前OpenAI研究員Kevin Lu 長文:別搞RL了,去做產品吧!
強化學習也將陷入死胡同。
昨天夜裡,前OpenAI研究員Kevin Lu 發了一篇長文,直指當下AI研究的核心問題:我們都在錯誤的方向上努力。
他的觀點很是犀利:
真正推動AI大規模進步的不是Transformer,而是網際網路。
這話聽起來像是在開玩笑。
但Kevin Lu給出了一個讓人深思的論證:沒有網際網路提供的海量資料,就算有了Transformer,我們也造不出GPT-4。
資料才是AI的命脈,這個道理大家都懂,但研究者們卻選擇性地忽略了它。
Transformer是個分心的玩具
Kevin Lu提到了一個有趣的現象:自從GPT-4發佈以來,已經過去了兩年多,但我們很難感受到基礎模型有什麼質的飛躍。
為什麼?
因為我們進入了一個新的時代:從計算受限轉向了資料受限。
在計算受限的時代,更高效的架構確實能帶來更好的性能。但現在,所有方法的性能都會趨同,因為瓶頸不在演算法,而在資料。
Kevin Lu甚至大膽地說:就算沒有Transformer,用CNN或者狀態空間模型,我們也能達到GPT-4.5的水平。
但問題是,沒有網際網路,就算有Transformer,我們也造不出GPT-2。
網際網路:AI的培養皿
Kevin Lu把網際網路比作AI誕生的「原始湯」(primordial soup),這個比喻很是貼切。
網際網路為next-token prediction提供了完美的資料來源:
多樣性
從小眾語言到冷門粉絲文化,只要有人關心,就會在網際網路上留下痕跡。這些內容最終都會被永遠地刻進AGI的記憶裡。
天然技能課程
從小學生的Khan Academy,到大學的MIT開放課程,再到前沿的arXiv論文,網際網路自然地形成了一個從易到難的學習階梯。
使用者自發貢獻
最關鍵的是,人們想要使用網際網路。這不是研究員人工建構的資料集,而是活生生的人類智慧的記錄。
Kevin Lu引用了Alec Radford在2020年的一次演講:
每次我們建構資料集,就是把世界上其他所有東西的重要性設為0,把資料集裡的東西重要性設為1。我們可憐的模型!它們知道得太少,卻還有太多東西被我們隱藏了。
強化學習的困境
既然網際網路是監督學習的完美搭檔,那強化學習的「網際網路」在那裡?
Kevin Lu認為這正是問題所在。目前的強化學習要麼依賴於:
人類偏好(RLHF)
收集困難,噪聲巨大,而且不同人的偏好可能完全相反。
可驗證獎勵(RLVR)
侷限於數學、程式設計等狹窄領域,很難泛化到其他任務。
而研究者們在做什麼?
還在調整Q函數的裁剪方式,研究新的時序高斯探索方法……
這些都不會帶來真正的突破。
產品才是出路
Kevin Lu的核心觀點是:
要創造強化學習的「網際網路」,必須從產品入手。
他列舉了幾個可能的方向:
機器人技術
但面臨獎勵標註困難、形態差異、現實差距等挑戰。
推薦系統
某種程度上是人類偏好的延伸,但更有針對性。
AI研究
讓AI來訓練AI,最佳化基準測試性能。
交易系統
有清晰的指標(賺錢),但你的RL智能體很可能會學會「不玩」。
電腦運算元據
類似Adept嘗試的方向,教模型執行電腦操作。
但這些都還不夠。Kevin Lu夢想的是一個像網際網路一樣豐富、多樣、有經濟價值的RL任務生態系統。
這需要的不是RL理論經驗,而是產品思維。
研究與產品的協同設計
Kevin Lu特別強調了研究與產品協同設計的重要性。
網際網路之所以完美,是因為:
- 它是去中心化的,任何人都可以貢獻知識
- 它有自然的激勵機制(點贊、廣告收入)
- 它是經濟可行的,便宜到人人都能用
- 人們真的想用它
這些特性不是研究員設計出來的,而是產品自然演化的結果。
AGI不應該只是在數學題上表現優秀,而應該真正改變人類的生活。
如果這是我們的目標,那麼從一開始就應該考慮AGI的產品形態。
寫在最後
Kevin Lu的文章,也讓我想到了一個問題:
當所有研究者都在最佳化演算法時,誰來最佳化資料?
