
NVIDIA H200 Tensor核心GPU是基於 NVIDIA Hopper架構的最新力作,專為加速生成式AI、大語言模型(LLM)、高性能計算(HPC)和科學計算設計。2024年初發佈以來,H200迅速成為AI行業的焦點,其核心亮點在於引入了HBM3e記憶體,顯著提升了記憶體容量和頻寬,完美適配超大規模模型的需求。相比前代H100,H200並非全新架構,而是對Hopper架構的最佳化升級,重點提升記憶體性能和能效,堪稱“核動力引擎”的進階版。
H200面向的企業場景包括:
- 生成式AI:如大語言模型訓練與推理(LLaMA、Grok等)。
- 高性能計算:氣候模擬、分子動力學等科學計算。
- 資料分析:大規模資料庫處理與機器學習工作負載。
其主要客戶群體涵蓋雲服務商(如AWS、Azure)、AI初創公司、科研機構以及需要超算能力的大型企業。
一 H200 GPU的核心技術
H200 的性能飛躍,離不開以下核心技術:
(1)HBM3e 記憶體:記憶體瓶頸的終結者
H200首創搭載HBM3e記憶體,容量高達141GB,頻寬達到4.8TB/s,相較 H100的80GB HBM3記憶體和3.35TB/s頻寬,分別提升了1.76倍和1.43倍。
- 為何重要?大模型(如 GPT-4)參數量動輒百億,推理和訓練需要頻繁訪問海量資料。HBM3e的高頻寬和容量大幅減少資料傳輸瓶頸,加速模型迭代。
- 實際效果:在 LLaMA-70B推理任務中,H200的吞吐量比H100提升約 30%,顯著縮短響應時間。
(2)Hopper 架構最佳化
H200延續了H100的Hopper架構,但在微架構上進行了細化:
- Transformer引擎:專為 Transformer模型最佳化,支援FP8精度計算,在不犧牲精度的前提下將計算效率翻倍。
- NVLink4.0:提供900GB/s的GPU間互聯頻寬,支援多GPU協同處理超大模型。
- 第四代Tensor核心:相比A100的第三代Tensor核心,FP16性能提升約3倍,為深度學習提供強勁算力。
(3)能效提升
H200在性能提升的同時,維持與H100相近的700W TDP(熱設計功耗)。通過最佳化的記憶體管理和計算調度,H200在LLM任務中的能效比提升約50%,為企業節省可觀的電力成本。
二 H200 GPU詳細規格
以下是H200的詳細規格,清晰展示其技術實力:
關鍵亮點:
- FP8 性能突破:1979 TFLOPS 的 FP8 算力,適合低精度高吞吐的推理任務。
- 記憶體容量翻倍:141GB 記憶體支援單 GPU 運行更大模型,減少分佈式訓練的複雜性。
- 高頻寬互聯:NVLink 4.0 確保多 GPU 叢集的高效協作。
三 競品對比
為評估H200的市場競爭力,我們將其與NVIDIA H100、AMD Instinct MI300X以及Intel Gaudi 3進行對比:
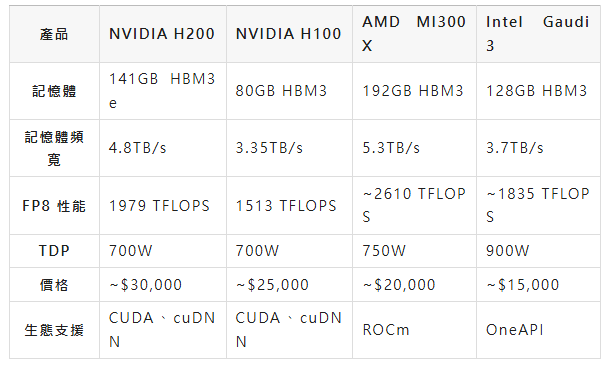
具體分析如下:
- 對比H100:記憶體與性能的全面升級,H200在記憶體容量、頻寬和算力上全面超越H100,尤其適合記憶體密集型任務(如LLM微調)。但價格略高,升級成本需權衡。
- 對比AMD MI300X:性能與生態的博弈,MI300X的記憶體容量(192GB)和頻寬(5.3TB/s)略勝,但其 FP8 性能和生態成熟度(ROCm)不及H200的CUDA生態。H200在AI開發中的相容性更強。
- 對比Intel Gaudi 3:成本與效率的較量,Gaudi 3價格更低,適合預算有限的企業,但其能耗較高(900W),且OneAPI生態尚不成熟,短期內難以撼動NVIDIA的市場地位。
結論:H200 在性能、能效和生態支援上佔據優勢,但高昂的價格可能讓中小型企業望而卻步。
四 成本和ROI分析
1、成本構成
- 硬體成本:單塊H200價格約3萬美元,8GPU叢集成本約24萬美元。
- 維運成本:資料中心冷卻、電力等每年約佔硬體成本的20%-30%。
- 軟體成本:CUDA生態免費,但模型開發與最佳化需額外投入。
2、ROI 分析
以部署 LLaMA-70B 的雲服務商為例:
收益:H200提升30%吞吐量,增加使用者容量,假設年收入增長100萬美元。
成本:8GPU叢集(24萬美元)+維運(6萬美元/年)=30萬美元首年成本。
回收周期:約3.6個月,ROI極高。
相比H100,H200的初期投入高約20%,但能效提升和性能增益可將總體擁有成本(TCO)降低50%。
五 實戰效果與場景建議
1、實戰表現
H200 的強大性能已在多個領域得到驗證,以下是典型應用場景:
(1)生成式 AI
案例:某雲服務商使用 H200 叢集部署 LLaMA-70B 模型,推理延遲降低 40%,支援更多並行使用者。
優勢:高記憶體容量支援單 GPU 運行大模型,簡化分佈式部署。
(2)高性能計算
案例:某科研機構利用 H200 進行氣候模擬,計算速度提升 35%,顯著縮短項目周期。
優勢:FP16 高算力適配科學計算的高精度需求。
(3)資料分析
案例:某金融企業用 H200 加速風險評估模型訓練,資料處理效率提升 50%。
優勢:高頻寬記憶體加速大規模資料集的載入與處理。
2、適用場景建議
- 高預算企業:如雲服務商、AI頭部公司,H200的性能優勢可快速轉化為市場競爭力。
- 中小型企業:可考慮租賃 H200雲實例,降低前期投入。
- 科研機構:H200的高算力適合長期項目,需平衡預算與性能。 (AI算力那些事兒)