
DeepSeek開源周第三彈!DeepSeek-AI 重磅發佈高效FP8 GEMM庫 DeepGEMM:極致性能,程式碼精簡,助力V3/R1模型訓練與推理!
簡單來說這是由 DeepSeek-AI 團隊精心打造的 FP8 通用矩陣乘法 (GEMM) 加速庫,專為追求極致性能和程式碼簡潔而生
我們一起來扒一扒:
Hopper GPU 上狂飆 1350+ FP8 TFLOPS!
在算力為王的 AI 時代,矩陣乘法 (GEMM) 的效率至關重要。DeepGEMM 正是為瞭解決這一痛點!它充分利用 NVIDIA Hopper 架構 GPU的強大算力,在 FP8 精度下,性能 高達 1350+ TFLOPS!這意味著更快的模型訓練速度,更流暢的推理體驗,以及更低的計算成本!
DeepGEMM 不僅適用於傳統的 稠密模型,更完美支援 混合專家模型 (MoE) 的 GEMM 計算,無論是 DeepSeek-V3 還是 R1 模型,都能得到強力加速!
程式碼極簡!核心邏輯僅 300 行,堪比教學級!
你沒聽錯!DeepGEMM 的核心 kernel 函數程式碼量僅有 驚人的 ~300 行! DeepSeek-AI 團隊秉持著 “大道至簡” 的設計理念,在保證極致性能的同時,力求程式碼的 可讀性 和 可維護性。 即使是剛入門 CUDA 開發的同學,也能輕鬆理解 DeepGEMM 的實現原理,甚至可以作為學習 Hopper FP8 矩陣乘法和最佳化的絕佳教學!
✅ 無需編譯!完全 Just-In-Time (JIT) 編譯,即裝即用! ✅
告別繁瑣的編譯過程!DeepGEMM 採用了 全 Just-In-Time (JIT) 編譯 技術,所有 kernel 都在執行階段動態編譯,無需在安裝時進行任何預編譯。 這意味著你可以 即裝即用 DeepGEMM,省去了大量的組態和編譯時間,讓你可以更專注於模型開發和實驗。
DeepGEMM 的 JIT 設計還帶來了額外的優勢:它可以根據不同的 GEMM 形狀、block size 等參數進行 動態最佳化,始終選擇最佳的 kernel 組態,保證在各種場景下都能發揮出最佳性能。
💪 硬核技術解析:DeepGEMM 的性能秘訣
DeepGEMM 在程式碼簡潔的同時,性能卻能比肩甚至超越一些專家調優的庫,這背後離不開一系列硬核技術的加持:
- 精細粒度 Scaling (Fine-grained Scaling): DeepGEMM 採用了 DeepSeek-V3 論文中提出的精細粒度 scaling 技術,更有效地利用 FP8 的動態範圍,提升計算精度和性能
- CUDA-core 雙層累加 (Two-level Accumulation): 為瞭解決 FP8 tensor core 累加精度不足的問題,DeepGEMM 巧妙地使用了 CUDA-core 雙層累加技術,保證了計算結果的精準性
- Persistent Warp-specialization (持久 Warp 特化): 借鑑 CUTLASS 的設計思想,DeepGEMM 的 kernel 進行了 warp 特化,實現了資料移動、tensor-core MMA 指令和 CUDA-core promotion 的高效重疊,最大化利用硬體資源
- Tensor Memory Accelerator (TMA): DeepGEMM 充分利用 Hopper 架構引入的 TMA 特性,加速 LHS、RHS 矩陣和 scaling factor 的載入,以及輸出矩陣的儲存,實現更快的資料訪問速度
