
Google DeepMind 發佈 D4RT,徹底顛覆了動態 4D 重建範式。它拋棄了複雜的傳統流水線,用一個統一的「時空查詢」介面,同時搞定全像素追蹤、深度估計與相機位姿。不僅精度屠榜,速度更比現有 SOTA 快出 300 倍。這是具身智能與自動駕駛以及 AR 的新基石,AI 終於能像人類一樣,即時看懂這個流動的世界。
如果是幾年前,你問一位電腦視覺工程師:「我想把這段視訊裡的所有東西——無論它是靜止的房子還是奔跑的狗——都在 3D 世界裡重建出來,並且還能隨時知道它們下一秒會去那兒,需要多久?」
他大概會遞給你一根菸,讓你先去買幾塊頂級顯示卡,然後給你畫一個由四五個不同模型拼湊起來的流程圖:先算光流,再算深度,再估相機位姿,最後還得用一晚上的時間去跑最佳化,祈禱結果別崩。
但Google DeepMind 剛剛發佈的 D4RT(Dynamic 4D Reconstruction and Tracking),試圖終結這種混亂。
這篇論文在電腦視覺領域扔下了一枚關於「效率革命」的重磅炸彈。
它把原本割裂的 3D 重建、相機追蹤、動態物體捕捉,統一成了一個極簡的「查詢」動作。
更重要的是,它的速度比現有 SOTA技術快了 18 到 300 倍。
如果在你的認知裡,高品質的 4D 重建還是好萊塢特效工作室裡那些昂貴且緩慢的渲染農場,耗費漫長的時間等待生成完畢,那麼 D4RT 正在把這種能力變成一種可以塞進機器人大腦甚至 AR 眼鏡裡的即時直覺。
Demo 演示
為了理解 D4RT 到底做到了什麼,我們需要先看一眼它眼中的世界。
在論文展示的演示中,最直觀的震撼來自於對「動態混亂」的駕馭能力。
想像一下這個畫面:一隻天鵝在水面上劃過,或者一朵花在風中快速綻放。
傳統的 3D 重建演算法(比如 MegaSaM 或 )處理這種場景通常是一場災難——因為它們假設世界是靜止的,所以它們往往會在 3D 空間裡留下一串「重影」,就像老式膠片重疊曝光一樣,天鵝變成了長著幾十個脖子的怪物,或者花朵直接變成了一團無法辨認的噪點。
但 D4RT 給出的結果極其乾淨。
它不僅可以精準還原天鵝的 3D 形態,還完美剝離了相機的運動和天鵝自身的運動。
在它的視野裡,時間變成了一個可以隨意拖動的滑塊。
更令人印象深刻的是它的全像素追蹤能力。
你可以點選視訊中花瓣上的任意一個像素,D4RT 就能畫出這個點在過去和未來的完整 3D 軌跡,那怕這個點在中間幾幀被蜜蜂遮擋了,或者跑到了畫面之外,模型依然能根據上下文「腦補」出它的去向。
這種視覺效果給人的感覺是:AI 不再是在一幀幀地「看」視訊,而是把整段視訊吞下去,在大腦裡生成了一個完整的、流動的全息全景圖,然後你可以隨意從任何角度、任何時間去檢視它。
拆解「神話」是真的快,還是文字遊戲?
科技公司發論文,資料通常都很漂亮。
作為觀察者,我們需要剝離 PR 濾鏡,看看資料背後的定語。
Google聲稱 D4RT 比之前的 SOTA 快了 300 倍,處理一分鐘的視訊只需要 5 秒鐘。
這是真的嗎?
答案是:在特定維度上,是真的。
這裡的「300倍」指的是吞吐量,具體來說是「在保持相同影格率(FPS)的前提下,模型能同時追蹤多少條 3D 軌跡」。
- 資料對比:在 24 FPS 的標準電影影格率下,之前的強者 SpatialTrackerV2 隻能同時追蹤 84條軌跡,再多就卡了;而 D4RT 可以輕鬆處理 1570條。如果是和 DELTA 這種更慢的模型比,那就是 314 倍的差距。
- 實際意義:這意味著之前的技術可能只能盯著畫面裡的主角(比如一個人),而 D4RT 可以同時盯著背景裡走動的路人、飄落的樹葉和遠處的車流——即所謂的「全像素級感知」。
它比同類技術強在那兒?
