

一、結論
1.sora模型的核心創新在於,它將影片中的每一幀影像視為一連串的標記進行訓練,這讓模型能夠根據輸入,產生高品質的影片。另外,Sora模型採用的Diffusion Transformer架構,能夠透過預測原始"乾淨"的補丁來從輸入的噪音補丁中產生視訊。
2.Sora大模型發布後,中國外投資人都在猜測到底需要多少算力才能複製類似的大模型。目前市場上說法有較大差異:券商研究報告中給出較為激進的演算法,出發點雖然不同,但都能得出相似的結論,即OpenAI所需算力是現在的幾十倍;技術派則一致認為Sora模型的真實參數不大,預期只有30億,因此認為算力需求不高。
3.目前中國華為的910B晶片算力能與A100媲美,性能預期能達到其80%以上,互聯速度能達到400GB,算力集群的使用效率可能經常會不到50%。國產算力晶片與英偉達晶片確實存在差距,但中國晶片性能逐漸在不斷提升,考慮到供應鏈安全問題,中國科技大廠已經開始購買華為等國產晶片,過程AI晶片預期迎來高光時刻。
二、技術派一致認為Sora模型參數不高,算力需求不多
根據官網訊息,目前Sora可產生最長約60S的視頻,較先前發布的文生視頻模型如Pika、Runway等,視頻時長有明顯提升。畫質方面,Sora支援解析度達2048×2048,呈現效果突出。OpenAI表示Sora能夠產生複雜的場景,不僅包括多個角色,還有特定的動作類型,以及對物件和背景的準確細節描繪。此外,Sora有時可以用簡單的方式模擬影響真實世界的具體動作,例如“一個男人可以吃漢堡並留下咬痕”,這是之前的文本生成視頻難以達到的能力。
雖然Sora模型生成視訊效果顯著,但從技術角度而言Sora本身所需參數並不多。因Sora模型並未開源,現在網路上的各種說法也只是基於其過往學術經驗得出結論,只能說短期內無法被證偽。
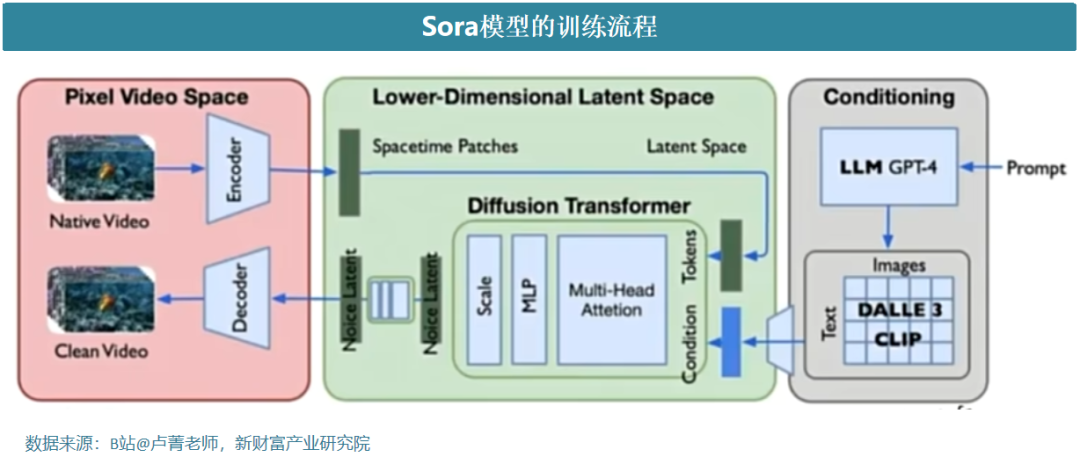
B站盧菁老師認為Sora模型=VAE encoder+DiT (DDPM)+VAE decoder+CLIP,Sora整體訓練流程如下圖所示,包括視訊編碼(紅色區域)+Stable diffusion(DiT,綠色區域)+語言模型(灰色區域),具體訓練如下所示:
(1)Encoder的作用是將圖片&影片的Patch進行壓縮,得到一個向量長度變短Patch,這裡面會涉及到Latent Space(隱空間),而Stable diffusion就是在這個隱空間進行計算的。Decoder的作用則和Encoder相反,用於圖片還原。
(2)擴散模型Stable diffusion的原理是用通過噪聲or噪聲+提示詞的方式產生圖像,模型輸入被污染的圖像or輸入被污染的圖像+用戶提示詞,模型輸出污染的噪聲,然後通過污染圖像-污染雜訊=原始影像。為了確保影片的一致性,Sora模型參考了Google的W.AL.T的工作內容,60s應該是一次性全部生產的,不是透過多個stage方式來進行影片預測,而是預測了整個影片的latent ,同時在訓練過程中應該引入了autoregressive的task來去幫助模型更好地進行視訊特徵和幀間關係的學習。
(3)使用者的提示詞輸入後,首先會透過GPT-4大語言模型進行提示詞擴寫,然後再透過文生圖模型(DALL-E CLIP)模型產生影像向量,這個向量作為擴散模型的輸入項的一部分。
從上述解釋可以看到訓練的樣本有以下的特點:
(1)Sora訓練樣本其實是圖像/影片+文字=資料對,所以訓練資料量沒有GPT那麼多,但會牽涉到大規模的標記。這裡用到了Re-captioning技術,也就是透過一張影像產生對應的文字描述,透過這個技術可以補償訓練集。
(2)因為影片轉換為了向量序列,所以對影像的尺寸不再有要求,就不需要對影片進行裁切等操作。
(3)影片和圖像用一套訓練方法解決,擴充了訓練樣本。