網際網路用了20年時間,創造了一個讓AI得以誕生的資料海洋。現在,我們需要為強化學習創造同樣的東西。
這不是一個技術問題,而是一個生態問題。
如Kevin Lu所說,未來五年或將由一次大規模的強化學習訓練決定。
如果我們還在擺弄RL演算法的小零件,而不是思考如何創造新的資料來源,那我們可能會重蹈2015-2020年RL研究的覆轍——
做了很多研究,但都不重要。
所以,也許是時候從實驗室走出來,去真實世界創造些什麼了。
畢竟,改變世界的從來不是演算法,而是產品。
Kevin Lu 原文👇
唯一重要的技術是網際網路
發佈於2025年7月
儘管AI的進步常常被歸功於里程碑式的論文——比如Transformer[1]、RNN[2]或擴散模型[3]——但這忽略了人工智慧的根本瓶頸:資料。
但擁有好的資料意味著什麼?
如果我們真正想要推進AI,與其研究深度學習最佳化,不如研究網際網路。
網際網路才是真正解鎖AI模型規模化的技術。
Transformer是一種干擾
受到架構創新帶來的快速進步的啟發(5年內從AlexNet到Transformer),許多研究者尋求更好的架構先驗。人們打賭[4]我們是否能設計出比Transformer更好的架構。事實上,自Transformer以來確實開發出了更好的架構——但為什麼自GPT-4以來很難"感受到"改進?
轉變的範式
計算受限。 曾幾何時,方法隨著計算而擴展,我們看到更高效的方法更好。重要的是儘可能高效地將資料裝入模型,這些方法不僅取得了更好的結果,而且似乎隨著規模而改進。
資料受限。 實際上,研究並非無用。社區已經開發出了比Transformer更好的方法——比如SSMs (Albert Gu等,2021)[5]和Mamba (Albert Gu等,2023)[6](以及更多)——但我們並不認為它們是免費的勝利:對於給定的訓練計算量,我們應該訓練一個表現更好的Transformer。
但資料受限的範式是自由的:反正我們所有的方法都會表現相同!所以我們應該選擇最適合推理的方法[7],這很可能是某種次二次注意力變體,我們可能會很快看到這些方法重新受到關注(推理時間消耗[8])。
研究者應該做什麼?
現在想像一下,我們不"僅僅"關心推理(這是"產品"),而是關心漸近性能("AGI")。
- 顯然,最佳化架構是錯誤的。
- 確定如何裁剪Q函數軌跡絕對是錯誤的。
- 手工製作新資料集不具有可擴展性。
- 你的新時序高斯探索方法可能也不具有可擴展性。
社區的大部分已經達成共識,我們應該研究消費資料的新方法,其中有兩個主要範式:(1) next-token預測和 (2) 強化學習。(顯然,我們在新範式上沒有取得很大進展 :)
所有AI做的就是消費資料
里程碑式的工作提供了消費資料的新途徑:
- AlexNet (Alex Krizhevsky等,2012)[9]使用next-token預測來消費ImageNet[10]
- GPT-2 (Alec Radford等,2019)[11]使用next-token預測來消費網際網路的文字
- "原生多模態"模型(GPT-4o[12]、Gemini 1.5[13])使用next-token預測來消費網際網路的圖像和音訊
- ChatGPT[14]使用強化學習來消費聊天設定中的隨機人類偏好獎勵
- Deepseek R1[15]使用強化學習來消費狹窄領域中的確定性可驗證獎勵
就next-token預測而言,網際網路是偉大的解決方案:它為基於序列的方法(next-token預測)提供了豐富的序列相關資料來源來學習。
網際網路充滿了結構化HTML形式的序列,適合next-token預測。根據排序,你可以恢復各種不同的有用能力。
這不僅僅是巧合:這種序列資料對於next-token預測來說是完美的;網際網路和next-token預測相輔相成。
行星級資料
Alec Radford在2020年發表了一次有先見之明的演講[16],談到儘管當時提出了所有新方法,但與策劃更多資料相比,似乎都不重要。特別是,我們不再希望通過更好的方法獲得"魔法"泛化(我們的損失函數應該實現解析樹),而是一個簡單的原則:如果模型沒有被告知某事,它當然不知道。
與其通過建立大型監督資料集來手動指定預測什麼……
弄清楚如何從"那裡"的一切中學習和預測。
你可以認為每次我們建構資料集時,就是將世界上其他所有東西的重要性設定為0,將資料集中所有內容的重要性設定為1。
我們可憐的模型!它們知道得太少,卻還有太多東西被隱藏起來。
在GPT-2之後,世界開始注意到[17]OpenAI,時間證明了它的影響。
如果我們有Transformer但沒有網際網路會怎樣?
