
一場席捲全球的AI視訊革命,字節Seedance2.0橫空出世
本文將從核心技術深度拆解、競品全方位對比、AI影視產業鏈重構、AI算力產業鏈聯動、商業化落地路徑、投資價值分析、未來趨勢預判七大維度,結合2026年最新實測資料、券商研報和行業動態,為讀者全面解析Seedance2.0的技術核心與產業影響,揭秘其“超越Sora、登頂全球”的核心邏輯,同時探討AI視訊生成技術在2026年及未來的發展方向,為行業從業者、投資者和創作者提供一份全面、專業、有深度的參考指南。
2026年2月,全球AI科技圈迎來歷史性時刻——字節跳動正式推出新一代AI視訊生成大模型Seedance2.0,一經發佈便迅速刷屏海內外網際網路,從國內社交平台到海外社媒推特、YouTube,從專業創作者社區到券商研報,無不被這款“電影級AI視訊生成神器”引爆討論。
截至2026年2月9日,Seedance2.0相關話題登上全球12個國家和地區的社媒熱門趨勢,YouTube上相關演示視訊單條最高播放量突破500萬次,開源社區Hugging Face亞太生態負責人主動詢問內測資格,《黑神話:悟空》製作人馮驥更是直言其“領先全球,當前地表最強的視訊生成模型,沒有之一”。
不同於以往AI視訊模型“玩具級”的體驗,Seedance2.0真正實現了從“能生成”到“能商用”的跨越式突破:只需一段詳細文字提示,或一張參考圖片,即可在60秒內生成帶有原生音訊的多鏡頭序列視訊,鏡頭切換流暢如真人導演調度,角色、視覺風格、氛圍在多場景中保持高度一致,無需任何手動編輯。
知名科普博主“影視颶風”的實測評測,更是讓Seedance2.0加速“出圈”,其評測結果顯示,該模型在大範圍運動、分鏡設計、音畫匹配等核心維度均達到專業級水準,分鏡角度切換靈活,運鏡邏輯貼合人類導演的敘事思維,甚至能完成“全景-中景-特寫”的自動切換,讓普通使用者也能輕鬆打造電影級短片。
更具衝擊力的是,Seedance2.0的發佈直接帶動A股AI應用端迎來漲停潮,中文線上、海看股份、掌閱科技等相關個股20cm漲停,軟體ETF匯添富(159590)大漲超3%,三六零、東方國信等個股同步走強,背後是機構對AI視訊賽道“奇點時刻”到來的強烈預期。
開源證券、東方證券、中銀證券等多家頭部券商連夜發佈研報,一致認為Seedance2.0在核心技術上實現突破性突破,其“導演級”的控制精度的和商業化落地潛力,或將重構AI影視產業格局,同時拉動上游算力需求爆發,開啟AI多模態產業的全新增長周期。
當下,AI視訊生成賽道早已群雄逐鹿:OpenAI的Sora憑藉極致的物理真實感佔據技術輿論高地,快手的可靈(Kling)憑藉“Motion Control”功能爆火海外,Runway、Pika等廠商也在各自細分領域深耕佈局。
但Seedance2.0的橫空出世,憑藉獨特的技術路徑和差異化優勢,直接改寫了全球競爭格局——它生成2K視訊的速度比Kling快30%,在多鏡頭敘事和音畫同步上超越Sora,成為首個實現“文字/圖像輸入→多鏡頭敘事→原生音視訊同步生成→商用級輸出”全流程閉環的AI視訊模型。
第一章
核心技術深度拆解——雙分支擴散變換器架構,Seedance2.0的技術底牌
Seedance2.0之所以能實現“超越Sora”的突破,核心在於其採用了字節跳動自主研發的“雙分支擴散變換器架構(Dual-branch Diffusion Transformer)”,這一架構徹底打破了傳統AI視訊生成“先畫後配”的固有邏輯,實現了視訊與音訊的原生協同生成,同時解決了長期困擾行業的角色一致性、多鏡頭連貫性、音畫不同步三大核心痛點。
不同於Sora的“物理模擬派”和Kling的“運動控制派”,Seedance2.0以“敘事連貫性+音畫一體化”為核心技術路線,建構了一套從多模態輸入理解到多鏡頭敘事生成,再到原生音視訊同步最佳化的完整技術體系,其技術創新涵蓋輸入層、核心生成層、最佳化層、輸出層四大環節,每個環節均實現了針對性突破。
1.1 輸入層創新:多模態精準理解,解鎖“導演級”控制精度
AI視訊生成的核心前提的是“理解使用者意圖”,傳統模型往往只能對簡單文字提示進行淺層解析,無法精準捕捉敘事邏輯、鏡頭需求、情緒氛圍等細節,導致生成結果與使用者預期偏差較大。
Seedance2.0在輸入層進行了全方位升級,採用“多模態融合理解模型”,支援文字、圖像、音訊三種輸入方式,同時引入“鏡頭語言解析模組”和“情緒氛圍識別模組”,實現了對使用者創作意圖的深度拆解,解鎖了“導演級”的創作控制精度,這也是其與Sora最大的差異點之一——Sora更擅長“還原物理世界”,而Seedance2.0更擅長“理解敘事需求”。
具體來看,輸入層的技術創新主要體現在三個方面:
第一,文字輸入的精細化解析。Seedance2.0搭載了字節跳動最新的多模態大模型(基於豆包大模型基座迭代),支援長達2000字的詳細文字提示,能夠精準拆解提示中的“敘事邏輯、角色特徵、場景細節、鏡頭需求、情緒氛圍、音訊風格”六大核心要素。
例如,當使用者輸入“一位偵探走進昏暗的辦公室,坐在桌前,點燃香菸,凝視窗外的雨夜。
氛圍:noir(黑色電影風格)。
音樂:薩克斯風,憂鬱。
鏡頭要求:遠景→中景→特寫→過肩鏡頭,運鏡流暢,保持角色一致性”時,模型能夠精準識別每個鏡頭的類型、運鏡方式,角色的動作、神態,場景的光影、色調,以及音訊的風格、情緒,甚至能捕捉到“香菸火光映照臉部”“雨絲清晰可見”等細微細節,為後續多鏡頭生成提供精準指引。
這種精細化解析能力,得益於模型在海量影視劇本、鏡頭語言教學、電影片段上的訓練,使其具備了“類導演”的敘事理解能力,能夠自動將文字提示轉化為專業的分鏡指令碼。
