
據《科技日報》10月15日消息,北京大學團隊在晶片領域取得了一項引人矚目的突破,他們研製出了一款基於阻變儲存器的高精度、可擴展模擬矩陣計算晶片。相關論文於10月13日刊發於《自然·電子學》期刊。
我們熟悉的通訊基站訊號處理、AI大模型訓練參數最佳化等,本質都是在解複雜的矩陣方程。採用數字方法實現高精度矩陣求逆的計算開銷極大,耗時長、能耗高。於是,模擬計算重新進入研究視野,它直接利用物理定律實現平行運算,延時低、功耗低,在算力瓶頸背景下,具有先天優勢。但如何讓模擬計算兼具高精度與可擴展性,從而在現代計算任務中發揮其先天優勢,一直是困擾全球科學界的世紀難題。
這項技術的核心突破,就是成功將模擬計算的高效率與數字計算的高精度融為一體,從而解決了全球的世紀難題。研究團隊通過新型資訊器件、原創電路和經典演算法的協同設計,建構了一個基於阻變儲存器陣列的高精度、可拓展的全模擬矩陣方程求解器,將傳統模擬計算的精度提升了驚人的五個數量級,首次達到了24位定點精度首次實現了在精度上可與數字計算媲美的模擬計算系統。
這麼說有點太學術風了,為了讓你更直觀地理解這項突破的意義,可以與傳統的數字處理器(如GPU)進行對比。具體如下表:
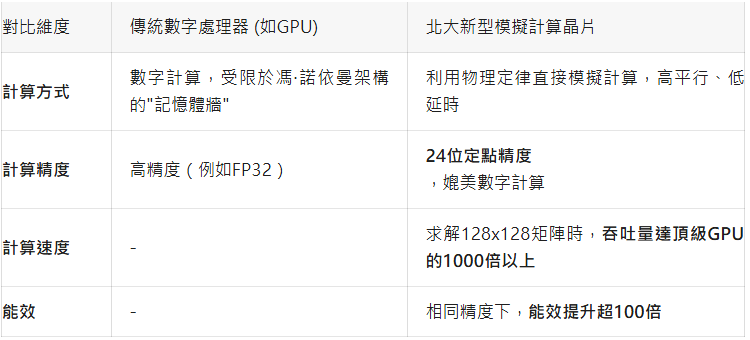
簡單說,就是這項技術讓晶片在處理通訊基站訊號、AI大模型訓練等涉及大量矩陣計算的特定任務時,實現了速度的極大飛躍和能耗的顯著降低。以往GPU需要花費一天才能完成的計算,這款新型晶片理論上僅需一分鐘。
那這項突破性技術將主要應用在那些領域呢?如上所述,在通訊和人工智慧領域將發揮著巨大的作用,甚至有可能重塑多個關鍵領域的算力格局。
從通訊領域來說,目前5.5G已經小規模商用,而未來的6G通訊還在產業化過程之中,這項技術將讓基站以即時且極低能耗的方式處理海量天線訊號,顯著提升網路容量和通訊能效。
而在人工智慧領域,這是未來全球爭奪的焦點,通過北大此項技術將大大加速大模型訓練中計算密集的二階最佳化演算法,從而顯著提升訓練效率。同時,在邊緣計算上,由於其低功耗特性強力支援複雜的訊號處理和AI的"訓練-推理一體化"在智慧型手機、物聯網裝置等終端上直接運行,降低對雲端的依賴,推動邊緣計算發展。
因此,一旦北大研發的新型晶片產業化,對於全球通訊以及人工智慧產業的等高算力行業將是顛覆性的。當然,當前此項成果還沒有真正走向市場,量產還需要跨越幾個關鍵步驟。
其一,目前實驗成功實現了16×16矩陣方程的求解。要應對更複雜的實際應用,需要將晶片的計算規模進一步擴大。這涉及到製造工藝的升級和多晶片協同計算技術的完善。
其二,模擬計算晶片需要與特定的演算法和軟體緊密適配。未來需要開發專用的程式設計模型、編譯器以及軟體工具鏈,建構起圍繞新晶片的生態系統。
最後,晶片量產需要與現有的半導體產線(如28/22nm甚至更先進製程)進行適配和最佳化。同時,必須將製造成本控制在市場可接受的範圍內,這本身是一個巨大的挑戰。
這意味著,雖然研究團隊已正積極推進該技術的產業化處理程序,但具體量產時間或許沒那麼快,根據北大團隊成員的預計:如進展順利,在未來3-5年將可以看到基於該技術的早期應用晶片或專用計算系統。
因此,從技術角度而言,北大團隊的成果不僅解決了一個世紀難題;同時為國產算力產業,甚至是全球算力產業開創了一條全新的路徑,有望打破美國在數字計算領域的長期壟斷。但真正實現產業化,還需要更多的攻關以及時間和耐心! (飆叔科技洞察)