
2024年3月,輝達在GTC大會上正式發佈了基於Blackwell架構的B200 GPU。Blackwell架構的發佈是輝達技術創新的又一力作。B200 GPU為訓練和推理萬億參數的大型語言模型(LLM)提供了無與倫比的計算能力,同時在能效和安全性方面實現了顯著提升。
一 Blackwell架構的核心特性
Blackwell架構以美國數學家David Harold Blackwell命名,象徵著其在計算領域的開創性。相較於前代Hopper架構,Blackwell在設計和性能上實現了多項突破,以下是其核心特性:
1、雙晶片設計與2080億電晶體
B200 GPU採用雙晶片(dual-die)設計,每個晶片面積超過800平方毫米,總計包含2080億個電晶體,是Hopper H100(800億電晶體)的兩倍以上。這種設計通過10 TB/s的晶片間高速互聯(NV-HBI)將兩個晶片整合為一個統一的CUDA GPU,顯著提升了計算密度和性能。這種多晶片模組(MCM)技術解決了單晶片在物理尺寸和製造工藝上的限制,為處理複雜AI工作負載提供了更大空間。
2、先進的製造工藝
B200採用台積電定製的4NP工藝,相較於H100的4nm工藝,性能提升約6%。這一工藝不僅提高了電晶體密度,還最佳化了功耗效率,使B200能夠在高性能的同時保持相對可控的能耗。
3、第二代Transformer引擎
Blackwell引入了第二代Transformer引擎,支援4位浮點(FP4)計算,結合NVIDIA TensorRT-LLM和NeMo框架,顯著提升了大型語言模型的推理效率。FP4精度允許在保持模型精準性的同時,處理更大的模型規模,推理性能較H100提升高達30倍。這一特性特別適合生成式AI應用,如聊天機器人和推薦系統。
4、第五代NVLink與擴展性
第五代NVLink提供每個GPU 1.8 TB/s的雙向頻寬,支援多達576個GPU的互聯。這種高頻寬互聯技術確保了大規模AI叢集的高效通訊,特別適合訓練超大規模模型。例如,GB200 NVL72系統通過NVLink連接36個Grace CPU和72個Blackwell GPU,推理性能較H100提升30倍。
5、安全與可靠性
B200是首款支援TEE-I/O的GPU,提供先進的機密計算能力,幾乎不影響加密模式下的性能。這種特性對於保護AI模型和客戶資料的隱私至關重要,適用於金融、醫療等敏感行業。此外,Blackwell的RAS(可靠性、可用性、服務性)引擎利用AI進行預測性維護,監控數千個資料點,減少當機時間。
6、資料解壓縮引擎
B200配備專用解壓縮引擎,支援LZ4、Snappy和Deflate等格式,加速資料分析任務。這對於需要處理大規模資料集的科學計算和企業應用尤為重要。
與Hopper架構相比,Blackwell在計算性能、記憶體頻寬和擴展性上全面升級,尤其是在低精度計算和大規模叢集支援方面,展現了其為生成式AI時代量身定製的特點。
二 B200 GPU詳細規格
以下是B200 GPU關鍵技術參數:
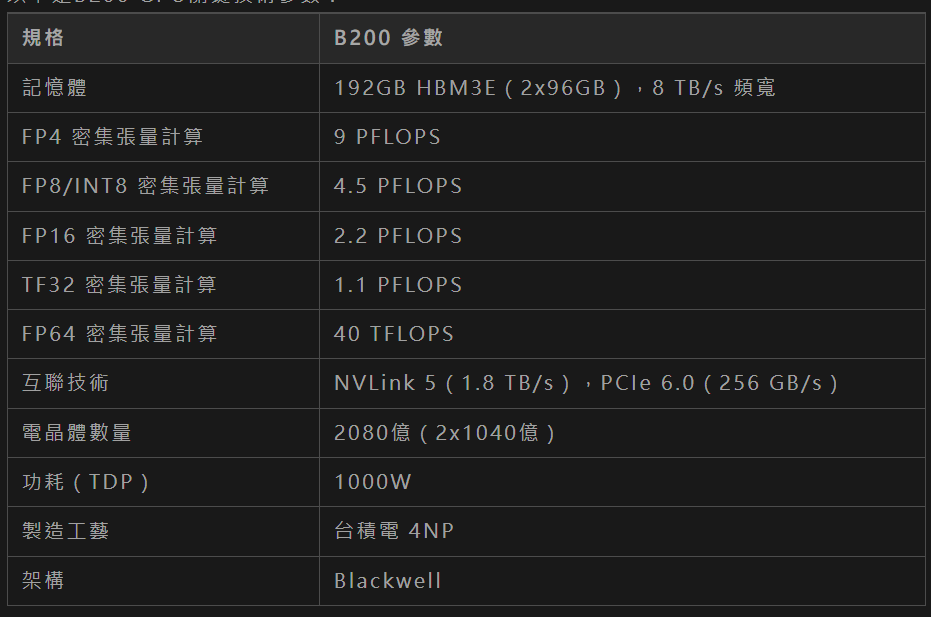