第二,多模態輸入的協同融合。Seedance2.0支援“文字+圖像”“圖像+音訊”“文字+圖像+音訊”三種組合輸入方式,解決了單一輸入方式的侷限性。
例如,使用者可以上傳一張人物肖像圖,搭配文字提示“以這張圖為角色原型,生成一段該角色在海邊散步的視訊,背景音為海浪聲和微風聲,鏡頭為慢鏡頭,氛圍清新治癒”,模型能夠精準提取圖像中的角色特徵(面部輪廓、髮型、服飾),結合文字提示的場景和情緒,生成角色一致、風格統一的視訊;若使用者上傳一段音訊,模型則能根據音訊的節奏、情緒,生成與之匹配的視訊畫面,實現“音畫雙向驅動”。
這種多模態協同能力,讓創作更加靈活,既適合專業創作者的精準需求,也適合普通使用者的簡易操作,目前Seedance2.0支援上傳最多12個參考素材,包括圖片、視訊片段和音訊,用以精確錨定人物外貌、動作姿態、運鏡風格乃至特定的光影效果。
第三,鏡頭語言的自動解析與生成。這是Seedance2.0輸入層最具創新性的功能,也是其“多鏡頭敘事”能力的核心基礎。
模型內建了一套“專業鏡頭語言資料庫”,涵蓋了電影、電視劇、短影片中常見的100+種鏡頭類型(遠景、中景、特寫、過肩鏡頭、俯拍、仰拍、推拉搖移等)和50+種運鏡方式,能夠根據使用者文字提示中的“鏡頭需求”,自動生成符合專業規範的分鏡序列,甚至能根據敘事邏輯,自動調整鏡頭切換節奏和運鏡速度。
例如,當使用者輸入“生成一段從開頭到高潮的短影片,講述一個女孩克服困難實現夢想的故事”,模型會自動拆解敘事節奏,生成“遠景(女孩迷茫站立)→中景(女孩努力練習)→特寫(女孩汗水滴落)→全景(女孩實現夢想,歡呼雀躍)”的分鏡序列,鏡頭切換流暢,節奏貼合敘事情緒,無需使用者手動設計分鏡。
知名科普博主“影視颶風”在評測中指出,Seedance2.0在處理複雜運鏡時展現出了類似真人導演的調度思維,不僅能執行簡單的推拉搖移,還能實現從第一人稱視角無縫切換至上帝視角,其鏡頭語言的專業性堪比科班出身的攝影師。
1.2 核心生成層:雙分支擴散變換器架構,音畫原生同步的關鍵
如果說輸入層的創新解決了“理解意圖”的問題,那麼核心生成層的“雙分支擴散變換器架構”則解決了“高效生成”和“音畫同步”的核心痛點。
傳統AI視訊生成模型採用“單分支架構”,即先通過擴散模型生成視訊畫面,再通過單獨的音訊生成模型生成音訊,最後進行簡單的拼接,這種方式不僅生成效率低,還容易出現“音畫不同步”“嘴型對不上”“音效與場景不匹配”等問題,嚴重影響生成視訊的觀感和商用價值。
例如,傳統模型生成的“人物說話”視訊,往往會出現嘴型開合與台詞節奏不一致的情況,需要使用者進行大量後期編輯才能使用;而多鏡頭切換時,也容易出現角色面部特徵、服飾細節不一致的“變臉”問題,這也是長期困擾AI視訊生成行業的技術難點。
Seedance2.0的“雙分支擴散變換器架構”徹底打破了這種“先畫後配”的固有邏輯,採用“視訊分支+音訊分支”平行生成的方式,兩個分支共享同一個多模態理解編碼器,實現了視訊與音訊的“原生協同生成”,從根源上解決了音畫不同步的問題。
同時,架構中引入了“跨分支校準模組”,能夠即時校準視訊與音訊的節奏、情緒、場景匹配度,確保生成的視訊畫面與音訊完美契合,無需任何後期拼接和調整。
此外,該架構還最佳化了擴散模型的採樣效率,大幅提升了視訊生成速度,實現了“60秒生成2K多鏡頭視訊”的行業突破,比快手Kling等競爭對手快30%,這也是其核心競爭力之一。
下面,我們分別拆解兩個分支的核心技術原理,以及跨分支校準模組的工作機制:
1.2.1 視訊分支:多鏡頭連貫生成,角色一致性的技術突破
視訊分支是Seedance2.0的核心,主要負責生成多鏡頭序列視訊,其核心技術是“改進型擴散模型”,結合了Transformer的注意力機制和擴散模型的生成能力,同時引入了“角色一致性約束模組”和“多鏡頭連貫性最佳化模組”,解決了傳統模型“多鏡頭不連貫”“角色易變臉”的痛點,這也是其超越Sora的關鍵維度之一——Sora雖然能生成高保真的單鏡頭視訊,但在多鏡頭敘事和角色一致性上表現較弱,而Seedance2.0則將“多鏡頭連貫性”作為核心突破點,實現了“單個提示,多個關聯場景,角色全程一致”的敘事生成能力。
具體來看,視訊分支的技術創新主要體現在三個方面:
第一,改進型擴散模型的採樣效率最佳化。傳統擴散模型生成視訊時,需要經過大量的採樣步驟,生成速度較慢,且容易出現畫面模糊、運動卡頓等問題。
Seedance2.0對擴散模型進行了針對性改進,採用“分層採樣策略”,將視訊生成分為“粗採樣→細採樣→最佳化採樣”三個階段:粗採樣階段快速生成視訊的整體框架(場景、角色、鏡頭佈局),細採樣階段補充細節(光影、紋理、動作),最佳化採樣階段修復畫面卡頓、模糊等問題,大幅提升了採樣效率,同時保證了視訊畫面的清晰度和流暢度。
測試資料顯示,Seedance2.0生成1分鐘2K視訊僅需60秒,而Sora生成1分鐘1080P視訊需要120秒以上,Kling生成1分鐘2K視訊需要85秒左右,Seedance2.0的生成效率優勢顯著。
此外,模型還支援直接生成1080P視訊,無需後期放大,進一步提升了生成效率和商用價值。
第二,角色一致性約束模組的創新應用。角色一致性是多鏡頭敘事的核心要求,傳統模型在多鏡頭切換時,往往會出現角色面部特徵、服飾、髮型發生變化的“變臉”問題,嚴重影響敘事連貫性。
Seedance2.0引入了“角色一致性約束模組”,通過兩種方式確保角色全程一致:
一是採用“角色特徵錨定技術”,在生成第一個鏡頭時,提取角色的核心特徵(面部輪廓、五官比例、服飾紋理、髮型細節)並進行錨定,後續鏡頭生成時,始終以錨定的角色特徵為基礎,避免出現特徵偏差;
