
今天給大家帶來華為最新的大模型論文。能做多模態大模型最佳化的企業較少,希望大家能從中有所啟發。
【論文標題】
Efficiently serving large multimedia models using EPD Disaggregation
01 摘要
大型多模態模型(LMMs)通過處理圖像、音訊和視訊等多樣化輸入擴展了大型語言模型(LLMs),但代價是增加了一個多模態編碼階段,這增加了計算和記憶體開銷。
此步驟有助於將原始輸入轉換為token,使預填充階段的token序列膨脹,對關鍵服務水平目標(SLOs)如首次token時間(TTFT)和端到端吞吐量產生負面影響。
本文介紹了編碼-預填充-解碼(EPD)解耦,這是一種將編碼、預填充和解碼階段分離到專用資源上的新穎框架。
與當前將編碼和預填充捆綁在一起的系統不同,本文的解耦方法緩解了記憶體瓶頸,減少了同步延遲,並支援靈活的批處理。
具體而言,本文採用了一種新的多模態token快取機制,實現了多模態token的非同步傳輸,並引入了一個整合模組來尋找 EPD 系統的最優組態,在最大化基於 SLO 的性能指標的同時最小化資源使用。
對流行的 LMMs 進行的實驗評估顯示,在記憶體效率方面有顯著提高(編碼階段 GPU 記憶體減少高達 15 倍)
支援高達 22 倍的更大batch、每個請求多 10 倍的圖像數量、2.2 倍的更大 kv 快取大小。
此外,與未解耦的系統相比,它在端到端吞吐量(提高高達 57%)和延遲指標(TTFT 降低高達 71%)方面有顯著改善。
本文的研究結果強調了 EPD 解耦在實現大規模資源高效和高性能多模態推理方面的潛力。
02 背景
大型語言模型在語言理解和推理方面取得了巨大進展,但在處理多模態資料時,大型多模態模型面臨著獨特的挑戰。
由於處理多模態資料帶來的額外計算和記憶體需求,滿足嚴格的服務水平目標(如端到端吞吐量、首次token時間和每個輸出token時間)變得愈發困難。
與僅涉及預填充和解碼階段的大型語言模型不同,大型多模態模型需要額外的編碼階段來處理原始多模態輸入,這一階段計算密集,會產生大量額外token
增加了資源消耗並導致預填充階段計算需求呈二次增長,影響了服務水平目標的實現。
在當前系統中,編碼和預填充階段通常在同一組 GPU 上作同步執行,這加劇了記憶體瓶頸、批處理靈活性受限和同步延遲等低效問題,表明當前解決方案不足以應對大型多模態模型的工作負載。
03 貢獻
- 本文確定了現有多模態推理系統性能欠佳的主要挑戰和性能瓶頸,具體源於編碼和預填充是單個整體化且同步的步驟,導致記憶體和計算資源利用效率低下。
- 本文提出了一種基於將編碼和預填充階段解耦的新穎思想的高效大型多模態模型推理系統,解決了該框架內的資源分配、階段間通訊和性能最佳化等關鍵挑戰,並提出分配新快取來儲存編碼和預填充階段的多模態token,以實現多媒體token的高效非同步傳輸。
- 本文將尋找 EPD 解耦系統的最優組態表述為一個黑盒最佳化問題,該方法簡單實用,其搜尋空間可靈活納入包括各種平行化策略、GPU 分配、batch大小選擇和複雜調度策略等現實組態,且計算效率高,通過模擬即可輸出性能指標而無需實際部署系統。
- 針對各種流行的 LMMs 模型(即 MiniCPMv 2.6、InternVL2-8B 和 InternVL2-26B)的基線對方法進行了詳細的實驗分析,結果在各個方面展示了方法的優越性
04 技術方案
從高層次來看,LMM 系統將多模態資料和文字提示轉換為連貫的文字輸出。
4.1 LMM系統
系統接收三種類型的輸入:
(1)文字提示,為任務提供上下文;
(2)多模態資料,包括圖像、視訊或其他感官輸入;
(3)採樣資料,包含諸如期望的輸出token數量和溫度設定等參數。
系統處理這些輸入以生成文字輸出,即模型的響應。
為簡化起見,本文主要關注視覺模態,但該框架可擴展到其他類型的多模態資料。
4.2 EPD 解耦
將 LMM 系統解耦涉及將推理過程分解為不同階段,每個階段有特定的輸入和輸出。
