
什麼是CUDA
CUDA(Compute Unified Device Architecture),統一計算裝置架構,輝達推出的基於其GPU的通用高性能計算平台和程式設計模型。
借助CUDA,開發者可以充分利用輝達GPU的強大計算能力加速各種計算任務。
軟體生態的基石:CUDA構成了輝達軟體生態的基礎,諸多前沿技術均基於CUDA建構。
例如,TensorRT、Triton和Deepstream等,這些技術解決方案都是基於CUDA平台開發的,展示了CUDA在推動軟體創新方面的強大能力。
軟硬體的橋樑:輝達的硬體性能卓越,但要發揮其最大潛力,離不開與之相匹配的軟體支援。
CUDA正是這樣一個橋樑,它提供了強大的介面,使得開發者能夠充分利用GPU硬體進行高性能計算加速。
就像駕駛一輛高性能汽車,CUDA就像是一位熟練的駕駛員,能夠確保硬體性能得到充分發揮。
深度學習框架的加速器:CUDA不僅在建構輝達自身的軟體生態中扮演關鍵角色,在推動第三方軟體生態發展方面也功不可沒。
特別是在深度學習領域,CUDA為眾多深度學習框架提供了強大的加速支援。
例如,在Pytorch、TensorFlow等流行框架中,CUDA加速功能成為標配。
開發者只需簡單設定,即可利用GPU進行高效的訓練和推理任務,從而大幅提升計算性能。
CPU+GPU異構計算
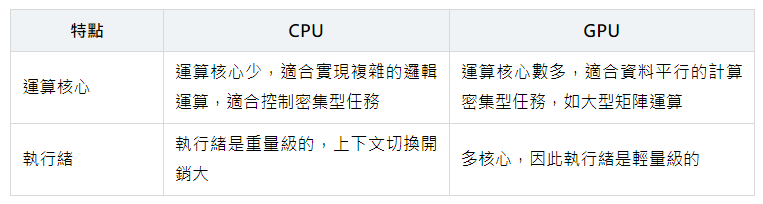
CPU:中央處理器(Central Processing Unit)作為電腦系統的運算和控制核心,是資訊處理、程式執行的最終執行單元。
運算核心較少,但是其可以實現複雜的邏輯運算,因此其適合控制密集型任務,CPU更擅長資料快取和流程控制——(少量的複雜計算)
GPU:圖形處理器(Graphics Processing Unit),常被稱為顯示卡,GPU最早主要是進行圖形處理的。
如今深度學習大火,GPU高效的平行計算能力充分被發掘,GPU在AI應用上大放異彩。
GPU擁有更多的運算核心,其特別適合資料平行的計算密集型任務,如大型矩陣運算——(大量的簡單運算)
一個典型的 CPU 擁有少數幾個快速的計算核心,而一個典型的 GPU 擁有幾百到幾千個不那麼快速的計算核心。
CPU的電晶體設計更多地側重於資料快取和複雜的流程控制,而GPU則將大量電晶體投入到算術邏輯單元中,以實現平行處理能力。
因此,GPU正是通過其眾多的計算核心叢集來實現其相對較高的計算性能。
使用CUDA程式設計,開發者可以精確地指定資料如何被分配到GPU的各個核心上,並控制這些核心如何協同工作來解決問題。
GPU不能單獨進行工作,GPU相當於CPU的協處理器,由CPU進行調度,CPU+GPU組成異構計算架構。
在由 CPU 和 GPU 構成的異構計算平台中,通常將起控製作用的 CPU 稱為主機(host),將起加速作用的 GPU 稱為裝置(device)。
主機和裝置之間記憶體訪問一般通過PCle匯流排連結。
計算生態
#開發工具鏈
①NVIDIA driver
· 顯示卡驅動是連接作業系統和顯示卡硬體之間的橋樑,確保顯示卡能夠正常工作並行揮最佳性能。
· 顯示卡驅動包含硬體裝置的資訊,使得作業系統能夠識別並與顯示卡硬體進行通訊。
· 顯示卡驅動對於啟用顯示卡的全部功能、性能最佳化、遊戲和應用程式相容性以及修復問題和安全更新都至關重要
②CUDA Toolkit
· CUDA Toolkit是一個由NVIDIA開發的軟體開發工具包,它為NVIDIA GPU提供了一組API和工具,使得開發人員可以利用GPU的平行計算能力來加速計算密集型應用程式。
· CUDA Toolkit包括CUDA編譯器(NVCC)、CUDA執行階段庫、CUDA驅動程式等元件,它們協同工作,使得開發人員可以使用C或C++編寫GPU加速的程式碼。
③CUDA API
· CUDA API是CUDA程式設計的介面集合,它允許開發者使用CUDA進行高性能計算。
· CUDA API包括CUDA Runtime API和CUDA Driver API,它們提供了用於管理裝置、記憶體、執行等功能的函數。
· 開發者可以通過CUDA API來編寫CUDA程序,以利用GPU的平行計算能力。
④NVCC
· NVCC是CUDA的編譯器,屬於CUDA Toolkit的一部分,位於執行階段層。
· NVCC是一種編譯器驅動程式,用於簡化編譯C++或PTX程式碼。它提供簡單且熟悉的命令列選項,並通過呼叫實現不同編譯階段的工具集合來執行它們。
· 開發者在編寫CUDA程序時,需要使用NVCC來編譯包含CUDA核心語言擴展的原始檔。
NVIDIA driver是確保顯示卡正常工作的基礎,而CUDA Toolkit則是利用GPU進行高性能計算的軟體開發工具包。
CUDA API是CUDA程式設計的介面,而NVCC則是CUDA的編譯器,用於將CUDA程序編譯成可在GPU上執行的程式碼。
應用框架與庫支援
CUDA廣泛支援各類科學計算、工程、資料分析、人工智慧等領域的應用框架和庫。
例如,在深度學習領域,TensorFlow、PyTorch、CUDA Deep Neural Network Library (cuDNN) 等工具均深度整合了CUDA,使得開發者可以輕鬆利用GPU加速神經網路訓練和推理過程。
#深度學習框架
· TensorFlow:TensorFlow是Google開發的開源機器學習框架,它支援分散式運算,並且可以高效地使用GPU進行數值計算。TensorFlow在底層使用了CUDA和cuDNN等NVIDIA的庫來加速深度學習模型的訓練和推理過程。
· PyTorch:PyTorch是Facebook人工智慧研究院(FAIR)開發的深度學習框架。PyTorch也支援CUDA,並且提供了豐富的API來讓開發者輕鬆地使用GPU進行深度學習模型的訓練和推理。PyTorch和CUDA的版本之間存在一定的相容性關係,需要確保PyTorch的版本與CUDA的版本相容。
#CUDA庫
· cuBLAS:用於線性代數運算的庫,如矩陣乘法、前綴求和等,常用於科學和工程計算。
· cuDNN:NVIDIA CUDA深度神經網路庫(cuDNN)是一個用於深度學習的GPU加速庫,提供了一系列深度學習演算法的高效實現。
· cuSPARSE:針對稀疏矩陣的線性代數庫。
· cuFFT:快速傅里葉變換庫,用於執行高效的FFT(快速傅里葉變換)操作。
· cuRAND:隨機數生成庫,允許開發者在GPU上生成隨機數。
這些庫為開發者提供了豐富的計算資源,使他們能夠更高效地開發GPU加速的應用程式。
CUDA程式語言
C、C++、Fortran、Python 和 MATLAB (槿墨AI)