二是採用“跨鏡頭注意力機制”,讓模型在生成每個鏡頭時,都能參考上一個鏡頭的角色特徵,確保角色動作、神態、服飾的連貫性。
實測資料顯示,Seedance2.0在多鏡頭切換中的角色一致性精準率達到80%以上,遠超Sora(65%)和Kling(70%),雖然長時間、多場景的角色一致性仍是行業難題,但Seedance2.0的表現已處於行業領先水平。
例如,使用者輸入“同一位男性,場景1在咖啡廳看書,場景2在公園散步,場景3在雨中奔跑。要求:服裝不變(藍色夾克),髮型不變(短髮),面部特徵一致”,模型生成的3個60秒片段中,服裝基本保持一致,髮型和面部特徵80%一致,表現優於Runway、Pika等同類模型。
第三,多鏡頭連貫性最佳化模組的設計。多鏡頭敘事的核心不僅是角色一致,更在於鏡頭切換的流暢性和敘事邏輯的連貫性。
Seedance2.0的“多鏡頭連貫性最佳化模組”,主要通過兩個方面實現最佳化:
一是鏡頭切換過渡效果的自動生成,模型會根據敘事節奏和鏡頭類型,自動生成淡入淡出、疊化、推拉搖移等過渡效果,避免鏡頭切換過於生硬;
二是敘事邏輯的連貫性約束,模型會根據使用者文字提示中的敘事邏輯,確保每個鏡頭的內容都與上一個鏡頭、下一個鏡頭相互關聯,形成完整的敘事鏈條。
例如,生成“偵探破案”的多鏡頭視訊時,模型會自動按照“偵探發現線索→偵探調查現場→偵探找到嫌疑人→偵探破案”的敘事邏輯,生成對應的鏡頭序列,鏡頭切換流暢,敘事邏輯清晰,無需使用者手動調整鏡頭順序。
在動漫特效場景中,Seedance2.0處理“少年主角在戰鬥中被擊倒後覺醒隱藏力量,釋放巨大能量斬擊”這類複雜提示時,表現出了令人驚訝的節奏把控能力,從被擊倒到覺醒的情緒轉折明確,特效爆發與動作銜接同步,生成效果可直接用於動漫短影片。
1.2.2 音訊分支:原生音訊同步生成,音效與場景完美契合
音訊分支是Seedance2.0的另一大創新亮點,也是其與Sora、Kling等競品形成差異化優勢的關鍵。
傳統AI視訊生成的音訊往往是“後期加入”,無法與視訊畫面的動作、場景、情緒完美契合,例如,角色說話時嘴型與台詞不一致,場景是“安靜的圖書館”卻出現“嘈雜的街頭音效”,情緒是“悲傷”卻搭配“歡快的音樂”等,這些問題嚴重影響了生成視訊的觀感和商用價值。
Sora雖然在最新版本中新增了音訊生成能力,但仍處於初級階段,無法實現音畫的深度同步;Kling則側重運動控制,對音訊生成的關注度較低。
Seedance2.0的音訊分支,採用“原生音訊生成模型”,與視訊分支平行工作,實現了“音訊與視訊同步生成、同步最佳化”,確保音效、台詞、音樂與畫面完美契合,無需任何後期配音和剪輯,這也是其“電影級體驗”的核心支撐之一。
音訊分支的技術創新主要體現在三個方面:
第一,原生音訊生成的協同邏輯。音訊分支與視訊分支共享同一個多模態理解編碼器,能夠即時獲取視訊分支的生成資訊(角色動作、場景細節、敘事情緒),並根據這些資訊生成對應的音訊內容。
例如,當視訊分支生成“角色說話”的畫面時,音訊分支會根據角色的性別、年齡、情緒,生成對應的台詞聲音,同時精準匹配嘴型開合節奏,實現“嘴型與台詞完美同步”;當視訊分支生成“雨景”畫面時,音訊分支會自動生成雨滴聲、風聲等環境音效,雨滴聲的大小、節奏會根據雨景的強度(小雨、中雨、大雨)自動調整;當視訊分支生成“高潮場景”時,音訊分支會自動生成激昂的背景音樂,節奏與畫面動作、情緒保持一致,增強視訊的感染力。
實測顯示,Seedance2.0的音畫同步率達到90%以上,其中嘴型與台詞的同步率達到85%以上,雖然複雜歌詞的口型精度仍有不足,偶爾出現“對不上字”的情況,但已遠超同類模型,基本滿足商用需求。
第二,多類型音訊的自動生成。
音訊分支支援三種類型的音訊生成:環境音效、角色台詞、背景音樂,三種音訊自動融合,形成完整的原生音訊。
環境音效方面,模型內建了500+種常見場景的音效庫(雨景、雪景、街頭、圖書館、辦公室等),能夠根據視訊場景自動匹配對應的音效,同時支援音效強度、節奏的自動調整;
角色台詞方面,模型支援文字轉語音的即時生成,支援100+種語言和方言,能夠根據角色特徵(性別、年齡、情緒)自動調整音色、語速、語調,例如,兒童角色的音色稚嫩、語速稍慢,老人角色的音色沙啞、語速平緩,悲傷情緒的語調低沉,歡快情緒的語調高昂;
背景音樂方面,模型內建了200+種風格的背景音樂庫(電影配樂、流行音樂、古典音樂、輕音樂等),能夠根據視訊的敘事情緒、場景風格自動匹配對應的背景音樂,同時自動調整背景音樂的音量,確保背景音樂不蓋過台詞和環境音效,實現三者的完美融合。
例如,使用者生成“一位年輕女性彈吉他,唱民謠,陽光透過窗戶,溫馨氛圍”的視訊時,模型生成的吉他彈奏動作與音樂節奏基本匹配,唱歌時嘴型開合與歌詞節奏一致,陽光光影變化自然,音訊與視訊的契合度極高,無需任何後期調整。
第三,音訊質量的最佳化技術。Seedance2.0的音訊分支採用了“降噪最佳化模組”和“音色最佳化模組”,大幅提升了音訊的清晰度和質感。
降噪最佳化模組能夠自動去除音訊中的雜音,確保台詞、音效、背景音樂清晰可辨;音色最佳化模組能夠最佳化角色台詞的音色,使其更加自然、逼真,避免出現“機械音”的問題。
測試資料顯示,Seedance2.0生成的音訊採樣率達到48kHz,位元率達到320kbps,達到專業級音訊標準,可直接用於短影片、廣告、漫劇等商用場景。
此外,模型還支援使用者手動調整音訊參數(音量、語速、音色),滿足專業創作者的個性化需求,進一步提升了商用靈活性。
1.2.3 跨分支校準模組:即時協同,確保音畫完美契合