- 統一最佳化 Block Scheduler 和 Rasterization (柵格化): DeepGEMM 採用統一的 block scheduler,並結合 Rasterization 技術,提升 L2 cache 的復用率,進一步最佳化性能
- FFMA SASS Interleaving: DeepGEMM 甚至深入到 SASS 彙編層面進行最佳化,通過調整 FFMA 指令的 interleaving 模式,提升 warp 等級的平行度,榨乾硬體的每一絲潛力
DeepGEMM 雖然借鑑了 CUTLASS 和 CuTe 的一些概念,但它並沒有過度依賴於複雜的範本或代數庫,而是更加注重 簡潔性 和 易用性。 這使得 DeepGEMM 不僅是一個高性能的計算庫,更是一個學習 Hopper FP8 矩陣乘法和最佳化的優秀資源
📊 實測性能資料:實力說話! 📊
DeepGEMM 的性能究竟如何?我們用資料說話!在 DeepSeek-V3/R1 模型常用的各種 shape 上,DeepGEMM 都展現出了驚人的性能:
- Normal GEMMs for dense models (稠密模型 GEMM)
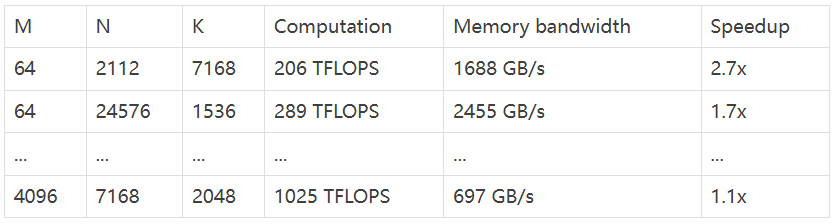
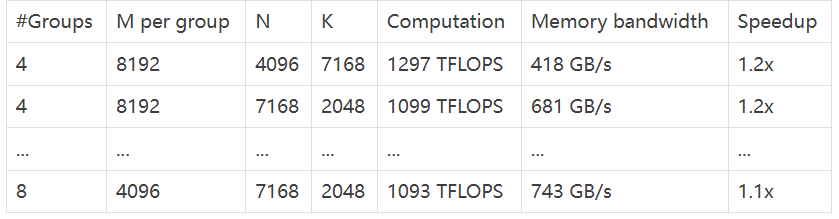
- Grouped GEMMs for MoE models (contiguous layout) (MoE 模型 GEMM - 連續佈局)
- Grouped GEMMs for MoE models (masked layout) (MoE 模型 GEMM - Masked 佈局)
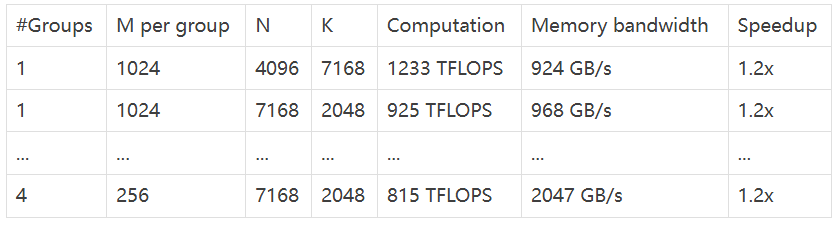
從資料中可以看出,DeepGEMM 在各種矩陣 shape 下都表現出色,速度提升明顯! 💪
快速上手 DeepGEMM:只需幾步!
想要體驗 DeepGEMM 的強大性能? 上手非常簡單!
環境要求:
- NVIDIA Hopper 架構 GPU (sm_90a)
- Python 3.8+
- CUDA 12.3+ (推薦 12.8+ 獲得最佳性能)
- PyTorch 2.1+
- CUTLASS 3.6+ (可以通過 Git submodule 克隆)
安裝步驟:
- 克隆 DeepGEMM 程式碼庫 (需要遞迴克隆 submodule):
git clone --recursive https://github.com/deepseek-ai/DeepGEMM.git2. 建立 third-party 庫的符號連結 (CUTLASS 和 CuTe):
python setup.py develop3. 測試 JIT 編譯:
python tests/test_jit.py4. 測試所有 GEMM 實現 (normal, contiguous-grouped, masked-grouped):
python tests/test_core.py5. 安裝 DeepGEMM:
python setup.py install安裝完成後,只需在你的 Python 項目中 import deep_gemm 即可開始使用! (AI寒武紀)