如圖 1 所示,系統遵循一個由三個主要元件組成的多階段推理pipeline:編碼、預填充和解碼。
此外,這些階段之間的轉換通過遷移和遷移進行管理,分別處理編碼-預填充和預填充-解碼階段之間的資料傳輸。
編碼(E):多模態輸入由多模態編碼器(MME)處理,在編碼階段 GPU 上將輸入資料轉換為多模態token 。
這些token代表輸入的高維嵌入,並作為pipeline下一階段的基礎。
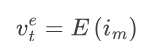
EP 遷移:編碼階段E完成處理之後,生成的多模態token et必須傳輸到預填充階段P。
傳輸由遷移函數管理:
這裡,表示遷移後預填充階段的token。
預填充(P):與文字提示一起到達預填充階段。
在此階段,系統初始化鍵值(KV)快取並生成第一個輸出token 。
KV 快取儲存上下文和中間狀態,這對於後續的解碼階段是必需的。
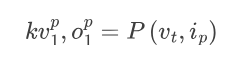
解碼(D):解碼階段迭代操作,使用 KV 快取和先前生成的token 生成下一個token 並將 KV 快取更新為。
這個自回歸過程持續到生成期望的輸出序列。
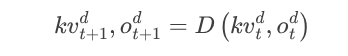
4.3 系統設計與最佳化
非同步token傳輸:為了最小化階段間token傳輸的延遲,系統通過高頻寬 NVLink/InfiniBand/NVSwitch 通道支援直接的非同步token傳輸。
傳輸是非同步的,允許系統在token傳輸進行時繼續處理新請求。
具體來說,在編碼和預填充工作者上都維護一個多模態快取(MM 快取)。
當一個請求完成編碼階段時,其token首先儲存在編碼工作者的 MM 快取中,使編碼工作者能夠立即處理後續請求。
一個獨立的非同步事件循環持續監測完成的編碼任務。
當一個請求的token可用時,此事件循環啟動將token直接傳輸到預填充工作者的 MM 快取。
由於傳輸是非同步的,系統可以平行處理其他任務而不會停頓。
一旦token傳輸確認,編碼階段相應的 MM 快取條目將被清除,以便為未來請求回收記憶體。
為了有效管理這些快取區域,引入了 MMBlockManager。
對於每個傳入請求,MMBlockManager 預先計算請求所需的快取塊數量並相應地分配它們。
在請求從編碼階段轉換到預填充階段且token傳輸後,這些塊將被重新分配或釋放,即使在高負載下也能實現靈活的快取使用。
請求內平行(IRP):通常,多模態請求包含多個高解析度圖像,每個圖像被劃分為小塊以進行高解析度編碼。
對於現代 LMMs,負責處理這些小塊的編碼器可能很大,使得編碼階段計算受限。
因此,如果一個請求序列處理,編碼階段可能成為瓶頸,顯著增加首次token延遲 TTFT。
為瞭解決這個問題,引入了請求內平行(IRP),它將單個請求的圖像小塊在多個以資料平行模式運行的編碼工作者之間進行分割。
基於這些小塊是獨立編碼的直覺,它們可以平行和非同步地處理。
如圖 3 所示,每個編碼工作者接收不同的小塊子集,計算相應的token表示,並獨立且非同步地將它們傳輸到預填充階段。
這意味著分配給一個編碼工作者的小塊可以完成並開始傳輸,而無需等待其他工作者處理的小塊。
一旦所有小塊等級的token到達預填充階段,它們將被對齊、投影和合併,以形成請求的完整多模態token集。
然後請求像往常一樣繼續通過預填充階段,相應的 LLM 處理聚合的多模態和提示token。
通過允許多個工作者平行編碼小塊,IRP 有效地減少了端到端延遲並提高了可用編碼資源的利用率,特別是對於具有大量小塊的高解析度輸入。
最佳化資源分配:系統動態地確定pipeline每個階段的組態,如batch大小、調度策略和平行化方法。
這確保了關鍵性能指標基於部署期間收集的工作負載樣本保持接近最優。
這些工作負載樣本是從最近的時間窗口即時收集的。