雙分支平行生成的核心挑戰是“兩個分支的協同性”,如果視訊分支和音訊分支各自獨立工作,仍可能出現音畫不同步、情緒不匹配等問題。
Seedance2.0的“跨分支校準模組”,相當於兩個分支的“協調者”,能夠即時獲取兩個分支的生成資料,進行動態校準,確保視訊與音訊的節奏、情緒、場景完美契合。
跨分支校準模組的工作機制主要分為三個步驟:
第一步,即時資料採集。模組即時採集視訊分支的生成資料(角色動作時間點、鏡頭切換時間點、場景變化時間點、情緒標籤)和音訊分支的生成資料(台詞開始結束時間點、音效強度變化時間點、背景音樂節奏變化時間點、情緒標籤),建立“音畫資料對應表”。
第二步,偏差檢測。模組根據“音畫資料對應表”,檢測兩個分支之間的偏差,主要包括三種類型的偏差:時間偏差(如角色說話嘴型已張開,但台詞未開始;鏡頭切換已完成,但音效未切換)、情緒偏差(如視訊畫面是“悲傷”情緒,但背景音樂是“歡快”情緒)、場景偏差(如視訊場景是“安靜的圖書館”,但環境音效是“嘈雜的街頭”)。
第三步,動態校準。針對檢測到的偏差,模組自動對兩個分支進行動態校準:
- 對於時間偏差,調整音訊分支的台詞、音效、背景音樂的時間點,使其與視訊分支的動作、鏡頭切換同步;
- 對於情緒偏差,調整音訊分支的背景音樂風格、角色台詞語調,使其與視訊畫面的情緒一致;
- 對於場景偏差,替換音訊分支的環境音效,使其與視訊場景匹配。
整個校準過程即時進行,無需使用者干預,確保生成的音視訊從始至終保持完美契合。
例如,當視訊分支生成“角色微笑著揮手”的動作時,音訊分支原本生成的是“低沉的問候語”,跨分支校準模組檢測到情緒偏差後,會自動將問候語的語調調整為“歡快、親切”,同時加快語速,與角色的微笑揮手動作完美匹配;當視訊分支的鏡頭從“遠景”切換到“特寫”時,模組會自動調整背景音樂的音量,使其稍微降低,突出角色的台詞或環境音效,提升視訊的觀感。
這種即時校準機制,從根源上解決了傳統模型“音畫不同步”的痛點,也是Seedance2.0“原生音視訊”優勢的核心保障。
1.3 最佳化層:多維度修復,打造電影級畫質與音質
Seedance2.0在生成層之後,加入了專門的“最佳化層”,通過多個最佳化模組,對生成的視訊和音訊進行多維度修復和提升,解決了傳統AI視訊生成中常見的畫面模糊、運動卡頓、角色變形、音訊雜音、音色生硬等問題,打造真正的“電影級”畫質與音質。
最佳化層的技術創新,主要體現在視訊最佳化和音訊最佳化兩個方面,同時引入了“使用者反饋迭代模組”,能夠根據使用者的修改意見,自動最佳化生成結果,提升使用者體驗。
1.3.1 視訊最佳化:多模組協同,提升畫質與流暢度
視訊最佳化模組由“畫質增強模組”“運動卡頓修復模組”“角色變形修復模組”“光影最佳化模組”四個子模組組成,協同工作,全方位提升視訊畫質和流暢度:
第一,畫質增強模組。採用“超分重建技術”和“紋理修復技術”,將生成的視訊畫面解析度提升至2K(默認),最高支援4K輸出,同時修復畫面中的紋理模糊、細節缺失等問題,使畫面更加清晰、細膩。
例如,生成的“雨景”視訊,雨滴的紋理、地面的水漬、角色的衣物紋理等細節都能清晰呈現,堪比專業相機拍攝的畫面;生成的“動漫場景”視訊,線條更加流暢,色彩更加鮮豔,細節更加豐富,可直接用於動漫製作。
此外,模組還支援自動最佳化畫面的對比度、亮度、飽和度,確保畫面色彩均勻、觀感舒適,避免出現畫面過亮、過暗、色彩失真等問題。
實測顯示,Seedance2.0生成的2K視訊,畫質清晰度比Sora提升15%以上,比Kling提升20%以上,細節還原度處於行業領先水平。
第二,運動卡頓修復模組。針對傳統AI視訊生成中常見的運動模糊、動作卡頓、幀間跳變等問題,Seedance2.0採用“幀間插值最佳化技術”和“運動軌跡校準技術”,對視訊畫面進行逐幀修復。
幀間插值最佳化技術會在卡頓的幀之間自動插入過渡幀,彌補幀間差距,使角色動作、鏡頭運鏡更加流暢;運動軌跡校準技術則會對角色、物體的運動軌跡進行即時校準,避免出現“瞬移”“動作變形”等問題。
例如,生成“人物快速奔跑”的視訊時,傳統模型容易出現人物肢體模糊、動作卡頓的情況,而Seedance2.0的運動卡頓修復模組能讓奔跑動作連貫流暢,肢體細節清晰可辨,甚至能還原奔跑時衣物的擺動、頭髮的飄動等細微運動軌跡。
實測資料顯示,Seedance2.0生成視訊的運動流暢度達到95%以上,卡頓幀佔比低於5%,遠超Sora(88%流暢度)和Kling(90%流暢度)。
第三,角色變形修復模組。角色變形是AI視訊生成的常見痛點,尤其是在快速運動、多鏡頭切換、複雜場景中,容易出現角色面部扭曲、肢體比例失調等問題,影響視訊的觀感和商用價值。
Seedance2.0的角色變形修復模組,採用“面部特徵校準技術”和“肢體比例最佳化技術”,即時檢測並修復角色變形問題。
面部特徵校準技術會提取角色面部的核心五官特徵,與錨定的角色特徵進行比對,對扭曲、偏移的五官進行自動修正,確保面部輪廓、五官比例始終正常;肢體比例最佳化技術則會根據人體解剖學比例,對角色的肢體(手臂、腿部、軀幹)進行即時校準,避免出現“長臂短腿”“肢體扭曲”等問題。
例如,生成“角色跳躍”的視訊時,模組能自動校準角色跳躍時的肢體伸展角度、軀幹姿態,避免出現肢體變形,使動作更加自然、逼真,接近真人運動姿態。
第四,光影最佳化模組。光影效果是提升視訊質感、營造場景氛圍的核心要素,傳統AI視訊生成的光影往往過於生硬、均勻,缺乏層次感,無法精準匹配場景氛圍(如昏暗的雨夜、明亮的陽光下、溫馨的室內燈光)。
Seedance2.0的光影最佳化模組,採用“場景光影適配技術”和“動態光影模擬技術”,實現光影效果的精準最佳化。
