
討論新銳大語言模型deepseek如何助力自動駕駛是車輛行業當前的熱點問題。
按照一個自然合理的討論過程,本文首先討論自動駕駛(AD)有那些環節構成,其次討論deepseek的來龍去脈,再討論自動駕駛那些環節可以用到deepseek,最後總結和展望。
#01
自動駕駛的技術堆疊
自動駕駛的技術堆疊涵蓋了多個領域,包括感知、決策、控制和系統整合等。
自動駕駛技術堆疊中的主要組成部分如下:
1. 感測器:自動駕駛系統使用多種感測器來獲取環境資訊,如雷達、攝影機、激光雷達、超聲波感測器等。這些感測器提供關於周圍物體、道路狀況和其他交通參與者的資料。
2. 感知與感知融合:感知模組使用感測器資料進行物體檢測、分類、跟蹤和場景理解等任務。感知融合將來自不同感測器的資料進行整合,提供對環境的全域感知和理解。
3. 地圖和定位:地圖和定位模組為自動駕駛系統提供定位和地圖資訊。高精度地圖用於提供車輛所處位置、車道資訊、交通標誌和交通規則等,以幫助車輛進行路徑規劃和決策。
4. 路徑規劃與決策:路徑規劃模組使用感知和地圖資料,為車輛規劃安全和高效的行駛路徑。決策模組基於感知和路徑規劃的結果,制定即時決策策略,如車輛的轉向、加減速和避讓行為等。
5. 控制系統:控制系統模組將決策結果轉化為車輛的具體控制指令。它涵蓋了車輛的轉向、加減速、制動和穩定控制等,以確保車輛按照決策模組的指令進行安全、平穩的行駛。
6. 人機互動:人機互動模組負責與駕駛員或乘客進行互動,如語音指令、觸控式螢幕介面、圖形顯示等。它使駕駛員能夠與自動駕駛系統進行溝通、瞭解當前狀態和提供輸入。
7. 安全和監控系統:安全和監控系統用於監測自動駕駛系統的狀態,檢測故障、異常和緊急情況,以確保系統的安全性和可靠性。它還可以提供即時監控、資料記錄和故障排查等功能。
8. 資料處理和機器學習:巨量資料處理和機器學習在自動駕駛中起著重要作用。通過對大量資料進行處理和分析,可以提高感知、決策和預測的精準性和魯棒性。
9. 演算法開發和最佳化:演算法開發和最佳化涉及開發和改進自動駕駛系統的核心演算法,包括感知、路徑規劃、決策和控制等。不斷改進演算法可以提高系統性能和駕駛體驗。
10. 系統整合和測試:自動駕駛技術堆疊的最後一個環節是系統整合和測試。這包括將各個模組整合到一個完整的系統中,並進行功能驗證、安全性測試和實地路測等,以確保系統的穩定性和安全性。
雖然自動駕駛技術異常複雜和龐大,但概括言之,運行階段的自動駕駛就是三大塊:
第一塊感知:感知到自身的位置速度和其它障礙物的位置速度,把它們的即時位置標註在地圖上。特別注意,感知包括定位,也就是感知自身的真實位置。
這一塊最重要的技術是廣義的電腦視覺(CV,computer vision)。廣義是指不僅處理攝影機資料,還會處理點雲資料。點雲資料一般是四元組(x,y,z,u),xyz是點雲像素點的三維坐標,u是訊號反射強度。
AD車輛的感知,圖片來自車雲網
第二塊決策或者叫規劃。現在車輛已經知道自己的位置和所有潛在障礙物的位置,並且還可以根據障礙物的速度方向(如果是動態的話)預測障礙物短期新的位置。又知道自己要去的位置,那麼就可以在地圖上用圖論演算法規劃路徑,路徑連接本車當前位置和目標位置,中途避開所有障礙物。
這一塊核心技術是路徑的圖論規劃,包括:
a、圖論算路演算法
b、路徑平滑(不能光有連線,還得光滑)