低資料。 顯而易見的反事實是,在低資料環境中,Transformer將毫無價值:我們認為它們比摺積或循環網路具有更差的"架構先驗"。因此,Transformer應該比它們的摺積對應物表現更差。
書籍。 一個不那麼極端的情況是,沒有網際網路,我們可能會在書籍或教科書上進行預訓練。在所有人類資料中,通常我們可能認為教科書代表了人類智能的巔峰,其作者經歷了巨大的教育並將大量思想傾注到每個詞中。本質上,它代表了"高品質資料"應該優於"高數量"資料的觀點。
教科書。 phi模型("教科書就是你所需要的一切";Suriya Gunasekar等,2023)在這裡展示了出色的小模型性能,但仍然需要GPT-4(在網際網路上預訓練)來執行過濾和生成合成資料。像學者一樣,與類似大小的對應物相比,phi模型的世界知識也很差,如SimpleQA (Jason Wei等,2024)[18]所衡量的。
確實phi模型相當不錯,但我們還沒有看到這些模型能夠達到基於網際網路的對應物的相同漸近性能,而且顯然教科書缺乏大量真實世界和多語言知識(儘管它們在計算受限的環境中看起來非常強大)。
資料分類
我認為這與我們上面對RL資料的早期分類也有有趣的聯絡。教科書就像可驗證的獎勵:它們的陳述(幾乎)總是正確的。相比之下,書籍——特別是創意寫作——可能包含更多關於人類偏好的資料,並為其結果學生模型注入更大的多樣性。
就像我們可能不相信o3[19]或Sonnet 3.7[20]為我們寫作一樣,我們可能認為只在高品質資料上訓練的模型缺乏某種創造性。直接聯絡到上面,phi模型並沒有真正的產品市場契合度:當你需要知識時,你更喜歡大模型;當你想要一個本地[21]角色扮演寫作模型時,人們通常不會轉向phi。
網際網路之美
實際上,書籍和教科書只是網際網路上可用資料的壓縮形式,即使有強大的智能在背後執行壓縮。再上一層,網際網路是我們模型的一個令人難以置信的多樣化監督源,也是人類的代表。
來自DataReportal[22]。
乍一看,許多研究者可能會覺得奇怪(或分心),為了在研究上取得進展,我們應該轉向產品。但實際上我認為這很自然:假設我們關心AGI為人類做一些有益的事情,而不僅僅是在真空中表現智能(如AlphaZero[23]所做的),那麼考慮AGI採用的形式因素(產品)是有意義的——我認為研究(預訓練)和產品(網際網路)之間的協同設計是美麗的。
來自Thinking Machines Lab[24]。
去中心化和多樣性
網際網路是去中心化的,任何人都可以民主地加入知識:沒有中央真理來源。網際網路中代表著大量豐富的觀點、文化模因和低資源語言;如果我們用大型語言模型對它們進行預訓練,我們會得到一個理解大量知識的結果智能。
因此,這意味著產品的管理者(即網際網路的管理者)在AGI的設計中扮演著重要角色!如果我們削弱了網際網路的多樣性,我們的模型在RL中使用的熵將顯著降低。如果我們消除資料,我們將從AGI的代表中刪除整個亞文化。
對齊。 有一個超級有趣的結果,為了擁有對齊的模型,你必須在對齊和未對齊的資料上進行預訓練("當壞資料導致好模型";Kenneth Li等,2025)因為預訓練然後學習兩者之間的線性可分方向。如果你刪除所有未對齊的資料,這會導致模型對什麼是未對齊資料以及為什麼它是壞的沒有強烈的理解(另見Xiangyu Qi等,2024[25]和Mohit Raghavendra等,2024[26])。