如果在後續時間窗口中最優性能指標有顯著變化,系統可能會相應地調整 EPD pipeline的組態。
利用黑盒最佳化演算法選擇組態,最小化 GPU 使用並最大化關鍵性能指標。對於線上服務場景,將有效吞吐量定義為關鍵性能指標。
有效吞吐量表示滿足 TTFT 和 TPOT 要求的 90% 請求的最大請求率。在離線場景中,TTFT 和 TPOT 約束不太關鍵,使用 E2ETP 作為性能指標。
根據性能指標的性質,最佳化組態將最小化pipeline低效(如空閒時間)並確保有效利用分配的資源。最佳化問題表述為:
其中是系統組態的搜尋空間,包括平行化組態、最大batch大小組態和調度組態。
這些變數是向量,每個元素代表單個實例的組態。
這裡,一個實例可以獨立處理請求,包括用於張量平行和pipeline平行的(子)工作者。
由於一個階段內的實例平行處理不同請求,本文稱之為資料平行。
注意、、可以有不同長度,因為實例數量本身是一個可組態參數。
對於第個實例,將其階段表示為。
平行化:令表示所有實例的平行組態向量。
對於第個實例,如果它是預填充或解碼實例,則其組態包括:,用於張量平行的 GPU 數量和,用於pipeline平行的 GPU 數量。
如果它是編碼實例,考慮到請求內平行(IRP)不需要通訊且優於張量平行(TP),本文僅使用 IRP。
因此,多載符號來表示用於 IRP 的 GPU 數量。
如果每個 GPU 的成本是常數,則總成本為
最大 batch 大小:確定在編碼、預填充和解碼階段同時處理的請求數量。
令表示所有實例的batch大小組態。
對於第個實例,是其最大batch大小。
此組態涉及延遲和吞吐量之間的權衡。
較大的batch大小通過啟用平行處理提高吞吐量,但如果階段計算受限可能會增加延遲。
調度:本文採用了 DistServe 框架中的策略。
在編碼階段,當請求到達時,它被分配並推送到一個實例佇列。
在預填充和解碼階段,使用全域佇列,每個引擎在可用時從該佇列拉取請求。
編碼階段可能的分配策略包括輪詢或最少負載優先分配請求。
一旦請求被分配到工作者的佇列,本文可以應用諸如先到先服務或最短作業優先等排序策略,或者更複雜的基於服務水平目標(SLOs)優先處理請求的策略。
為簡單起見,本文約束同一階段內的所有實例共享相同的調度策略。
在問題的目標中,是一個權重,用於控制性能和成本降低之間的權衡。
在黑盒設定中,性能函數是未知的,必須通過模擬評估以獲得性能指標值。
為瞭解決最佳化問題,可以採用現有的方法,如隨機搜尋、進化演算法、貝葉斯最佳化和參數化迭代局部搜尋來找到最優組態。
05 實驗結果
端到端生成的 SLO 達成情況
在該實驗中,本文評估了所提出的方法(EPD)、去除 IRP 特徵的方法(EPD - IRP)以及現有最先進的基線 DistServe 和 vLLM 的端到端 SLO 性能。
實驗設定涉及 8 個 NVIDIA A100 GPU 處理 100 個多模態請求。
在不同的每個請求圖像數量下測試了三個不同的模型 ——MiniCPMv 2.6、InternVL2-8B 和 InternVL2-26B。
所有圖像都固定為 4K 解析度(4032x3024 像素)。
每個組態的 SLO 標準(如表 1 所示)為 TTFT 和 TPOT 建立了延遲上限,確保及時生成token和一致的解碼性能。
結果如圖 4 所示,EPD-IRP 在大多數情況下在較低請求率下實現了超過 90% 的 SLO 達成率,優於其他基線。
EPD 在許多情況下 SLO 達成率接近 50%,而 DistServe 和 vLLM 表現最差,通常 SLO 達成率低於 10%。
隨著每個請求圖像數量的增加,所有基線的 SLO 達成率下降,尤其是在較高請求率下,但 EPD-IRP 在重負載下仍保持合理的 SLO 達成率。
隨著模型從左到右的變化(從 MiniCPMv 到 InternVL 模型),所有基線的性能逐漸變差,因為 InternVL 模型是預填充密集型的,而 MiniCPMv 模型是編碼密集型的。
