞強記的富內斯》**(Funes the Memorious)。
故事講的是一個叫富內斯的阿根廷青年,從馬上摔下來之後,獲得了"完美記憶"的能力——他能記住一切。每一片葉子的形狀,每一朵雲的變化,甚至能記住1882年4月30日黎明時分南方天空的雲綵排列。
但博爾赫斯寫道:富內斯無法思考。
"思考就是忘記差異,就是概括,就是抽象。在富內斯塞滿了東西的世界裡,只有細節,幾乎是直接感知的細節。"
富內斯能記住三個不同時刻看到的同一條狗,但他無法理解"狗"這個概念——因為每一條狗、每一個瞬間的狗,對他來說都是完全不同的東西。他記住了一切,卻失去了抽象的能力。
這不就是論文裡U型曲線的左端嗎?
當ρ趨近於0(全是Engram,沒有MoE)時,模型有無限的記憶,但失去了推理能力。它能記住"亞歷山大大帝"是誰,但無法用這些知識進行推理。
反過來,當ρ=100%(全是MoE,沒有Engram)時,模型有強大的推理能力,但要浪費大量算力重建那些本可以直接記住的東西。
博爾赫斯在1942年就洞察到了這一點:記憶和思考是互補的,但也是對立的。完美的記憶會殺死思考,而純粹的思考則需要不斷重新發明輪子。
最優解在中間——既有記憶,又有思考。
DeepSeek的實驗資料給出了一個驚人精確的答案:大約75-80%給思考,20-25%給記憶。
這讓我想到另一個認知心理學的經典概念:**組塊(Chunking)**。
1956年,心理學家George Miller發表了著名的論文《神奇的數字7±2》,指出人類工作記憶的容量是有限的,但我們可以通過"組塊"來擴展它。比如記電話號碼138-8888-6666,你不是記11個數字,而是記3個組塊。
N-gram本質上就是語言的組塊。"亞歷山大大帝"不是5個字,而是1個組塊。Engram做的事情,就是把這些組塊預先存好,省得每次都要重新計算。
人腦早就在這麼幹了。DeepSeek只是讓大模型學會了同樣的技巧。
實驗結果:推理能力提升比知識提升更大
這是讓我最驚訝的部分。
你可能會想:Engram是個"記憶模組",應該主要提升知識類任務吧?
確實,知識任務有提升:
- MMLU:+3.4
- CMMLU:+4.0
- MMLU-Pro:+1.8
但推理任務的提升更大:
- BBH:+5.0
- ARC-Challenge:+3.7
- DROP:+3.3
甚至程式碼和數學也有顯著提升:
- HumanEval:+3.0
- MATH:+2.4
- GSM8K:+2.2
等等,一個"記憶模組"為什麼能提升推理能力?
機制分析:為什麼"記憶模組"能提升推理?
這是我最想搞明白的問題。
DeepSeek做了一個很有意思的實驗:他們"偷看"模型每一層在想什麼。
具體方法是:把每一層的中間結果拿出來,問它"你現在覺得下一個詞是什麼?"。如果這一層已經很接近最終答案,說明模型在這一層就基本"想明白了"。
結果很直觀:
有Engram的模型,在很早的層就"想明白了";沒有Engram的模型,要到很深的層才行。
為什麼?
因為沒有字典的模型,前面幾層都在忙著做一件事:搞清楚"亞歷山大大帝"是誰。它得一層一層地拼湊——這是個人名,是個歷史人物,是個國王,是馬其頓的國王...
等它終於搞清楚這是誰了,已經用掉了5、6層。剩下的層才能開始真正的推理。
但有字典的模型不一樣。第2層的時候,Engram直接告訴它:"亞歷山大大帝 = 馬其頓國王,征服者"。好了,搞定,後面20多層全部用來推理。
這就像兩個學生做同一張卷子:
一個學生得先花20分鐘背公式,再用40分鐘做題。
另一個學生帶了公式表,60分鐘全用來做題。
誰的推理題做得更好?顯然是第二個。
DeepSeek還做了一個更精確的測量:Engram模型第5層的"思考深度",相當於普通模型第12層的水平。
換句話說,Engram相當於免費給模型加了7層深度。
這就解釋了為什麼推理能力提升這麼大——不是Engram本身能推理,而是它把推理的空間讓出來了。
長上下文能力也炸了
還有個意外收穫:處理長文章的能力暴漲。
有個測試叫"大海撈針"——在一篇很長的文章裡藏一句關鍵資訊,看模型能不能找到。
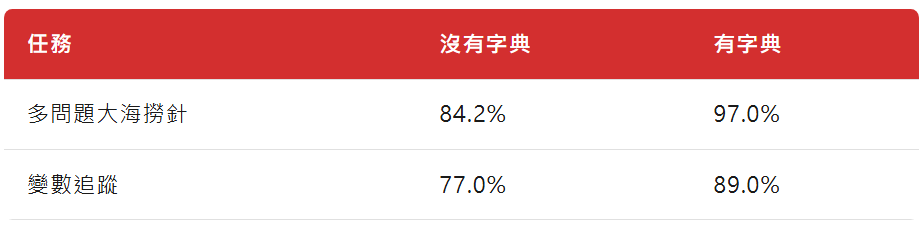
為什麼字典能幫助處理長文章?