因此,Sora模型參數預期不大。GPT的參數=token embedding+Transformer的參數,而embedding過程是需要每個單字都要進行token化,而Sora模型是直接把圖片像素計算後轉換成向量,沒有token embedding這個過程。另外,語言是人類發明的抽象訊號,而圖像是自然訊號相對更容易被理解,所需Sora模型的Transformer層數預期也會降低。
其他技術專家給的分析過程雖會有部分差異,但最後結論差異不大。例如,紅博士在公眾號上寫的《去魅Sora: OpenAI 鮮肉小組的小試牛刀》中提到:Sora是採用了Meta的DiT (2022.12) 框架,融合了Google的MAGViT (2022.12) 的Video Tokenize方案,借用Google DeepMind的NaViT (2023.07) 支援了原始比例和分辨率,使用OpenAI DALL-E 3 (2023.09) 裡的圖像描述方案生成了高質量Video Caption(視頻描述),即文本-視頻對,實現了準確的條件生成。
三、券商預測Sora算力需求是現在模型的50倍+
券商研究報告中給出較為激進的演算法,出發點雖然不同,但都能得出相似的結論,即OpenAI所需算力是現在的幾十倍下面是券商報告中常見的2種計算方式:
第一種方式是透過模型訓練所需的token數來估算,以下是華西證券給出的計算過程:
(1)根據AI新智界數據,ChatGPT-3的參數為1750億,訓練數據的token為3000億,訓練所需每秒浮點運算為3.14x10^23FLOPS;假設訓練數據精度為FP16,英偉達H100FP16每秒浮點運算為989.5TFLOPS(T=10^12),假設訓練10天,需要英偉達H100卡數為3.14 x 10 ^ 23 ÷989.5÷ 10^12 ÷(60 x 60 x 24 x10)=367.28888 368張;
(2)根據部落格園引用Google論文《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》,例如對於CIFAR-10,一般的設定是大小為16 x 16 x 3 (3代表3原色,自然界的每種顏色可以透過紅、綠、藍三種顏色表示,AI模型的圖片本質即像素點) 的patch,因此假設SORA適用16 x 16 x 3的patch 表示一串有損表示影像的tokens;影像的輸入資料不是一個字符,而是一個像素。假設每個像素有C個頻道,圖片有寬W和高H,因此一張圖片的所有資料可以用一張大小為H x W x C 的張量來無損地表示。假設C=3 (3代表3原色);
(3)根據澎湃新聞數據,Runway GEN-2模型由2.4 億張圖片和640 萬個視頻片段組成的內部數據集上訓練,我們判斷SORA架構的訓練參數比GEN-2更大,然而為了方便計算,因此假設SORA與Runway GEN-2所訓練的資料量相同。假設每一張圖片分別為1920 x 1080分辨率,每個視頻分別為30秒30FPS,因此patch大小為[(2.4 x 10^8)+ (6.4 x 10 ^7 x 30 x 30)] x 1920 x 1080 x 3= 3.73 x 10 ^ 16;將Patch大小轉換成token 大小即(3.73 x 10 ^ 16) ÷ (16 x 16 x 3)= 4.86 x 10 ^ 13;
(4)Transformer架構持續升級,所需參數量可望增加,然而為了方便計算,我們假設SORA應用的Transformer架構與ChatGPT Transformer架構相同,且參數量相同,同時假設資料精度為FP16,假設訓練10天,則需要英偉達H100卡數為(4.86 x 10 ^ 13) ÷ (3 x 10^11) x 367.28=59499.74 ≈ 59500張。推算Sora架構的訓練與傳統大語言模型( LLM ) Transformer架構的訓練算力需求有近百倍差距。