目前市面上的 4D 重建技術主要分兩派:
- 「拼裝派」(如 MegaSaM):把深度估計、光流、分割等多個現成模型串起來。雖然效果不錯,但不僅慢,而且一旦一個環節出錯(比如光流飄了),後面全完。
- 「多頭派」(如 VGGT):雖然是一個大模型,但為了輸出不同的任務(深度、位姿、點雲),需要掛載不同的解碼頭,結構臃腫。
D4RT 的牛,在於它做到了架構層面的統一。
它不需要為深度單獨做一個解碼器,也不需要為位姿單獨做一個。
它只用同一個介面解決所有問題。
有沒有代價?當然有。
D4RT 的「快」主要體現在推理階段。
在訓練階段,它依然是一個龐然大物。它的編碼器使用了 ViT-g,擁有 10 億參數,並且需要在 64 個 TPU 晶片上訓練兩天。
這絕不是普通開發者在自家車庫裡能復現的玩具,它是典型的「大廠重武器」。
技術解碼 把 4D 重建變成「搜尋引擎」
那麼,D4RT 到底是怎麼做到的?
論文的核心邏輯可以用一句話概括:先全域「閱讀」視訊,再按需「搜尋」答案。
不再逐幀解碼,而是「全域記憶」
傳統的視訊處理往往是線性的,處理第 10 幀時可能已經「忘」了第 1 幀的細節。
D4RT 的第一步是使用一個巨大的 Transformer 編碼器(Encoder),把整段視訊壓縮成一個全域場景表徵(Global Scene Representation, F)。
你可以把這個 F 想像成 AI 對這段視訊形成的「長期記憶」。
一旦這個記憶生成了,原本龐大的視訊資料就被濃縮在了這裡。
「那裡不會點那裡」的查詢機制
這是 D4RT 最天才的設計。它發明了一種通用的查詢(Query)語言。
當 AI 想要知道某個像素的資訊時,它會向解碼器(Decoder)傳送一個查詢 q:
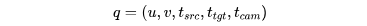
這個公式翻譯成人話就是:


平行計算的藝術
因為每一個查詢(Query)都是獨立的,D4RT 不需要像穿針引線一樣按順序計算。
它可以一次性扔出幾萬個問題,利用 GPU/TPU 的平行能力同時算出答案。
這就是為什麼它能比別人快 300 倍的根本原因:它把一個複雜的序列幾何問題,變成了一個大規模平行的搜尋問題。
關鍵的「作弊」技巧:9x9 Patch
論文作者還發現了一個有趣的細節:如果只告訴解碼器坐標點,AI 有時候會「臉盲」,分不清紋理相似的區域。
於是,他們在查詢時順便把那個像素點周圍 9x9的小方塊圖像(RGB Patch)也喂給了模型。
這就像是你讓人在人群中找人,光給個坐標不行,還得給他一張那個人臉部的特寫照片。
消融實驗證明,這個小小的設計極大地提升了重建的銳度和細節。
產業影響 Google的野心與具身智能的眼睛
D4RT 的出現,對Google現有的業務版圖和未來的 AI 戰略有著極強的互補性。
具身智能與自動駕駛的最後一塊拼圖
現在的機器人之所以笨,很大程度上是因為它們「看不懂」動態環境。
一個掃地機器人能避開沙發,但很難預判一隻正在跑過來的貓。
D4RT 提供的即時、密集、動態的 4D 感知,正是機器人急需的技能。
它能讓機器人理解:那個東西不僅現在在那裡,而且下一秒它會出現在我左邊。
對於自動駕駛而言,這種對動態物體(如行人、車輛)的像素級軌跡預測,是提升安全性的關鍵。
增強現實(AR)的基石
Google一直在 AR 領域尋找突破口(從當年的Google眼鏡,到現在的 Project Astra)。
要在眼鏡端實現逼真的 AR,必須要有極低延遲的場景理解。
D4RT 展示的高效推理能力(尤其是在移動端晶片上的潛力),讓「即時把虛擬怪獸藏在真實沙發後面」變得在工程上可行。
對普通人的影響 視訊編輯的「魔法化」
對於普通使用者,這項技術最快落地的場景可能是手機相簿和視訊編輯軟體。
想像一下,你拍了一段孩子踢球的視訊。
有了 D4RT,你可以像在《駭客帝國》裡一樣,在影片播放過程中隨意旋轉視角(儘管你拍攝時並沒有移動),或者輕易地把路人從複雜的背景中「扣」掉,甚至改變視訊中光源的方向。
這是 D4RT 這種 4D 重建技術成熟後的應用之一。
結語
D4RT 讓我們看到了一種新的可能性:AI 對世界的理解,正在從二維的「圖像識別」跨越到四維的「時空洞察」。
它告訴我們,要看清這個流動的世界,關鍵不在於每一幀都看得多仔細,而在於如何建立一個能夠隨時回應疑問的全域記憶。
在 AI的眼中,過去並沒有消逝,未來也不再不可捉摸,它們只是同一個四維坐標系裡,等待被查詢的兩個不同參數而已。 (新智元)