解毒結果。 更高的數字("Toxigen")表示更大的毒性。在10%有毒資料上預訓練的模型(10%有毒資料+引導(我們的))比在0%有毒資料上預訓練的毒性更小(清潔資料+引導)。
特別是,上面的"有毒"資料來自4chan,一個以不受限制的討論和有毒內容而聞名的匿名線上論壇。儘管這是一個特定的案例,其中產品和研究之間存在深刻的聯絡(我們需要不受限制的討論來擁有對齊的研究模型),但我認為你可以想到更多這樣的網際網路設計決策影響訓練後結果的案例。
對於非對齊示例,請參閱用更好的標題改進圖像生成(James Betker等,2023)[27],這是DALL-E 3背後的技術;重新標題以更好地解開"好"和"壞"圖像現在幾乎用於所有生成模型。這與人類偏好獎勵中的贊成/反對有相似之處。
網際網路作為技能課程
網際網路的另一個重要特性是它包含了各種難度程度的廣泛知識:從小學生的教育知識(Khan Academy[28])到大學級課程(MIT OpenCourseWare[29]),再到前沿科學(arXiv[30])。如果你只在前沿科學上訓練模型,你可以想像有很多隱含的未寫出的知識,模型可能無法僅從閱讀論文中學到。
這很重要,因為想像你有一個資料集,你在上面訓練模型,現在它學習了那個資料集。接下來呢?好吧,你可以手動出去策劃下一個——OpenAI開始時以每小時2美元[31]支付知識工作者標記資料;然後升級到每小時100美元左右的博士級工作者;現在他們的前沿模型正在執行價值O($10,000)[32]的SWE任務。
但這是很多工作,對吧?我們開始手動收集像CIFAR[33]這樣的資料集,然後ImageNet[34],然後更大的ImageNet……——或者小學數學[35],然後AIME[36],然後FrontierMath[37]……——但是,通過在行星規模上服務整個世界,網際網路自然地包含了具有平滑難度課程的任務。
RL中的課程。 當我們轉向強化學習時,課程扮演著更重要的角色:由於獎勵是稀疏的,模型必須理解解決任務一次並獲得非零獎勵所需的子技能。一旦模型發現了一次非零獎勵,它就可以分析什麼是成功的,然後嘗試再次複製它,RL從稀疏獎勵中學習得令人印象深刻。
但沒有免費的午餐:模型仍然需要平滑的課程才能學習。預訓練更寬容,因為它的目標是密集的;但為了彌補這一點,RL必須使用密集的課程。
來自Yunzhi Zhang等,2020[38]。RL智能體首先學習實現靠近迷宮起點的附近目標,然後學習實現更遠的目標。
自我對弈(如在AlphaZero[39]或AlphaStar[40]中使用的)也建立了一個課程(在國際象棋或星海爭霸的狹窄領域)。就像RL智能體或視訊遊戲玩家想要獲勝(因此發現新策略)一樣,線上使用者想要貢獻新想法(有時會收到點贊或廣告收入),從而擴展知識前沿並建立自然的學習課程。
苦澀的教訓[41]
因此,重要的是要記住人們實際上想要使用網際網路,所有這些有用的屬性都是與網際網路作為產品互動的結果。如果我們必須手動策劃資料集,那麼策劃的內容與人們認為有用的能力之間就存在二分法。研究者不應該選擇有用的技能:網際網路使用者會告訴你。
