
在資訊爆炸的AI時代,數據洪流如同奔湧的江河,急需強大的動力引擎來驅動其潛能。而GPU,這個曾被視為圖形渲染領域的專屬硬件,如今已華麗變身,成為AI時代的強大引擎。它們不再是簡單的影像處理單元,而是智慧運算的加速器,為AI的快速發展提供了澎湃動力。
GPU晶片架構的演進,是這股動力的關鍵。架構,就像GPU的DNA,決定了GPU的效能、效率和應用範圍。從早期簡單的圖形處理,到現今的AI大模型訓練與推理,每一次架構的迭代,都是GPU潛能的深度挖掘。架構的創新,讓GPU在AI時代煥發了新的生命力。
GPU晶片架構的設計,涉及核心數量、記憶體頻寬、能源消耗等多個面向。優秀的GPU架構,能夠實現高效能運算的同時,維持較低的能耗,滿足AI時代對運算效率的嚴格要求。
輝達的GPU,之所以能夠取得如今的壟斷地位,其晶片架構的創新居功至偉。那麼,輝達晶片架構是怎麼一步步發展迭代的,華為的達文西能不能追得上,有沒有後發優勢?接下來,我們嘗試就這個問題來進行探討。
從GeForce到Blackwell,輝達是如何一步一步走到今天的?
在半導體產業的舞台上,輝達以其GPU晶片架構的創新,一直走在GPU技術浪潮的前端。接下來,我們來看看,從GeForce到Hopper,輝達是如何一步步鑄就其在高效能運算領域的領導地位的。
輝達的起步與GeForce系列的誕生密切相關,1999年,GeForce 256以其硬體T&L技術,為3D圖形處理設定了新的業界標準。隨後,輝達推出了Tesla系列,這項轉變不僅是產品線的擴展,更是策略方向的調整。 Tesla GPUs在高效能運算領域嶄露頭角,其應用案例包括著名的"折疊@home"項目,該項目利用分散式運算能力研究蛋白質的折疊過程。
Fermi的洪荒之力
2010年,輝達的Fermi架構GPU,GTX 480,以其512個CUDA核心和驚人的3億電晶體數量,將GPU的運算能力推向了一個新的高度。 Fermi架構的推出,不僅是電晶體數量的增加,更重要的是CUDA技術的發展,它為GPU通用運算提供了強大的支持,開啟了GPU並行運算的新紀元。
Kepler的能效之舞
2012年,Kepler架構的GTX 680問世,它在每瓦性能上實現了顯著提升。Kepler架構透過動態調整核心頻率和電壓,實現了性能與功耗的平衡。這項架構的能效最佳化,使得GPU在資料中心等環境中得到了廣泛應用,例如在亞馬遜AWS的EC2運算實例中,就採用了基於Kepler架構的GPU。
Maxwell的智慧調度創新
2014年,Maxwell架構的GTX 980發布,它在每瓦性能上比前代產品提升了20%。 Maxwell架構的智慧調度技術,透過優化記憶體存取與執行效率,進一步提升了GPU的效能。 Maxwell架構的GPU在AI邊緣運算領域也有所作為,例如在自動駕駛汽車的感測器資料處理中。
Pascal對深度學習的全面擁抱
2016年,Pascal架構的Tesla P100 GPU問世,它採用了16nm FinFET工藝,擁有高達3584個CUDA核心。 Pascal架構的推出,標誌著輝達全面擁抱深度學習。 P100 GPU在AI研究和應用開發中被廣泛應用,例如在Google的DeepMind專案中,P100 GPU就發揮了關鍵作用。
Volta引入了Tensor Core