首次Token生成延遲
在該實驗中,本文分析了所提出的方法(EPD)、去除 IRP 特徵的方法(EPD-IRP)和現有最先進的基線 DistServe 的 TTFT 性能。
與之前關注端到端推理的分析不同,本實驗隔離了計算的預填充階段,因為在多模型工作負載中,由於大量的預填充token,首次token的生成是一個關鍵的延遲瓶頸。
注意在本設定中,由於不涉及解碼階段,DistServe 基線等同於 vLLM。
結果如圖 5 所示,EPD-IRP 在所有三個模型中顯著優於 EPD 和 DistServe 基線,TTFT 分別比 DistServe 基線低高達 71.9%、32.8% 和 44.9%,這得益於其請求內平行化。
EPD 也比 DistServe 略有性能提升,突出了編碼和預填充階段解耦的獨立優勢。
隨著每個請求圖像數量的增加,改進的幅度變得更加明顯。
通過階段解耦實現的記憶體節省
在 EPD 系統中,通過將編碼和預填充階段解耦實現了顯著的記憶體節省。在現有系統(如 DistServe 和 vLLM)中,編碼和預填充階段位於同一 GPU 上,需要每個 GPU 同時載入 MME 和 LLM,導致更高的記憶體消耗。
相比之下,提出的解耦系統通過將編碼階段分配給僅載入 MME 的 GPU,預填充階段分配給僅載入 LLM 的 GPU,最佳化了記憶體使用,顯著降低了兩個階段的記憶體需求。
對於 MiniCPMv 2.6、InternVL2-8B 和 InternVL2-26B 模型,編碼階段 GPU 的記憶體分別減少了約 95%、96.2% 和 78.3%,預填充階段 GPU 的記憶體分別節省了約 5%、3.7% 和 21.6%。
實際上,由於編碼階段不需要載入僅預填充所需的 KV 快取,記憶體節省可能高達 15 倍。這種記憶體使用的減少使 EPD 系統能夠更有效地分配資源,支援更多的任務和模型。
離線設定下的吞吐量
在離線場景中,考慮一批請求提交後系統過夜處理以最大化端到端(E2E)吞吐量的情況。
傳統的 DistServe 方法在同一工作者上為編碼和預填充階段分配記憶體,受 GPU 總記憶體容量限制。
在低端 GPU 記憶體有限的異構環境中,這種記憶體限制尤為顯著,導致 DistServe 方法難以充分利用低端 GPU。
相比之下,解耦的 EPD 方法更具成本效益,因為它將低端 GPU 專門分配給編碼階段,更好地利用了可用記憶體。
如圖 6所示,EPD 方法在選擇合適的 GPU 組態時能最大化 E2E 吞吐量;
在每個請求圖像數量較低時,EPD 實現了更高的吞吐量,表明其架構防止了編碼器成為計算瓶頸;
EPD 的性能對編碼和解碼batch大小相對不敏感,始終優於 DistServe 方法,這使得可以選擇相對較大的batch大小或依靠演算法自動選擇最優batch大小。
06 結論
在本文中,提出了一種通過分解關鍵處理階段來最佳化大型多模態模型(LMM)系統的新穎方法。
通過將編碼、預填充和解碼任務分離到不同階段,該系統在資源分配方面提供了更高的靈活性,能夠更有效地管理計算和記憶體資源。
這種解耦方式,結合動態資源分配、非同步token傳輸和先進的平行化策略,直接解決了 LMMs 部署中的幾個關鍵挑戰,包括降低延遲、最佳化記憶體和高效利用計算資源。
本文的結果表明,在吞吐量和記憶體效率方面都有顯著的提高,特別是在資源有限的異構環境中。
通過有效地平行化編碼和預填充階段,能夠緩解常見的瓶頸問題,並提高多模態推理任務的可擴展性。
此外,最佳化的記憶體管理策略確保系統能夠擴展以處理更大的模型和更複雜的多模態輸入,這在現實世界的應用中越來越常見。
本文所提出的方法在多模態人工智慧可擴展和高效系統的發展中邁出了重要的一步,為自然語言處理、電腦視覺和跨模態理解等領域的未來研究和實際應用奠定了基礎。
總之,該系統為提高 LMMs 的性能提供了一個強大的解決方案,使其在現實世界的資源受限環境中更高效、更具適應性地部署。 (AcademicDaily)