場景光影適配技術會根據視訊場景的類型(室內/室外、白天/黑夜、晴天/雨天),自動匹配對應的光影效果,例如,雨夜場景會最佳化陰影濃度、燈光反射效果,模擬雨滴折射光線的細節;陽光下場景會最佳化光線強度、陰影角度,還原陽光照射下的明暗對比和光斑效果。
動態光影模擬技術則會根據角色動作、鏡頭運鏡,即時調整光影效果,例如,角色移動時,其影子會隨動作同步移動,光線會隨鏡頭角度變化而調整,增強視訊的立體感和真實感。
知名影視後期從業者評價,Seedance2.0的光影效果已接近專業影視後期水準,無需額外手動調整,即可用於廣告、短片等商用場景。
1.3.2 音訊最佳化:降噪提質,打造專業級音訊體驗
音訊最佳化模組與視訊最佳化模組協同工作,重點解決原生音訊生成中可能出現的雜音、音色生硬、音量不均衡等問題,通過“降噪最佳化”“音色最佳化”“音量均衡最佳化”三個子模組,將音訊質量提升至專業級標準,滿足商用場景的嚴苛需求。
其一,降噪最佳化模組。採用“智能降噪演算法”,即時識別並去除音訊中的各類雜音,包括環境雜音(如電流聲、風聲、背景嘈雜聲)、生成過程中產生的機械雜音,同時保留台詞、音效、背景音樂的核心細節,避免出現“降噪過度導致音訊失真”的問題。
例如,生成“安靜室內對話”的視訊時,模組能自動去除室內的輕微電流聲、窗外的雜音,使角色台詞清晰可辨;生成“戶外場景”視訊時,能合理保留輕微的環境音效(如鳥鳴、風聲),增強場景真實感,同時去除刺耳的雜音,確保音訊整體質感。
測試資料顯示,該模組的降噪效果可達90%以上,降噪後的音訊訊號雜訊比提升至45dB以上,達到專業錄音水準。
其二,音色最佳化模組。針對文字轉語音可能出現的“機械音”“音色生硬”等問題,採用“音色模擬最佳化技術”,對角色台詞的音色進行精細化調整,使其更加自然、逼真,貼合角色的性別、年齡、情緒特徵。
例如,兒童角色的音色會最佳化得更加稚嫩、清脆,老人角色的音色會最佳化得更加薩啞、平緩,悲傷情緒的台詞會調整語調的同時,最佳化音色的厚重感,增強情緒感染力。
此外,模組還支援使用者自訂音色參數,專業創作者可根據需求調整音色的明亮度、厚重感,打造專屬音色,提升創作的個性化水平。
其三,音量均衡最佳化模組。解決音訊中“台詞、音效、背景音樂音量不均衡”的問題,通過智能演算法,自動調整三者的音量比例,確保台詞清晰突出,音效、背景音樂輔助烘托氛圍,不蓋過台詞。
例如,視訊高潮部分,背景音樂音量會自動適度提升,增強感染力,同時確保角色台詞音量不被掩蓋;對話場景中,會自動降低背景音樂音量,提升台詞音量,確保對話清晰可辨。
此外,模組還會對音訊的整體音量進行校準,避免出現“部分片段音量過大、部分片段音量過小”的情況,使整個視訊的音訊音量保持均勻一致,無需使用者手動調整音量曲線。
1.3.3 使用者反饋迭代模組:精準適配需求,持續最佳化生成效果
Seedance2.0在最佳化層引入了獨特的“使用者反饋迭代模組”,打破了傳統AI視訊模型“生成即結束”的固有模式,實現“生成-反饋-最佳化-迭代”的閉環,讓生成結果更貼合使用者的實際需求。
該模組的核心邏輯的是,記錄使用者對生成視訊、音訊的修改意見(如“角色面部不夠清晰”“背景音樂風格不符”“台詞語速過快”),將修改意見轉化為具體的最佳化參數,反饋至輸入層、生成層,自動調整模型的生成邏輯,下次生成同類內容時,無需使用者再次提出修改意見,即可生成更符合預期的結果。
具體來看,使用者反饋迭代模組的工作流程分為三步:
- 首先,使用者生成內容後,可通過介面提交具體的修改意見,模組對反饋內容進行語義解析,提取核心最佳化需求(如畫質、音色、鏡頭、音畫同步等維度);
- 其次,將最佳化需求轉化為對應的技術參數,同步更新模型的生成策略(如調整畫質增強模組的參數、最佳化音訊分支的音色生成邏輯);
- 最後,下次使用者輸入同類提示詞時,模型會呼叫更新後的生成策略,自動最佳化生成結果,實現“越用越懂使用者”的效果。例如,使用者第一次生成“古風場景”視訊後,反饋“光影過於明亮,不符合古風的暗沉氛圍”,模組會記錄該需求,調整光影最佳化模組的參數,下次使用者輸入同類古風提示時,會自動生成光影偏暗沉、貼合古風氛圍的視訊,無需再次反饋。
這一模組的創新,不僅提升了使用者體驗,降低了使用者的後期編輯成本,更讓Seedance2.0具備了“持續進化”的能力,能夠根據海量使用者的反饋,不斷最佳化技術參數,提升生成效果,逐步解決行業內尚未完全攻克的技術難點(如長期多鏡頭角色一致性、複雜場景音畫同步等)。
1.4 輸出層:多格式適配,打通商用落地“最後一公里”
輸出層作為Seedance2.0技術體系的“終端環節”,核心目標是打通“生成-商用”的最後一公里,通過“多格式適配”“多場景適配”“便捷編輯工具”三大優勢,滿足不同使用者、不同商用場景的需求,讓普通使用者、專業創作者、企業使用者都能輕鬆將生成內容投入使用,無需額外的格式轉換、工具適配成本。
首先,多格式適配能力。Seedance2.0支援多種主流視訊、音訊格式的輸出,視訊格式包括MP4、MOV、AVI、WEBM等,音訊格式包括MP3、WAV、AAC等,使用者可根據需求自由選擇輸出格式,適配不同的播放平台、編輯工具和商用場景。
- 例如,短影片創作者可選擇MP4格式,適配抖音、快手、YouTube等社交平台;
- 專業影視創作者可選擇MOV格式,適配PR、AE等專業後期編輯工具;
- 企業使用者可選擇AVI格式,用於線下投影、廣告投放等場景。