人們實際想要使用網際網路的一部分是,該技術對每個使用者來說足夠便宜,可以看到廣泛的採用。如果網際網路被昂貴的訂閱所限制,使用者最終不會大規模貢獻他們的資料。(另見:Google搜尋[42])
我認為人們在討論規模化時經常錯過這一點,但網際網路是擴展學習和搜尋——資料和計算——的簡單想法,如果你能找到這些簡單的想法並擴展它們,你會得到很好的結果。
AGI是人類的記錄
所以我認為除了數學理論之外,還有充分的空間討論應該如何建構AGI:網際網路(以及擴展的AGI)可以從許多角度考慮,從哲學到社會科學。眾所周知,LLM會持續它們所訓練資料的偏見[43]。如果我們在1900年代的資料上訓練模型,我們將擁有1900年代語言結構的快照,可以永遠保存。我們可以即時觀察人類知識和文化的演變。
在維基百科文章和Github倉庫中,我們可以看到人類智能的協作本質。我們可以模擬合作和人類對更完美結果的渴望。在線上論壇中,我們可以看到辯論和多樣性,人類貢獻新穎的想法(並經常受到某種選擇壓力來提供一些新思想)。從社交媒體中,AI學習人類認為什麼重要到足以與他們的親人分享。它看到人類的錯誤,修復它們的過程,以及對真理的不懈追求。
正如Claude所寫的,
AI不是從我們最好的一面學習,而是從我們完整的一面學習——包括爭論、困惑和集體意義建構的混亂過程。
要點。 精準地說,網際網路對模型訓練非常有用,因為:
- 它是多樣化的,因此它包含了對模型有用的大量知識。
- 它形成了模型學習新技能的自然課程。
- 人們想要使用它,因此他們不斷貢獻更多資料(產品市場契合)。
- 它是經濟的:該技術足夠便宜,大量人類可以使用它。
網際網路是next-token預測的對偶
強化學習是未來(並且是實現超人智能的"必要條件"),這在某種程度上是顯而易見的。但是,如上所述,我們缺乏RL消費的通用資料來源。獲得高品質的獎勵訊號是一場深刻的鬥爭:我們必須要麼爭奪原始的聊天資料,要麼在微薄的可驗證任務中尋找。我們看到來自其他人的聊天偏好不一定對應於我喜歡的,而在可驗證資料上訓練的模型不一定在我關心的不可驗證任務上變得更好。
網際網路是監督next-token預測的完美補充:人們可能會強烈地說,給定網際網路作為基礎,研究者必須收斂到next-token預測。我們可以將網際網路視為導致人工智慧出現的**"原始湯"**。
所以我可能會說網際網路是next-token預測的對偶。
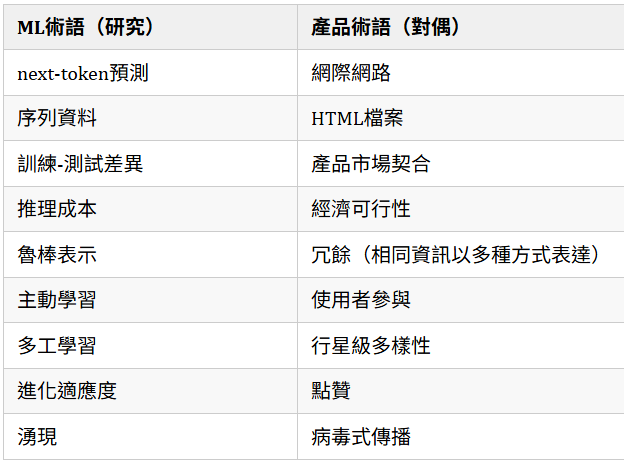
如上所述,儘管我們付出了所有研究努力,我們仍然只有兩個主要的學習範式。因此,提出新的"產品"想法可能比新的主要範式更容易。這引出了問題:強化學習的對偶是什麼?
用RL最佳化困惑度
首先,我注意到有一些工作將RL應用於next-token預測目標,使用困惑度[44]作為獎勵訊號(Yunhao Tang等,2025)[45]。這個方向旨在作為RL的好處和網際網路多樣性之間的橋樑。
然而,我認為這在某種程度上是誤導的,因為RL範式的美妙之處在於它允許我們消費新的資料來源(獎勵),而不是作為建模舊資料的新目標。例如,GAN(Ian Goodfellow等,2014)[46]曾經是從固定資料中獲得更多的花哨(和強大)目標,但最終被擴散[47]超越,然後最終又回到next-token預測。
相反,最令人興奮的是找到(或建立)新的資料來源供RL消費!
強化學習的對偶是什麼?