c、速度規劃(不光有光滑連線,還有連線上每一個點的行車速度)
為了理解算路技術堆疊和大語言模型之間的技術差異,我們詳述一下圖論中的算路演算法。它是一種在圖結構資料上進行路徑計算和搜尋的重要方法。它主要研究如何在圖中的節點與節點之間找到一條或多條有效的路徑,以滿足特定的需求,比如最短路徑、最快路徑或者最小成本路徑等,而且所有路徑可以指定避開的節點(避障)。
在圖論中,一個圖由節點和邊組成,節點代表對象或者事件,而邊則表示節點之間的關係或者連接。算路演算法就是通過對這些節點和邊的分析,來尋找滿足特定條件的路徑。
常見的圖論算路演算法包括迪傑斯特拉演算法(Dijkstra's algorithm),它用於計算一個節點到其他所有節點的最短路徑;貝爾曼-福特演算法(Bellman-Ford algorithm),它可以處理帶有負權重邊的圖,並且能夠檢測負權重環;弗洛伊德-沃沙爾演算法(Floyd-Warshall algorithm),它用於計算圖中所有節點對之間的最短路徑;以及A*搜尋演算法,它是一種啟髮式搜尋演算法,常用於路徑尋找和圖遍歷等問題。
這些演算法在網路路由、地圖導航、社交網路分析、運輸系統最佳化等多個領域都有廣泛的應用。例如,在網路路由中,路由器使用算路演算法來確定封包從源頭到目的地的最佳路徑;在地圖導航系統中,算路演算法幫助使用者找到從一個地點到另一個地點的最快或者最短路線。
第三塊是控制。路徑已經決定,但還得沿著路經精確地開過去。控制的核心詞是”精確地“執行。車輛是一個複雜的機械系統,每一個執行環節都有自己的動態誤差和靜態誤差。道路行車同樣複雜,那怕左輪不小心壓到一個小石子,都會對控製造成隨機干擾。
控制的核心技術在於各種濾波演算法,其中最為著名的當屬卡爾曼濾波。卡爾曼濾波是一種高效的遞迴濾波器,它能夠在存在噪聲的情況下,通過系統的動態模型和觀測資料,估計出系統的狀態。這種演算法在導航、自動控制、訊號處理等領域有著廣泛的應用。
除了濾波演算法,控制技術還涉及到多種控制演算法,其中最為常用的是比例-積分-微分控製器,簡稱PID控製器。PID控製器因其結構簡單、易於實現而被廣泛應用於工業自動化領域。它通過比例(P)、積分(I)和微分(D)三個環節來調節系統的輸出,以達到預期的控制效果。比例環節能夠快速響應偏差,積分環節可以消除穩態誤差,而微分環節則有助於抑制系統的超調和振盪。通過合理調整這三個參數,PID控製器能夠實現對系統穩定性和響應速度的良好控制。
除了上面三大塊外,還有比較獨立的SLAM技術。SLAM(Simultaneous Localization and Mapping,同時定位與地圖建構)技術已經成為機器人領域的研究熱點。通過融合激光雷達、攝影機、IMU等多種感測器資料,SLAM技術賦予了機器人(無人駕駛車船無人機都屬於廣義的機器人)自主導航與環境感知的能力。
由上可見,感知階段的主要處理對像是像素點(包括圖像和點雲);規劃階段的主要處理對像是離散的圖論節點;控制階段的主要處理對像是反映車輛運動狀態的浮點數。
那麼何為deepseek?deepseek的主要處理對象又是什麼?
#02
何為deepseek?
deepseek對標openAI的GPT系列大語言模型,和chatGPT一樣,它的主要處理對像是token。
那麼何為token?