2017年,Volta架構的Tesla V100 GPU發布,它引入了Tensor Core,專門為深度學習訓練和推理優化。 V100的發布,使得AI訓練的速度比前代產品快了數倍。 V100 GPU在多個領域取得了顯著成就,包括在史丹佛大學的研究中,V100 GPU加速了蛋白質結構預測的計算過程。
Turing引進了即時光線追蹤技術
2018年,Turing架構的RTX 2080 Ti顯示卡問世,它引入了即時光線追蹤技術,為遊戲和電影渲染帶來了革命性的變化。 Turing架構的推出,不僅提升了圖形渲染的質量,也為3D建模和視覺化提供了強大的支援。在電影《復仇者聯盟4:終局之戰》的製作中,Turing GPU就扮演了重要角色。
Ampere,A100的核心
2020年,Ampere架構的A100 GPU發布,它採用了7nm工藝,擁有6912個CUDA核心和432個Tensor Core。 A100在AI訓練和推理表現上,相比前代產品提升了20倍,進一步鞏固了輝達在AI和HPC領域的領導地位。 A100 GPU在多個高效能運算專案中取得了突破,包括在橡樹嶺國家實驗室的Frontier超級電腦中,A100 GPU為模擬核融合反應提供了關鍵運算能力。
Hopper的記憶體架構創新
2022年,Hopper架構的GPU發布,它在效能和效率上再次實現了飛躍,引入了新一代的Tensor Core和更有效率的記憶體架構。 Hopper的推出,標誌著輝達在AI晶片領域的最新進展。 Hopper GPU在AI領域的應用前景廣闊,預計在自然語言處理、影像辨識等多個領域取得突破。
Blackwell,專為AI大模型而生,採用第二代Transformer引擎
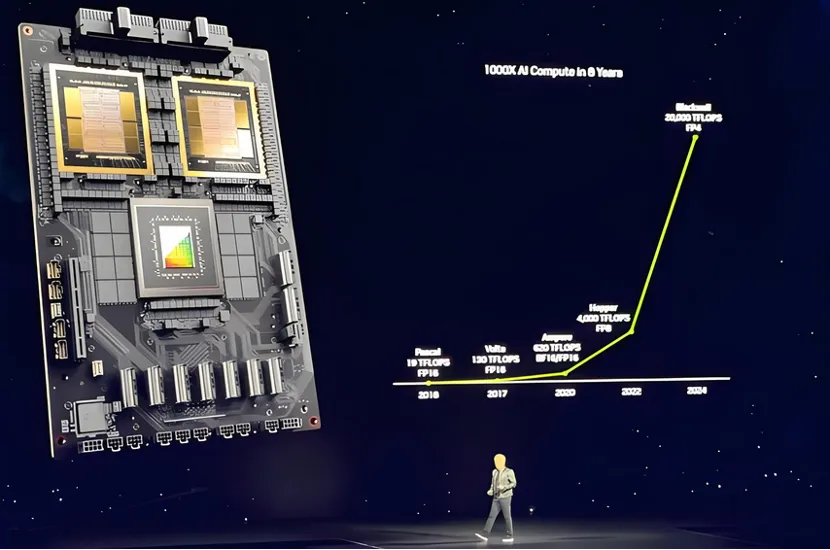
進入2024年,輝達的Blackwell架構代表了該公司在GPU晶片設計上的最新進展。作為繼Hopper架構之後的新一代產品,Blackwell帶來了一系列重大的性能提升和技術革新。 Blackwell GPU專為因應AI時代對運算能力的龐大需求而設計,特別是在處理兆參數規模的AI模型方面。
Blackwell架構的GPU採用了雙晶片配置,透過高頻寬介面(NV-HBI)實現兩個GPU晶片的高效互聯,支援高達10TB/s的頻寬。這種設計顯著提升了整體性能,同時保持了良好的能源效率比。 Blackwell GPU還配備了高達192GB的HBM3e記憶體和超過8TB/s的記憶體頻寬,為處理大規模AI模型提供了充足的記憶體容量和頻寬。
在AI訓練與推理效能方面,Blackwell GPU相較Hopper架構的GPU實現了顯著提升。其訓練性能是Hopper GPU的4倍,推理性能更是高達30倍。這種效能的飛躍得益於Blackwell GPU採用的第二代Transformer引擎和客製化的Tensor Core技術,這些創新為大型語言模型(LLM)和專家混合模型(MoE)的推理過程帶來了顯著加速。
此外,Blackwell架構也引進了第五代NVLink技術,為GPU之間的高速互聯提供了支援。這使得Blackwell GPU能夠支援多達576個GPU的集群,為建構超大規模AI系統提供了可能。
輝達的GPU晶片架構演進,是一段由技術創新驅動的歷史。每一次架構的更新,都伴隨著效能的大幅提升和能源效率的最佳化。從Fermi的誕生到Hopper的最新進展,輝達不斷突破技術極限,推動整個產業的發展。這不僅是技術的勝利,更是對未來運算模式的探索。