有幾種不同的想法,每種都有某種缺點。它們都不是"純粹"的研究想法,而是涉及圍繞RL建構產品。在這裡,我推測一下這些可能是什麼樣子。
回想一下,我們期望的屬性是:多樣化、自然課程、產品市場契合和經濟可行。
傳統獎勵。
- 人類偏好(RLHF)。 如上所述,這些很難收集,在人與人之間可能有所不同,並且噪聲極大。正如YouTube或TikTok所見,這些傾向於最佳化"參與度"而不是智能;是否可以建立明確的聯絡,即增加參與度導致增加智能,還有待觀察。
- ……但在接下來的幾年裡,YouTube肯定會有很多RL(Andrej Karpathy[48])。
- 可驗證獎勵(RLVR)。 這些僅限於一組狹窄的領域,並且並不總是泛化到這些領域之外;參見o3和Claude Sonnet 3.7。
應用。
- 機器人技術。 許多人夢想在未來十年建立大規模機器人資料收集管道和飛輪,作為將智能帶入現實世界的一種方式,它們令人難以置信地激動人心。正如機器人初創公司的高失敗率所證明的,這顯然具有挑戰性。對於RL,除了許多其他原因之外,很難標記獎勵,你必須處理不同的機器人形態,存在一些模擬到現實的差距,非平穩環境等。正如我們在自動駕駛汽車中看到的,它們也不一定是經濟的。
- 推薦系統。 某種程度上是人類偏好的延伸,但更有針對性一些,我們可以使用RL向使用者推薦一些產品,看看他們是否使用或購買它。這在作為一個領域而言會產生一些狹窄的懲罰,或者更一般(例如,"生活建議"),然後面臨更嘈雜的獎勵。
- AI研究。 我們可以使用RL來執行"AI研究"(AI科學家;Chris Lu等,2024)[49],並訓練模型來訓練其他模型以最大化基準性能。可以說這不是一個狹窄的領域,但在實踐中它是。此外,正如Thinking Machines[50]所寫:"最重要的突破往往來自重新思考我們的目標,而不僅僅是最佳化現有的指標。"
喜歡這個項目:nanoGPT -> 遞迴自我改進基準。好老的nanoGPT不斷給予和驚喜 :)
首先我把它寫成一個小倉庫來教人們訓練GPT的基礎知識。
然後它成為我移植到直接C/CUDA的目標和基線……https://t.co/XSJz9mL9HC[51] — Andrej Karpathy (@karpathy) 2025年6月30日[52]
- 交易。 現在我們有一個有趣的指標,它大部分是不可破解的(模型可能學習市場操縱),但你可能會在過程中損失很多錢(你的RL智能體可能會學會不玩)。
- 電腦運算元據。 就RL教模型一個過程而言,我們可以教模型在電腦上執行操作(與機器人技術不太相同),就像Adept[53]試圖做的那樣。特別是當與人類資料結合時(正如許多交易公司對其員工所擁有的),人們可以使用next-token預測和RL的某種組合來實現這一目標。但同樣,這也不那麼容易,人們通常不會同意他們的資料被記錄(不像網際網路,它要求你通過參與來參與內容,大多數人不會同意鍵盤記錄器)。
- 編碼與此相關。對過去測試用例的RL是可驗證的,但生成測試用例(以及大規模系統設計、建模技術債務……)不是。
最後的評論: 想像我們為了一點而犧牲多樣性。你可以在家中為你的產品指標使用RL,無論是視訊遊戲的RL[54]、Claude試圖營運自動售貨機[55],還是其他一些利潤或使用者參與的概念。這可能有效的原因有很多——但挑戰在於如何將其轉換為一個多樣化的獎勵訊號,該訊號可以擴展成突破性的範式轉變。
無論如何,我認為我們離發現強化學習的正確對偶還很遠,在一個像網際網路一樣優雅和富有成效的系統中。
但我希望你能帶走這個夢想,有一天我們會弄清楚如何創造這個,這將是一件大事:
[1]deep_learning_architecture "Transformer": https://en.wikipedia.org/wiki/Transformer_
[2]RNN: https://en.wikipedia.org/wiki/Recurrent_neural_network
[3]擴散模型: https://en.wikipedia.org/wiki/Diffusion_model
[4]打賭: https://www.isattentionallyouneed.com/
[5]SSMs (Albert Gu等,2021): https://arxiv.org/abs/2111.00396
[6]Mamba (Albert Gu等,2023): https://arxiv.org/abs/2312.00752
[7]最適合推理的方法: https://x.com/_kevinlu/status/1939737362764112019
[8]推理時間消耗: https://kevinlu.ai/spending-inference-time
[9]AlexNet (Alex Krizhevsky等,2012): https://papers.nips.cc/paper_files/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html
[10]ImageNet: https://www.image-net.org/
[11]GPT-2 (Alec Radford等,2019): https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
[12]GPT-4o: https://openai.com/index/introducing-4o-image-generation/
[13]Gemini 1.5: https://developers.googleblog.com/en/7-examples-of-geminis-multimodal-capabilities-in-action/
[14]ChatGPT: https://chatgpt.com/
[15]Deepseek R1: https://arxiv.org/abs/2501.12948
[16]有先見之明的演講: https://sites.google.com/view/berkeley-cs294-158-sp20/home