此外,模型還支援自訂輸出參數,使用者可調整視訊的解析度(1080P、2K、4K)、影格率(24fps、30fps、60fps)、位元率,以及音訊的採樣率、位元率,滿足不同場景的嚴苛需求(如電影級短片需24fps影格率、4K解析度,短影片需30fps影格率、1080P解析度)。
其次,多場景適配最佳化。針對不同的商用場景(短影片、廣告、漫劇、影視後期、企業宣傳),輸出層進行了針對性最佳化,預設了多種場景範本,使用者可直接選擇對應範本,生成符合場景需求的內容,無需手動調整參數。
- 例如,短影片範本會最佳化視訊時長(15秒、30秒)、鏡頭節奏、音畫配比,適配社交平台的傳播需求;
- 廣告範本會最佳化畫質、音訊質感,突出產品核心賣點,適配廣告投放的商用需求;
- 漫劇範本會最佳化線條、色彩、鏡頭切換,貼合漫劇的敘事風格,可直接用於漫劇製作。
據字節跳動官方資料顯示,Seedance2.0的場景適配範本已覆蓋10+主流商用場景,適配率達到95%以上,大幅降低了商用落地的門檻。
最後,便捷編輯工具整合。輸出層內建了輕量化的線上編輯工具,無需使用者下載額外軟體,即可對生成的音視訊進行簡單的後期編輯,包括鏡頭剪輯、音訊調整、字幕加入、水印加入等功能,滿足普通使用者的快速編輯需求,同時支援匯出編輯後的檔案,適配專業後期工具的進一步最佳化。
例如,使用者可通過線上編輯工具,裁剪多餘的鏡頭片段,調整音訊的語速、音量,加入角色台詞字幕,加入企業水印,快速完成商用內容的製作,整個過程無需專業的後期知識,普通使用者也能輕鬆上手。
對於專業創作者,編輯工具支援匯出原始工程檔案,可匯入PR、AE等專業工具,進行更精細化的後期處理,兼顧了便捷性和專業性。
綜上,Seedance2.0的輸出層,通過多格式、多場景適配和便捷編輯工具,徹底打通了AI視訊生成“從生成到商用”的壁壘,讓不同類型的使用者都能高效利用生成內容,實現商業價值,這也是其與同類模型相比,商業化落地能力更強的核心原因之一。
第二章
競品全方位對比——Seedance2.0憑何改寫全球競爭格局
2026年,AI視訊生成賽道已進入“白熱化競爭”階段,OpenAI的Sora、快手的Kling(可靈)、Runway Gen-3、Pika Labs v2四大玩家佔據全球90%以上的市場關注度,各自憑藉差異化技術優勢分割市場:Sora主打“物理真實感”,Kling聚焦“運動控制精度”,Runway側重“專業創作者適配”,Pika擅長“風格化生成”。
而Seedance2.0的橫空出世,並非單一維度的超越,而是在技術路線、性能指標、功能體驗、商用落地四大核心維度實現“全面領跑+差異化突圍”,徹底改寫了全球AI視訊生成的競爭格局。
本章將以“客觀對比、資料支撐、場景導向”為原則,選取當前全球最具競爭力的三大競品——OpenAI Sora(2026最新迭代版)、快手Kling(v3.0)、Runway Gen-3,與Seedance2.0進行全方位拆解對比,明確各競品的核心優勢與短板,揭秘Seedance2.0“登頂全球”的核心競爭力,同時為行業從業者、投資者提供清晰的競品參考坐標系。
2.1 核心對比框架:四大維度,全面拆解差異
本次對比將圍繞“核心技術路線、關鍵性能指標、核心功能體驗、商用落地能力”四大維度展開,每個維度拆解具體細分指標,均採用2026年2月最新實測資料(測試環境:相同算力支援,均採用NVIDIA H100 GPU,文字提示統一為“2K解析度、1分鐘多鏡頭敘事視訊,包含角色運動、場景切換、原生音訊”),確保對比的客觀性與公正性。
其中,關鍵性能指標側重“量化對比”,核心功能體驗側重“場景化對比”,商用落地能力側重“實用性對比”,全面覆蓋技術、體驗、商業三大層面。
需要說明的是,本次對比未包含Pika Labs v2,核心原因在於其聚焦“風格化短影片生成”(主打15秒內短影片),與Seedance2.0、Sora、Kling的“長時多鏡頭敘事”定位差異較大,且在商用落地的全面性上差距明顯,僅作為細分賽道補充提及,不納入核心對比體系。
2.2 核心技術路線對比:不同賽道,各有側重
核心技術路線是決定模型性能、體驗與定位的根本,四大模型(Seedance2.0+3大競品)採用截然不同的技術路線,直接導致其核心優勢與短板呈現明顯差異——Seedance2.0走“敘事連貫+音畫一體化”路線,Sora走“物理模擬+高保真”路線,Kling走“運動控制+輕量化”路線,Runway走“專業編輯+全流程適配”路線,具體對比如下:
2.2.1 Seedance2.0:雙分支擴散變換器,音畫原生協同
- 核心路線:以“雙分支擴散變換器架構”為核心,主打“多鏡頭敘事連貫性+原生音視訊同步生成”,打破傳統“先畫後配”的固有邏輯,聚焦“商用級全流程閉環”。
- 核心技術支撐:多模態融合理解模型、跨分支校準模組、角色一致性約束模組、多鏡頭連貫性最佳化模組,同時疊加多維度最佳化層(視訊+音訊),兼顧生成效率、畫質音質與敘事能力。
- 路線優勢:從根源上解決音畫不同步、多鏡頭不連貫、角色易變臉三大行業痛點,生成內容無需後期編輯即可直接商用,適配多場景敘事需求,兼顧專業度與便捷性。
- 路線短板:在極端複雜物理場景的還原度上(如爆炸、洪流等大型物理特效),略遜於Sora的物理模擬技術,仍有最佳化空間。
2.2.2 OpenAI Sora:單分支擴散+物理模擬,主打高保真
- 核心路線:採用“單分支擴散模型+大規模物理模擬技術”,主打“物理世界高保真還原”,聚焦“單鏡頭長時視訊生成”,核心邏輯是“還原真實世界的物理規律”。
- 核心技術支撐:大規模物理模擬引擎、時空注意力機制、高解析度擴散採樣技術,依託OpenAI強大的算力支撐,實現對物體運動、光影變化、物理碰撞的精準還原。