在自然語言處理(NLP)領域,token是一個極為重要的概念。它通常指代文字資料中的最小意義單位。一個token可以是單詞、標點符號、數字,甚至是單個字元。在處理諸如句子、段落乃至整篇文章等文字內容時,將文字劃分成一個個token是一種常見的預處理步驟。
Tokenization(分詞)的過程就是將文字轉化為token序列的過程。這個過程可以通過不同的方法和技術來實現,例如基於規則的分詞、基於統計的分詞以及深度學習模型等。通過精確的tokenization,電腦能夠更好地理解和分析人類語言,從而為後續的自然語言理解和生成任務奠定基礎。
此外,token在自然語言處理中的應用非常廣泛,包括但不限於機器翻譯、情感分析、問答系統、文字摘要等。在這些應用中,token不僅作為輸入資料的基本單元,還在特徵提取、模型訓練等環節發揮著關鍵作用。因此,對token的深入理解和合理運用,對於提升自然語言處理系統的性能具有重要意義。
我們舉一個例子,將句子“The non-autonomous vehicle can't safely navigated through the busy city traffic.”分解為tokens,可以按照空格和標點符號進行分詞。下面是可能的一種分詞方式:

可見token是比word更小的最小語言單元。請注意到can't這個詞,被分解為了can和‘t兩個token。
下面我們列出openAI和Deep seek兩家公司的對比:
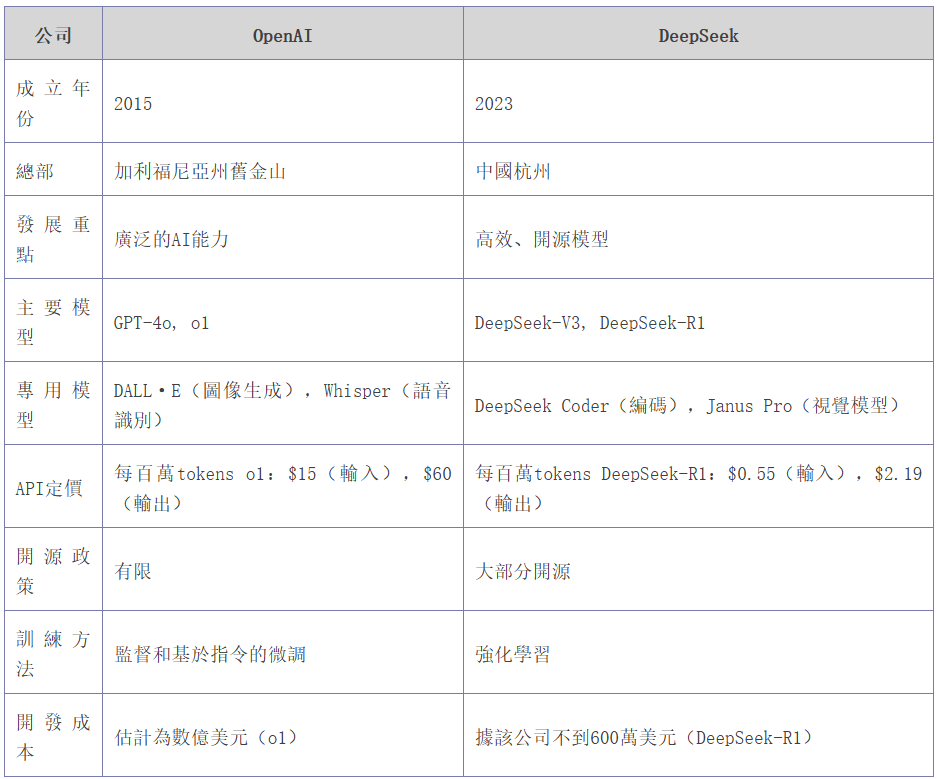
在以上deepseek與openAI的量化對比中,可以清晰看到DeepSeek的主要處理對像是token,並且無論在輸入還是輸出,deepseek每一個token的處理成本遠低於openAI。
#03
自動駕駛中應用多模態的deepseek
自動駕駛感知階段的主要處理對像是像素點(包括圖像和點雲);規劃階段的主要處理對像是離散的圖論節點;控制階段的主要處理對像是反映車輛運動狀態的浮點數。而deepseek的主要處理對像是作為語言原子單元的token。二者似乎並不一致。
如何處理這一點,好為自動駕駛車輛用上最新的AI科技?秘訣在於大語言模型的多模態擴展。
大語言模型的多模態擴展是指將語言模型的能力從僅處理文字資料擴展到能夠理解和生成多種類型的資料,包括圖像、音訊、視訊等多種形式的資訊。這種擴展使得大語言模型能夠更好地模擬人類的認知能力,從而在更廣泛的場景中發揮作用。
以下是幾種常見的多模態擴展方法和技術:
1. 多模態輸入處理:這種方法允許模型同時處理文字和其他類型的輸入資料(如圖像、音訊)。例如,一個模型可能需要理解一張圖片並根據圖片內容生成描述性的文字。為了實現這一點,模型通常會使用特定的架構來分別處理不同類型的輸入,並將它們融合在一起進行最終的輸出。
2. 跨模態理解與生成:這涉及到在不同模態之間建立聯絡,比如通過文字描述生成圖像或根據圖像生成描述性文字。這要求模型具備跨模態的知識表示學習能力,以便在不同的資料類型之間建立有效的對應關係。