輝達GPU架構的未來發展方向,將持續圍繞著效能提升、能源效率最佳化和技術創新。隨著AI技術的不斷進步和應用場景的不斷擴展,輝達的GPU架構將繼續朝著更高的運算效率、更強的AI處理能力和更優的圖形渲染效能方向發展。同時,輝達也在積極佈局雲端運算和邊緣運算,透過DGX Cloud等雲端服務,為AI研究和應用提供了靈活、高效的運算資源。
在AI運算的長遠佈局上,輝達不僅關注GPU架構的最佳化,也著眼於整個AI生態系的建置。透過CUDA和其他軟體開發工具,輝達為開發者提供了強大的支持,推動了AI技術的發展和應用。此外,輝達也與科技巨頭如蘋果合作,共同推動AI和機器人技術的革新,展現了其在AI領域的深遠影響力和領導地位。隨著技術的不斷進步和市場需求的不斷擴大,輝達的GPU架構將繼續引領AI運算的未來。
華為達文西,一個來自中國的對手
在AI晶片架構領域,輝達有一個來自中國的對手-華為達文西。
華為達文西架構作為華為自研的AI運算架構,雖然相較於業界其他一些架構起步較晚,但已經展現出了強大的競爭力和創新能力。
接下來,讓我們簡單回顧一下華為達文西的關鍵發展節點:
1. 2018年:華為首次公開提出達文西架構,並推出基於此架構的AI晶片Ascend 310(昇騰310)。這是達文西架構的首次亮相,標誌著華為正式進入AI晶片領域。
2. 2019年6月:華為發表麒麟810晶片,這是首款採用達文西架構NPU的智慧型手機SoC晶片。麒麟810的AI性能在當時的AI Benchmark名單中表現卓越,證明了達文西架構的實力。
3. 2019年8月:華為發表AI晶片Ascend 910,這是一款面向雲端AI訓練與推理的高效能AI處理器。 Ascend 910的發布,進一步豐富了華為AI晶片的產品線。
4. 2020年:華為繼續推進達文西架構的發展,推出了Ascend 系列的其他產品,包括Ascend-Nano、Ascend-Tiny、Ascend-Lite、Ascend-Mini和Multi-Ascend 310等,覆蓋了從端側到雲端的全場景AI應用。
5. 2023年:華為算力GPU的出貨量顯著成長,預計到2024年將達到數十萬片的規模,這顯示華為達文西架構的AI晶片在市場上已經取得了一定的認可和應用。
儘管華為達文西架構起步較晚,但其發展速度和技術創新能力不容小覷。
華為達文西架構之所以能在AI晶片領域異軍突起,其核心競爭力在於創新的3D Cube運算引擎。這引擎專門針對AI計算中最關鍵的矩陣運算進行最佳化,透過三維立體的計算模式,實現了資料並行處理的質的飛躍。在3D Cube的加持下,每個AI Core在一個時脈周期內能夠執行高達4096個MAC(乘-累加)操作,這樣的算力密度在傳統CPU和GPU中是難以想像的。
這種設計不僅提升了算力,更在單位功耗下實現了AI算力的顯著提升,這對於功耗敏感的行動裝置和需要大規模部署的雲端伺服器來說,具有極其重要的意義。在AI晶片的戰場上,能效比往往決定了一款產品的生死,而達文西架構在這方面的表現無疑給了華為一些底氣。
除了3D Cube,達文西架構的另一個亮點是其整合的多種運算單元,包括向量、標量以及硬體加速器等。這些單元的協同工作,使得達文西架構能夠靈活處理各種複雜的AI運算任務,從基礎的數學運算到複雜的深度學習演算法,都能游刃有餘。這種靈活性和擴充性,讓達文西架構能夠適應多變的AI應用場景,無論是端側的智慧型裝置或是雲端的大規模運算任務,都能提供強大的支援。