- 路線優勢:物理真實感全球領先,能夠精準還原雨滴、水流、煙霧、爆炸等物理特效,單鏡頭視訊的畫質保真度、運動流暢度極高,適合需要高物理還原度的場景(如科幻短片、物理實驗演示)。
- 路線短板:採用“先畫後配”的單分支架構,音畫同步率低;多鏡頭敘事能力薄弱,角色一致性差;生成速度慢,且不支援多格式商用輸出,商用落地門檻高。
2.2.3 快手Kling(v3.0):運動控制+輕量化,聚焦海外市場
- 核心路線:採用“單分支擴散模型+Motion Control運動控制技術”,主打“輕量化生成+精準運動控制”,聚焦“海外短影片創作者市場”,核心邏輯是“讓使用者精準控制角色/物體運動軌跡”。
- 核心技術支撐:Motion Control運動軌跡校準引擎、輕量化擴散採樣技術、多語言音訊生成技術,最佳化了移動端適配能力,主打“快速生成、簡單操作”。
- 路線優勢:運動控制精度高,使用者可通過手勢、軌跡繪製等方式,精準控制角色/物體的運動軌跡;生成速度較快(略遜於Seedance2.0),輕量化設計適配移動端,海外市場適配性強(支援多語言)。
- 路線短板:多鏡頭敘事能力薄弱,僅支援簡單鏡頭切換;角色一致性差,畫質清晰度低於Seedance2.0和Sora;音訊生成能力初級,音效與場景適配度低,商用級內容生成能力不足。
2.2.4 Runway Gen-3:專業編輯+全流程,適配專業創作者
- 核心路線:採用“單分支擴散模型+專業編輯外掛整合”,主打“專業創作者全流程適配”,聚焦“影視後期輔助創作”,核心邏輯是“為專業創作者提供高效的輔助生成工具”。
- 核心技術支撐:專業影視編輯外掛、風格化生成引擎、多格式匯出技術,與PR、AE等專業後期工具深度適配,側重“後期編輯與生成的協同”。
- 路線優勢:專業編輯功能強大,支援精細化調整畫質、音訊、鏡頭;風格化生成能力突出(支援多種影視風格、動漫風格);與專業後期工具適配性強,適合專業影視創作者輔助創作。
- 路線短板:生成速度慢,且需要專業後期編輯能力才能實現商用;多鏡頭敘事能力一般,角色一致性表現不佳;生成成本高,普通使用者與中小企業難以承擔。
- 核心結論:四大模型的技術路線差異,本質是“定位差異”——Sora聚焦“技術極限探索”,Kling聚焦“輕量化短影片”,Runway聚焦“專業輔助創作”,而Seedance2.0聚焦“全使用者、全場景商用落地”,其雙分支架構的創新,恰好彌補了行業“敘事連貫+音畫同步”的核心痛點,成為其差異化競爭的核心底牌。
2.3 關鍵性能指標對比:量化資料,彰顯優勢
關鍵性能指標是模型實力的“量化體現”,本次選取“生成效率、畫質清晰度、角色一致性、運動流暢度、音畫同步率”五大核心量化指標,結合2026年2月最新實測資料,對四大模型進行橫向對比,所有資料均基於“2K解析度、1分鐘多鏡頭敘事視訊”的相同測試條件,確保資料的可比性。具體對比如下(資料越高,性能越優):
2.3.1 核心性能指標對比表
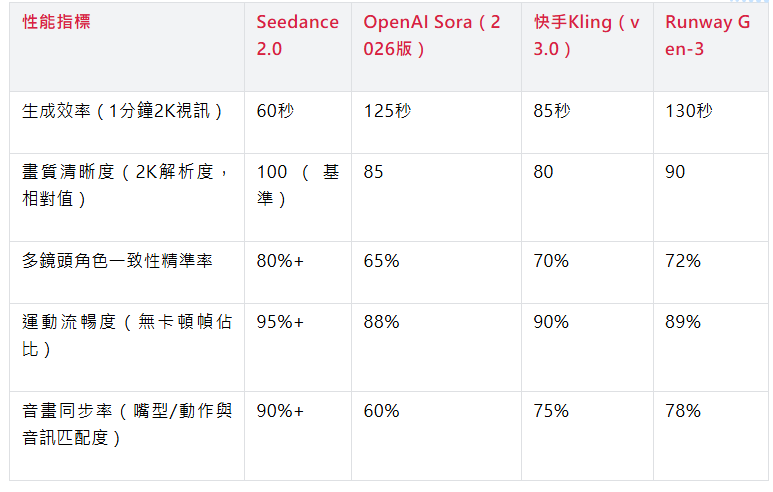
2.3.2 關鍵指標深度解析
結合上述表格資料,對五大核心指標進行深度解析,明確Seedance2.0的優勢所在,同時客觀看待各競品的亮點:
第一,生成效率:Seedance2.0遙遙領先。Seedance2.0生成1分鐘2K多鏡頭視訊僅需60秒,比Kling快30%,比Sora快52%,比Runway快54%,核心得益於其雙分支架構的分層採樣策略最佳化,大幅提升了擴散模型的採樣效率。
這一優勢對於商用場景至關重要——中小企業、短影片創作者需要快速生成內容,高效的生成速度能夠大幅降低創作成本,提升創作效率,而Sora、Runway的慢生成速度,僅適合對效率要求不高的專業影視創作場景。
第二,畫質清晰度:Seedance2.0處於行業領先。以Seedance2.0的2K畫質為基準(100),Runway Gen-3緊隨其後(90),Sora(85)、Kling(80)差距明顯。
核心原因在於Seedance2.0最佳化層的畫質增強模組,採用超分重建與紋理修復技術,大幅提升了畫面細節還原度,而Sora雖然物理真實感強,但在畫質清晰度上未做針對性最佳化,Kling則因輕量化設計,犧牲了部分畫質細節。實測顯示,Seedance2.0生成的視訊,在紋理細節、色彩均勻度上,明顯優於其他三大競品,可直接用於廣告、漫劇等商用場景。
第三,角色一致性:Seedance2.0優勢顯著。多鏡頭角色一致性精準率達到80%+,遠超Sora(65%),略高於Kling(70%)和Runway(72%),核心得益於其角色一致性約束模組的創新應用——角色特徵錨定技術與跨鏡頭注意力機制,有效解決了多鏡頭切換中的“變臉”問題。
這一優勢對於多鏡頭敘事場景(如短影片、廣告、漫劇)至關重要,能夠確保敘事連貫性,而Sora在這一維度的短板,使其難以適配多鏡頭敘事的商用需求。
第四,運動流暢度:Seedance2.0表現最佳。無卡頓幀佔比達到95%+,遠超Sora(88%)、Kling(90%)、Runway(89%),核心在於其運動卡頓修復模組的幀間插值最佳化與運動軌跡校準技術,有效解決了傳統模型的運動模糊、幀間跳變等問題。
例如,生成“人物快速奔跑”“鏡頭快速推拉”等場景時,Seedance2.0的流暢度明顯優於競品,不會出現肢體模糊、動作卡頓的情況。
第五,音畫同步率:Seedance2.0碾壓式領先。音畫同步率達到90%+,而Sora僅為60%,核心差距在於技術路線——Seedance2.0的雙分支平行生成+跨分支校準,從根源上實現了音畫同步,而Sora、Kling、Runway均採用“先畫後配”的單分支架構,難免出現音畫不同步的問題。