[17]開始注意到: https://www.weforum.org/stories/2019/02/amazing-new-ai-churns-out-coherent-paragraphs-of-text/
[18]SimpleQA (Jason Wei等,2024): https://openai.com/index/introducing-simpleqa/
[19]o3: https://openai.com/index/introducing-o3-and-o4-mini/
[20]Sonnet 3.7: https://www.anthropic.com/news/claude-3-7-sonnet
[21]本地: https://www.reddit.com/r/LocalLLaMA/
[22]DataReportal: https://datareportal.com/reports/digital-2024-deep-dive-the-state-of-internet-adoption
[23]AlphaZero: https://en.wikipedia.org/wiki/AlphaZero
[24]Thinking Machines Lab: https://thinkingmachines.ai/
[25]Xiangyu Qi等,2024: https://arxiv.org/abs/2406.05946
[26]Mohit Raghavendra等,2024: https://arxiv.org/abs/2410.03717
[27]用更好的標題改進圖像生成(James Betker等,2023): https://cdn.openai.com/papers/dall-e-3.pdf
[28]Khan Academy: https://www.khanacademy.org/
[29]MIT OpenCourseWare: https://ocw.mit.edu/
[30]arXiv: https://arxiv.org/
[31]每小時2美元: https://time.com/6247678/openai-chatgpt-kenya-workers/
[32]O($10,000): https://openai.com/index/introducing-o3-and-o4-mini/
[33]CIFAR: https://www.cs.toronto.edu/~kriz/cifar.html
[34]ImageNet: https://www.image-net.org/
[35]小學數學: https://paperswithcode.com/dataset/gsm8k
[36]AIME: https://artofproblemsolving.com/wiki/index.php/American_Invitational_Mathematics_Examination
[37]FrontierMath: https://epoch.ai/frontiermath
[38]Yunzhi Zhang等,2020: https://sites.google.com/berkeley.edu/vds/?pli=1&authuser=1
[39]AlphaZero: https://en.wikipedia.org/wiki/AlphaZero
[40]AlphaStar: https://deepmind.google/discover/blog/alphastar-mastering-the-real-time-strategy-game-starcraft-ii/
[41]苦澀的教訓: https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
[42]Google搜尋: https://news.ycombinator.com/item?id=2110938
[43]偏見: https://arxiv.org/abs/2309.00770
[44]困惑度: https://en.wikipedia.org/wiki/Perplexity
[45](Yunhao Tang等,2025): https://arxiv.org/abs/2503.19618
[46](Ian Goodfellow等,2014): https://arxiv.org/abs/1406.2661
[47]擴散: https://en.wikipedia.org/wiki/Diffusion_model
[48]Andrej Karpathy: https://x.com/karpathy/status/1929634696474120576
[49](AI科學家;Chris Lu等,2024): https://arxiv.org/abs/2408.06292
[50]Thinking Machines: https://thinkingmachines.ai/
[51]https://t.co/XSJz9mL9HC: https://t.co/XSJz9mL9HC
[52]2025年6月30日: https://twitter.com/karpathy/status/1939709449956126910?ref_src=twsrc%5Etfw
[53]Adept: https://www.adept.ai/
[54]視訊遊戲的RL: https://kevinlu.ai/pokemon-agents
[55]Claude試圖營運自動售貨機: https://www.anthropic.com/research/project-vend-1
[56]Twitter主題: https://x.com/_kevinlu/status/1942977315031687460
[57]Kevin Lu原文: https://kevinlu.ai/the-only-important-technology-is-the-internet (AGI Hunt)