3. 注意力機制:注意力機制可以幫助模型在處理多模態資料時關注最重要的部分。例如,在處理圖文混排的輸入時,模型可以通過注意力機制決定是更多地關注圖像還是文字,或者兩者之間的相互作用。
有了多模態技術加持,大語言模型才能高效增強自動駕駛技術。Deepseek產品家族中的deep seek V3就是一種多模態大語言模型。
我們在此羅列一些已知的自動駕駛中應用多模態的deepseek的場景,而且這些場景還在持續增加中:
1. 多模態環境感知增強
- 技術實現:
- 感測器融合:將攝影機圖像、激光雷達點雲、毫米波雷達訊號等輸入DeepSeek-V3,通過跨模態對齊技術(如注意力機制)實現資料融合。例如,模型可將圖像中的紅綠燈識別與雷達的測距資料進行時空對齊。
- 開放世界理解:利用大模型的開放域知識,識別訓練資料中未覆蓋的罕見物體(如特殊工程車輛、動物),彌補傳統感知模型的長尾問題。
- 語義場景分割:通過視覺-語言聯合建模,生成道路場景的語義描述(如“濕滑路面”“臨時施工區域”),為決策提供上下文資訊。
- 工程挑戰:
- 即時性最佳化:需通過模型輕量化(如知識蒸餾)或邊緣計算部署,將推理延遲壓縮至毫秒級。
- 不確定度校準:對模型輸出的置信度進行量化,避免錯誤感知引發連鎖風險。
2. 可解釋決策與因果推理
- 技術實現:
- 因果決策樹:將駕駛策略分解為“IF-THEN”規則鏈,由DeepSeek生成決策邏輯的自然語言解釋(如“減速因為前方行人正在看手機可能闖入車道”)。
- 博弈建模:模擬其他交通參與者(車輛、行人)的意圖預測,建構博弈論框架下的互動決策。
- 倫理權衡框架:針對“電車難題”類極端場景,利用大模型的社會常識生成符合倫理的優先順序判斷。
- 工程挑戰:
- 邏輯可驗證性:需將自然語言決策轉化為形式化驗證框架(如時序邏輯),確保符合ISO 26262功能安全標準。
- 即時推理成本:複雜因果鏈推理需設計分層決策機制,高頻操作(如跟車)由傳統控制演算法處理,低頻複雜場景觸發大模型介入。
3. 動態高精地圖建構
- 技術實現:
- 線上語義建圖:通過視覺SLAM+大模型即時生成道路拓撲結構的語義描述(如“第三車道因施工封閉”),替代預載入高精地圖。
- 眾包地圖更新:車輛群將局部感知結果上傳至雲端,DeepSeek-V3整合多源資料生成動態地圖更新包。
- 長尾場景標註:自動識別道路異常(如塌陷、遺落貨物),通過Few-shot學習快速生成標註資料。
- 工程挑戰:
- 資料一致性:需解決多車感知結果的時空對齊和衝突消解。
- 通訊延遲容忍:設計去中心化地圖更新協議,在弱網環境下仍能保障基礎功能。
4. 人機協同駕駛
- 技術實現:
- 意圖理解與接管預測:通過車內攝影機和語音輸入,即時分析駕駛員狀態(如疲勞、分心),預測接管需求時機。
- 自然語言互動:支援語音指令細粒度控制(如“在下個便利店停車”),同時解釋自動駕駛系統的行為(如“即將變道超車因為當前車速低於限速”)。
- 個性化策略適配:學習駕駛員習慣(如跟車距離偏好、變道激處理程序度),調整自動駕駛策略參數。
- 工程挑戰:
