
阿里迄今為止,參數最大的模型誕生了!

昨夜,Qwen3-Max-Preview(Instruct)官員宣上線,超1兆參數性能爆表。
直接用成績說話——
在全球主流權威基準測試中,Qwen3-Max-Preview狂攬非推理模型「C」位,直接碾壓Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
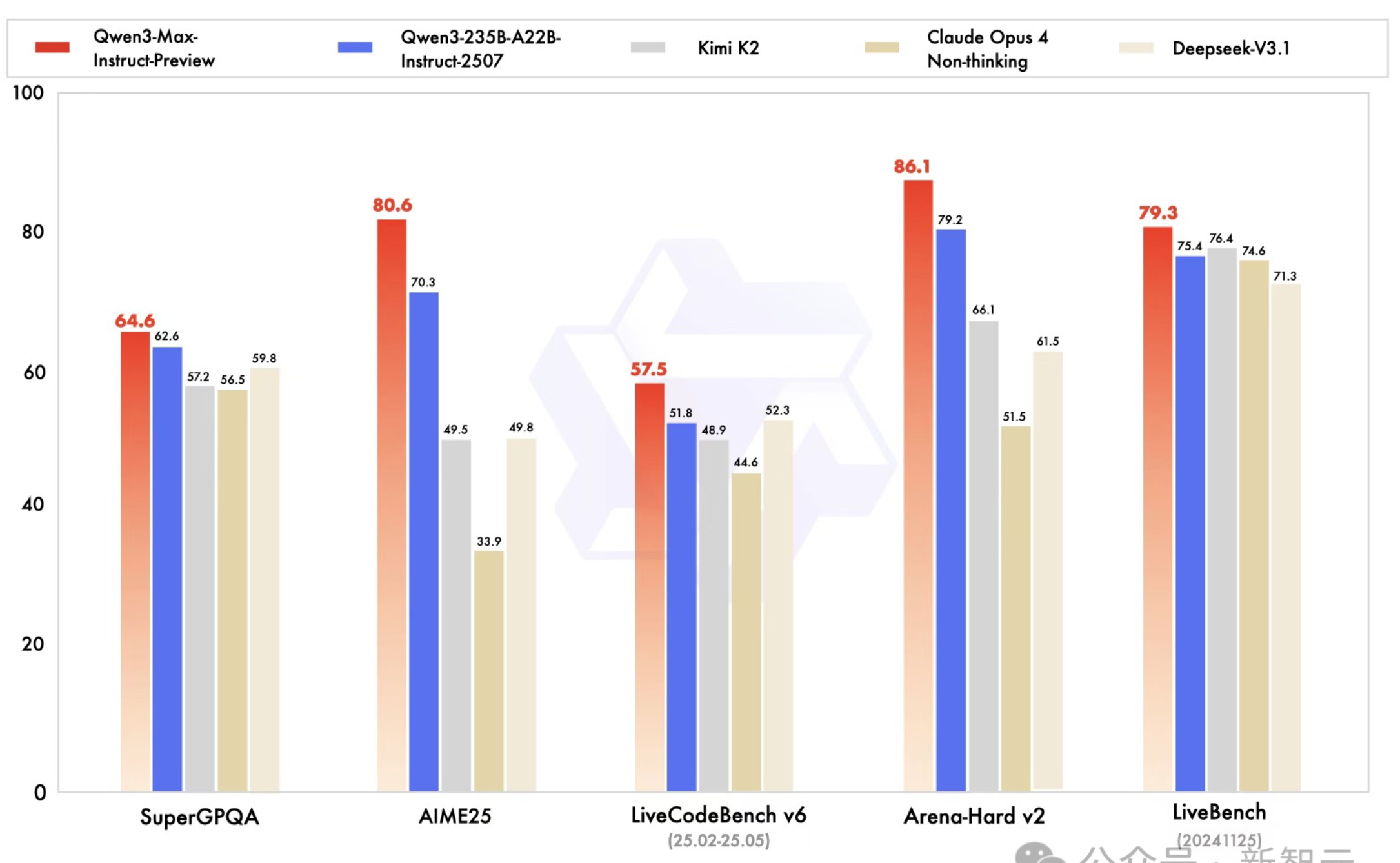
甚至,它把自家Qwen3-235B-A22B-Instruct-2507狂甩身後,堪稱「AI卷王本王」。
- 知識推理評測(SuperGPQA)拿下64.6分
- 數學推理評測(AIME25)拿下80.6分,斷崖式領先
- 競爭程式設計評測(LiveCodeBench V6)拿下57.5分
- 複雜問題解決和人類偏好對齊評測(Arena-Hard v2)拿下86.1分,優勢巨大