此外,達文西架構對多種精確度運算的支持,也是其一大優勢。在AI訓練和推理過程中,不同的任務對資料精度的要求各不相同,達文西架構能夠根據任務需求靈活調整,既保證了計算的準確性,又避免了資源的浪費,實現了效率和效果的最優平衡。
當然,雖然華為達文西在許多方面作出了自己的特色,但面對強大的輝達,依然顯得弱小。
GPU晶片架構還遠遠沒有到“完全體”
GPU晶片架構的演進是一場永無止境的技術革新之旅,儘管已經取得了顯著的進步,但袁還沒達到至善至美的"完全體"形態。那麼,晶片架構演進的方向是什麼呢?以下是GPU晶片架構發展中值得關注的幾個方向:
1. 統一架構(One Architecture):GPU架構正朝著能夠在不同運算環境中提供一致性能和功能的方向發展。這意味著,無論是在資料中心的大型伺服器,或是邊緣設備上,同一款GPU架構都應具備高效率的執行能力。例如,輝達的Ampere架構就被設計為能夠同時支援x86和Arm架構,這使得GPU能夠跨平台工作,簡化了開發流程並擴大了應用範圍。
2. 訓練與推理融合:AI晶片的設計越來越注重同時支援訓練與推理任務。傳統上,訓練和推理需要不同類型的硬體優化,但隨著技術的進步,正在實現在同一硬體上對兩者的高效支援。推理功能的最佳化特別關鍵,因為它直接關係到AI模型在實際應用中的反應速度和能效比。
3. 記憶體容量的成長:隨著AI模型的規模和複雜度不斷增加,對記憶體容量的需求也急劇上升。 HBM技術透過3D堆疊多個DRAM層來提供更高的記憶體密度和頻寬。預計到2025年,HBM技術將達到前所未有的容量和頻寬水平,這將大大推動AI晶片的效能提升。
4. 軟硬體協同最佳化:軟硬體的緊密結合是實現GPU最佳效能的關鍵,輝達的CUDA平台和其GPU硬體之間的協同就是一個典型例子。軟體層面的最佳化可以充分發揮硬體的潛力,而硬體設計時也需要考慮軟體的執行效率。
5. 更強的互聯技術: GPU之間以及運算節點之間的高速互聯,對於建構大規模運算叢集至關重要。例如,輝達的NVLink技術提供了單一節點內GPU間高達數百GB/s的互連頻寬,而InfiniBand技術則廣泛用於節點之間的高速通信,這對於實現高效的並行運算和資料共享至關重要。
6. 先進封裝技術:隨著晶片尺寸的縮小和整合度的提高,傳統的封裝技術已經無法滿足需求。先進封裝技術,如Chiplet,允許在單一封裝內整合多個小晶片,從而實現更高的性能和更低的功耗。預計到2025年,這種技術將在AI晶片中廣泛應用。
7. 系統級創新:真正的創新來自於對整個系統每一個環節的深入理解和優化,從晶片設計、製造流程、記憶體技術到軟體工具和開發環境,每個環節都需要不斷創新,以實現整體性能的最優。
8. 快速迭代與效能提升:AI晶片的更新周期正在縮短,以適應快速發展的市場需求。每一代新晶片都在儲存、運算和互聯方面實現了顯著的效能提升,通常比上一代提升1.5到2倍以上。
對華為來說,要想在AI晶片架構上追趕輝達,就需要在上述方面發力。華為需要不斷優化達文西架構,提升其在統一架構下的效能和能源效率,加強記憶體和連網技術的研發,以及建構更完善的軟硬體生態系統。透過系統性的創新和快速迭代,才有望逐步縮小與產業領導者的差距,並在未來的AI晶片競爭中佔有一席之地。(數據猿)