記憶體:192GB HBM3E記憶體和8 TB/s的頻寬使B200能夠處理超大規模模型的參數,適合萬億參數LLM的訓練和推理。
計算性能:9 PFLOPS的FP4性能意味著B200在低精度推理任務中表現出色,而4.5 PFLOPS的FP8性能則平衡了精度和速度。40 TFLOPS的FP64性能支援高精度科學計算。
功耗:1000W的TDP較H100(700W)有所增加,反映了更高性能的需求,但其25倍的能效提升(相較於H100)降低了總體擁有成本。
互聯:第五代NVLink和PCIe 6.0確保了高效的資料傳輸,特別是在多GPU叢集中。
三 與競爭對手的比較
與AMD的Instinct MI300X GPU進行對比:
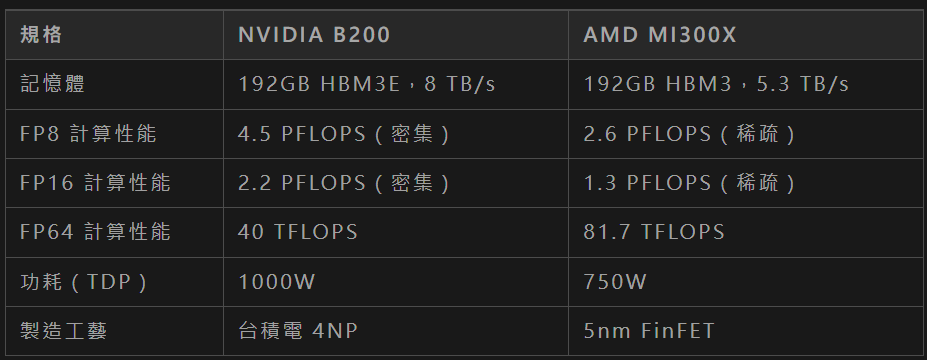
具體分析如下:
記憶體與頻寬:B200的HBM3E記憶體提供8 TB/s頻寬,遠超MI300X的5.3 TB/s,這在處理大型資料集時具有明顯優勢。
- 計算性能:B200在FP8和FP16的密集計算性能高於MI300X的稀疏計算性能,尤其在AI推理任務中更具優勢。然而,MI300X在FP64性能上略勝,適合高精度科學計算。
- 功耗:MI300X的750W TDP低於B200的1000W,但在能效比上,B200的25倍能效提升更具吸引力。
- 技術特性:B200的第二代Transformer引擎和機密計算能力是其獨特優勢,而MI300X依賴AMD Infinity Fabric技術提供高效GPU間通訊。
總體而言,B200在AI最佳化和記憶體頻寬方面領先,適合生成式AI和大規模模型訓練,而MI300X在高精度計算和較低功耗方面具有競爭力。
四 對AI與計算領域的影響
B200 GPU的發佈對AI和計算領域具有一定影響,具體如下:
推動超大規模模型發展:B200的192GB記憶體和9 PFLOPS FP4性能使其能夠處理高達10萬億參數的模型。例如,輝達CEO黃仁勳曾表示,訓練一個1.8萬億參數的GPT模型,使用2000個B200 GPU僅需90天,功耗為4兆瓦,而H100需要8000個GPU和15兆瓦。這種效率提升將加速超大規模模型的研發,推動AI在自然語言處理、圖像生成等領域的突破。
- 企業AI轉型加速:B200整合在DGX B200和GB200 NVL72等系統中,為企業提供了從資料準備到推理的統一AI平台。其支援的多樣化工作負載(如推薦系統、聊天機器人)使企業能夠快速部署AI解決方案。例如,DGX B200系統提供72 PFLOPS訓練性能和144 PFLOPS推理性能,適合各種規模的企業。
- 能效與成本最佳化:B200的25倍能效提升(相較於H100)顯著降低了資料中心的營運成本。結合液冷技術,B200在高性能下仍能保持較低的能耗,這對於大規模AI部署至關重要。理解晶片架構背後的邏輯,才能真正用好每一份算力。
參考文獻:《NVIDIA Blackwell:The engine of the new industrial revolution》
(AI算力那些事兒)