- 多模態訊號融合:需同步處理語音、手勢、生物感測器等多通道輸入。
- 隱私保護:駕駛員行為資料需本地化處理,避免雲端洩露風險。
5. 模擬與影子模式迭代
自動駕駛的影子模式(shadow mode)是一種後台最佳化自動駕駛演算法的方法。
當車輛處於有人駕駛狀態時,自動駕駛系統的感測器會不斷採集路況資訊,包括道路狀況、車輛位置、行人動態等。同時,自動駕駛演算法會根據這些資訊模擬出相應的駕駛決策。然而,這些決策並不會直接控制車輛,而是與駕駛員的實際操作進行對比。
如果自動駕駛演算法的模擬決策與駕駛員的操作一致,說明演算法在該場景下表現良好;如果存在差異,特別是當演算法決策與駕駛員操作差異超過閾值時,系統觸發資料回傳機制。這些高價值資料(包括路況和駕駛員對應操作,作為feature-label對應的訓練資料)將被上傳到雲端,用於持續最佳化自動駕駛演算法。
影子模式可以簡單理解為自動駕駛世界的”虛擬炒股“。
- 技術實現:
- 場景生成引擎:利用DeepSeek-V3生成涵蓋極端天氣、事故場景的虛擬測試用例,加速Corner Case覆蓋。
- 自動標註工具:對實車採集的未標註資料,通過提示工程(Prompt Engineering)生成高品質訓練標籤。
- 線上持續學習:在影子模式下對比人類駕駛與AI決策差異,自動生成強化學習獎勵函數。
- 工程挑戰:
- 模擬保真度:需物理引擎與大模型生成場景的耦合最佳化。
- 資料閉環效率:從資料採集到模型更新的端到端延遲需壓縮至小時級。
6. 應用案例設想
- 城市NOA(導航輔助駕駛):DeepSeek即時解析複雜路口交通警察手勢,動態調整通行策略。
- 無地圖越野駕駛:通過視覺+語言提示(如“沿車轍痕跡行駛”)實現非結構化道路導航。
- 應急避險系統:識別山體滑坡前的細微地質變化跡象(如鳥類異常飛航模式),觸發預防性制動。
#04
總結與展望
DeepSeek-V3需與傳統的自動駕駛技術堆疊(如控制理論、SLAM、強化學習)深度融合,其核心價值在於解決開放環境下的認知智能問題,而非替代現有感知-決策-控制鏈路。實際落地需遵循“場景化裁剪、功能安全優先”的原則,逐步從L2+輔助駕駛向高階自動駕駛演進。
筆者並不指望deepseek取代摺積神經網路CNN、光流optical flow、強化學習RL之類,已經在自動駕駛領域廣泛使用的深度學習模型,而是揚長避短,發揮它們各自的長處,結合起來使用。
而且deepseek和任何深度學習大模型一樣,面臨通用的關鍵限制與應對方法:
1. 確定性保障(神經網路可解釋性):大模型的機率性輸出需通過安全封裝層(如輸出範圍約束、多模型(MoE)投票)轉化為確定性控制訊號。
2. 功耗與算力:需設計專用NPU架構,支援稀疏化計算與混合精度推理。而且計算功耗在車載場景下會顯著縮短車載電池的續航力。最好是簡單決策本車執行,複雜操作上傳雲端執行。
3. 法規符合性:決策過程需滿足ASIL-D級可追溯性要求,可能採用“白盒化”子模組(如顯式規則引擎與大模型協同)。一般來說,是顯式規則模型對大模型的輸出進行即時審計,一直到大模型生成滿足審計的輸出才採納。 (汽車電子與軟體)