想像你在讀一本很長的小說。如果你每次看到"福爾摩斯"都要停下來想"這是誰來著...",讀到後面肯定記不住前面的劇情。
但如果"福爾摩斯 = 偵探,住貝克街221B"這個資訊已經存在字典裡,你的注意力就可以全部用來追蹤劇情——誰殺了誰,線索在那,凶手是誰。
Engram處理了"這是誰"的問題,Attention就可以專注於"發生了什麼"的問題。
相當於給大腦減負了。
系統設計:字典可以放在抽屜裡
這裡體現了DeepSeek一貫的風格:理論創新和工程落地並重。
繼續用考試的比喻。
MoE(專家模型)的問題是:每道題都要"現場"決定找那個專家來答,這個決定本身就要花時間。
但字典不一樣。你看到"亞歷山大大帝",就知道要翻到A開頭那一頁。你不需要先讀完整道題,才知道去查那個詞條。
這意味著什麼?
意味著字典可以提前準備好。
模型還在處理第1層的時候,系統就已經知道第2層要查什麼詞條了。所以可以提前把那一頁準備好,等模型算到第2層的時候,字典已經翻開擺在那兒了。
更妙的是:字典不需要放在桌上,放在抽屜裡也行。
GPU視訊記憶體很貴,就像桌面空間有限。但CPU記憶體便宜得多,就像抽屜容量大得多。
既然可以提前知道要查什麼,那就提前從抽屜裡把那一頁拿出來,等用的時候已經在桌上了。
DeepSeek做了個實驗:把一本1000億參數的"字典"放在抽屜裡(CPU記憶體),結果:

只慢了2% ,但多了1000億參數的知識。
這就是為什麼Engram可以做得很大——字典放抽屜裡就行,不佔桌面。
門控可視化:確實在識別固定模式
論文最後有個很直觀的可視化:
紅色表示門控值高(Engram被啟動),白色表示門控值低(Engram被忽略)。
可以看到,門控在這些地方啟動:
- "Alexander the Great"(亞歷山大大帝)
- "the Milky Way"(銀河系)
- "Princess of Wales"(威爾士王妃)
- "四大發明"
- "張仲景"
- "傷寒雜病論"
全是命名實體和固定搭配。Engram確實在做它該做的事:識別靜態模式。
往大了說:DeepSeek在開一條新路
回到開頭的問題:這篇論文的意義是什麼?
過去幾年,大家都在一個方向上卷:怎麼讓模型算得更聰明。MoE讓不同的專家處理不同的問題,Attention讓模型看到更遠的上下文,更深的網路讓推理更複雜。
但不管怎麼卷,本質上都是在最佳化"計算"。
DeepSeek說:等等,有些問題根本不需要算,查一下就行了。
這個思路其實很符合直覺:人腦也不是什麼都靠推理,很多時候就是直接呼叫記憶。你看到"1+1"不需要推理,直接輸出"2"就行。
論文最後一句話很有意思:
"We envision conditional memory as an indispensable modeling primitive for next-generation sparse models."
翻譯過來:我們認為條件記憶會成為下一代稀疏模型的基礎元件。
DeepSeek在押注一個新的架構方向。
最後:記憶與思考的平衡
回到開頭的問題:記憶和思考是什麼關係?
博爾赫斯用富內斯告訴我們:完美的記憶會殺死思考。認知心理學告訴我們:人腦用組塊來平衡記憶和思考的負擔。
現在DeepSeek用實驗資料告訴我們:最優的比例大約是75%計算 + 25%記憶。
這個數字讓我覺得很有意思。它意味著,即使是"智能"系統,也不能全靠"聰明"——你得記住一些東西,才能把腦力用在更值得思考的地方。
這篇論文給我最大的啟發是:有時候最好的最佳化不是讓計算更快,而是把計算變成查表。
O(1)的查表永遠比O(n)的計算快。如果一個問題的答案是固定的、可以預先算好存起來的,那就沒必要每次都重新算。
這個道理在電腦科學裡叫"空間換時間"。但在大模型領域,過去幾年大家都在卷MoE、卷Attention、卷更深的網路,似乎忘了還有"記憶"這條路。
DeepSeek的Engram提醒我們:大模型不是越大越好、也不是越深越好,關鍵是把合適的任務分配給合適的模組。
靜態知識 → 查表(Engram)
動態推理 → 計算(MoE)
就像人腦一樣:你不需要每次看到"1+1"都重新推導,直接從記憶裡調出"2"就行了。省下來的腦力,用來思考更有價值的問題。
富內斯記住了一切,卻無法思考。
純MoE模型能夠思考,卻要浪費算力重建記憶。
最聰明的系統,是知道什麼該記住、什麼該思考的系統。 (花叔)