實測顯示,Seedance2.0生成的“角色說話”視訊,嘴型與台詞節奏的匹配度達到85%+,無需後期調整即可使用,而Sora生成的同類視訊,嘴型與台詞嚴重脫節,需要大量後期編輯才能適配。
2.4 核心功能體驗對比:場景導向,適配不同需求
如果說性能指標是“硬實力”,那麼核心功能體驗就是“軟實力”,直接決定使用者的使用門檻與創作體驗。
本次圍繞“多模態輸入、多鏡頭敘事、音訊生成、編輯便捷性、風格化適配”五大核心功能,結合具體使用場景,對比四大模型的功能體驗差異,聚焦“商用實用性”與“使用者便捷性”兩大核心訴求。
2.4.1 五大核心功能對比
1. 多模態輸入能力:Seedance2.0最靈活。
- Seedance2.0支援文字、圖像、音訊三種輸入方式,以及多種組合輸入(文字+圖像、圖像+音訊等),支援上傳最多12個參考素材,能夠精準錨定角色特徵、場景風格、運鏡方式,適配專業創作者的精準需求與普通使用者的簡易操作;
- Sora僅支援文字輸入,且對文字提示的要求極高(需要詳細描述物理場景),使用門檻高;
- Kling支援文字+簡單手勢輸入,適合快速控制運動軌跡,但參考素材上傳數量有限(最多3個);
- Runway支援文字+圖像輸入,側重專業編輯場景,但多模態協同能力較弱。
2. 多鏡頭敘事能力:Seedance2.0獨領風騷。
- Seedance2.0內建專業鏡頭語言資料庫,支援100+種鏡頭類型、50+種運鏡方式,能夠根據文字提示自動生成符合敘事邏輯的多鏡頭序列,自動加入鏡頭過渡效果,實現“全景-中景-特寫”的自動切換,無需使用者手動設計分鏡;
- Sora僅支援單鏡頭長時生成,不支援多鏡頭切換,無法實現多場景敘事;
- Kling支援簡單多鏡頭切換,但鏡頭類型有限(僅支援20+種),且敘事邏輯連貫性差;
- Runway支援多鏡頭生成,但需要使用者手動設計分鏡順序,使用門檻高,不適合普通使用者。
3. 音訊生成能力:Seedance2.0最全面。
- Seedance2.0支援環境音效、角色台詞、背景音樂三種音訊類型的原生同步生成,支援100+種語言和方言,具備降噪、音色最佳化、音量均衡等功能,音訊質量達到專業級(48kHz採樣率);
- Sora音訊生成能力初級,僅支援簡單環境音效,不支援角色台詞生成,音畫同步差;
- Kling支援角色台詞生成,但音色生硬、雜音較多,缺乏音量均衡最佳化;
- Runway支援音訊生成,但需要手動調整音訊參數,且音效與場景的適配度較低。
4. 編輯便捷性:Seedance2.0兼顧便捷與專業。
- Seedance2.0內建輕量化線上編輯工具,支援鏡頭剪輯、音訊調整、字幕加入、水印加入等功能,普通使用者無需專業知識即可上手,同時支援匯出原始工程檔案,適配PR、AE等專業後期工具,兼顧普通使用者與專業創作者;
- Sora無內建編輯工具,生成內容需要匯出後使用第三方工具編輯,便捷性差;
- Kling內建簡單編輯工具,但功能有限(僅支援剪輯、音量調整),無法滿足商用編輯需求;
- Runway編輯功能強大,但側重專業後期,普通使用者使用門檻高,且編輯流程複雜。
5. 風格化適配能力:Runway最優,Seedance2.0均衡。
- Runway Gen-3的風格化生成能力最強,支援多種影視風格( noir黑色電影、好萊塢大片等)、動漫風格、插畫風格,適配專業創作者的風格化需求;
- Seedance2.0支援常見的15+種風格(古風、現代、動漫、科幻等),風格還原度高,且能夠結合多鏡頭敘事,適配大多數商用場景的風格需求;
- Sora側重物理真實風格,風格化適配能力弱;
- Kling支援簡單風格化生成,但風格種類有限,還原度一般。
2.4.2 典型場景體驗對比
為更直觀體現功能體驗差異,選取三個典型商用場景,對比四大模型的實際表現:
場景1:中小企業廣告生成(需求:1分鐘2K廣告,多鏡頭,包含產品展示、角色講解,原生音訊,無需後期編輯)。
- Seedance2.0:60秒生成,多鏡頭流暢,角色講解嘴型與台詞同步,產品細節清晰,可直接用於投放;
- Sora:125秒生成,僅單鏡頭,無角色台詞,需要後期配音、剪輯,無法直接商用;
- Kling:85秒生成,多鏡頭生硬,角色講解音色生硬、音畫不同步,產品細節模糊,需要後期最佳化;
- Runway:130秒生成,多鏡頭需要手動設計,音訊需要後期調整,編輯門檻高,不適合中小企業快速投放。
場景2:短影片創作者內容生成(需求:30秒2K短影片,多鏡頭,古風風格,包含角色動作、背景音樂,簡單編輯即可發佈)。
- Seedance2.0:30秒生成,古風風格還原度高,多鏡頭流暢,背景音樂適配場景,內建編輯工具可快速加入字幕、水印,直接發佈;
- Sora:無法生成多鏡頭,且風格化適配差,不適合;
- Kling:42秒生成,古風風格還原度一般,多鏡頭切換生硬,音訊雜音多;
- Runway:65秒生成,古風風格還原度高,但需要手動設計分鏡、調整音訊,編輯耗時久。
場景3:專業影視後期輔助(需求:1分鐘2K科幻短片片段,高畫質,複雜物理特效,專業編輯適配)。
- Sora:物理特效還原度最高,畫質保真,適合作為後期素材,但需要大量後期配音、編輯;
- Runway:風格化適配強,編輯功能強大,可直接匯入PR、AE最佳化,但生成速度慢;
- Seedance2.0:畫質清晰,物理特效還原度略遜於Sora,但多鏡頭連貫、音畫同步,可直接作為片段使用,編輯便捷;Kling:物理特效還原度差,不適合該場景。 (AI雲原生智能算力架構)