另一種計算方式與2月9號OpenAI的「7兆美元」AI基礎建設項目傳聞有關,雖2月28號被山姆否認,但仍可作為參考。透過直接購買GPU或建廠的方式計算GPU需求量,國君電話會議中計算得到的GPU供給量預期是現在的50倍+:
(1)以目前市場售價,H100晶片大概三、四萬美元一顆,7兆美金÷3萬美金=2.5億顆,目前全球GPU供給大約是400萬億顆,因此7兆美金的投資可以使得GPU的供給擴大近50倍。
(2)台積電數據顯示,建造一個月產10萬片的3奈米級晶圓的生產線,成本大概在300億到400億美金(以400億美金計算),其他的HPM等成本計算在內則總投入在700億美金左右。考慮到某些配套情況,一片晶圓大約能產生30顆GPU的良品率,一個生產線每年可以產出約300萬顆GPU(不同工序需要時間錯配),100條產線(7兆/700億)則生產3億顆GPU。
第一種演算法沒有考慮實際計算過程中算力利用率降低的情況,計算結果預期會有誤差。而這種演算法並未考慮隱藏空間的問題,因此這種演算法的可信度較低。第二種演算法所得到的算力需求預期與OpeaAI未發表產品有關,與Sora關聯度不大。
(1)根據研究資料:GPT-3模型有96層Transformer,參數為1750億;這GPT4 的參數量大約是1.9兆,模型層數是100多層;GPT-5 參數量預計將達到10萬億級,層數將超過1000層,大概是1300多層。如果單純從參數量來看,GPT-5是GPT-3的57倍,線性外推算力增加50倍也不算太過分。
(2)網路上流傳的Q*模型參數預期達到125萬億,參數是GPT3的714倍。

四、中國國產AI晶片高光時刻來臨
中國大廠一直在積極訓練自己的大模型,這些需求大量算力,這給中國AI晶片廠商製造了機會。23年10月美國限制向中國出售更先進的人工智慧晶片,包括Nvidia H800、A800,AMD、Intel等相關AI晶片。《華爾街日報》報道美國對中共晶片監管有進一步措施,本來英偉達11月中旬要交付50億美元訂單現在因為新的規則或被迫取消。11月8日晚上,網傳英特爾近期計劃在中國大陸市場推出Gaudi2降規版產品。
「改良版」晶片H20參數,連網頻寬從原來的400GB提升至900GB,訓練速度應該是平方關係,如果FLOPS不變,依道理訓練速度提升4倍。但FLOPS從A100的FP16 312TFLOPS,以及H100的756TFLOPS,直接閹割到148TFLOPS,也就是H100的20%,A100的不到50%。
目前中國華為的910B晶片算力能與A100媲美,性能預期能達到其80%以上,互聯速度據說能達到400GB。做集群的時候互聯速度尤其重要,因此算力集群的使用效率可能經常會不到50%。下圖是某大廠測試得到結果,可以看出隨著伺服器台數的增加,華為910B算力利用率就會迅速降級,256台8卡伺服器的集群效果還不如H20。
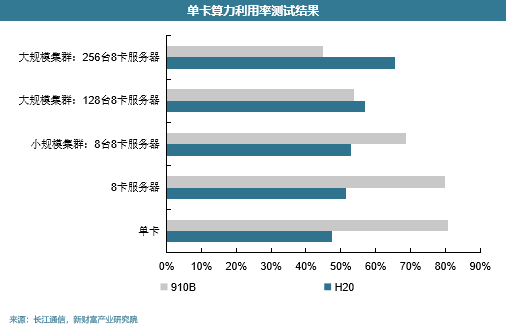
中國國產算力晶片與英偉達晶片確實存在差距,但中國晶片性能逐漸在不斷提升,考慮到供應鏈安全問題,中國科技大廠已經開始購買華為等國產晶片,過程AI晶片預期迎來高光時刻。
(1)百度在8月開始已向華為訂購1600枚 AI晶片昇騰910B。晶片將用於200台伺服器,目前華為已向百度交付超過1000枚,計劃在年底前完成全部交付,這批伺服器總金額預期為6200萬美金。先前百度主要依靠英偉達的A100來訓練其大模型。
(2)11月8日的2023年世界互聯網大會烏鎮峰會上,360集團創始人周鴻禕在接受媒體採訪時稱, 360也採購了華為1000片左右的AI芯片,並與華為合作將AI框架移植到了異騰910B上。(新財富)