- 被稱為「無法被操控的」評測(LiveBench)拿下79.3分
驚豔的性能表現再次證明了,Scaling仍然有效,參數越大模型性能越強。
總的來說,Qwen3-Max-Preview有以下幾大亮點:表現更強、知識更廣、更擅長對話、任務處理、指令遵循。
新模型可支援100+語言,還針對RAG、工具呼叫進行最佳化。
模型一出,全網立即開始了實測。
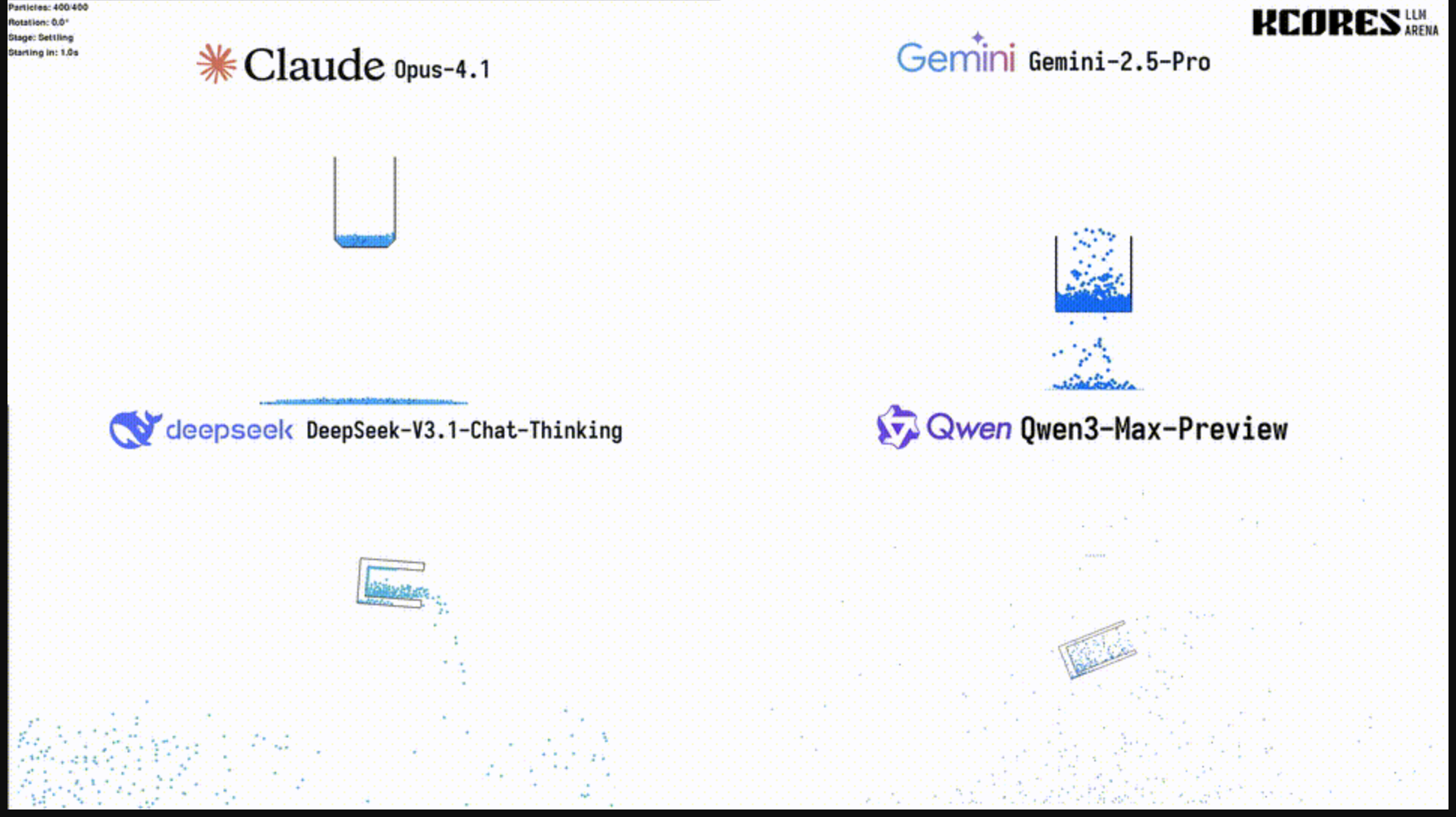
@karminski-牙醫實驗中,Qwen3-Max-Preview前端能力明顯超越DeepSeek-V3.1。

例如,在一個杯子流體模擬中,Gemini 2.5在傾倒前杯子底部有嚴重bug,DeepSeek-V3.1杯子中物體倒出的狀態(最後有一條線)不對,而Qwen3-Max-Preview比較符合物理常識。
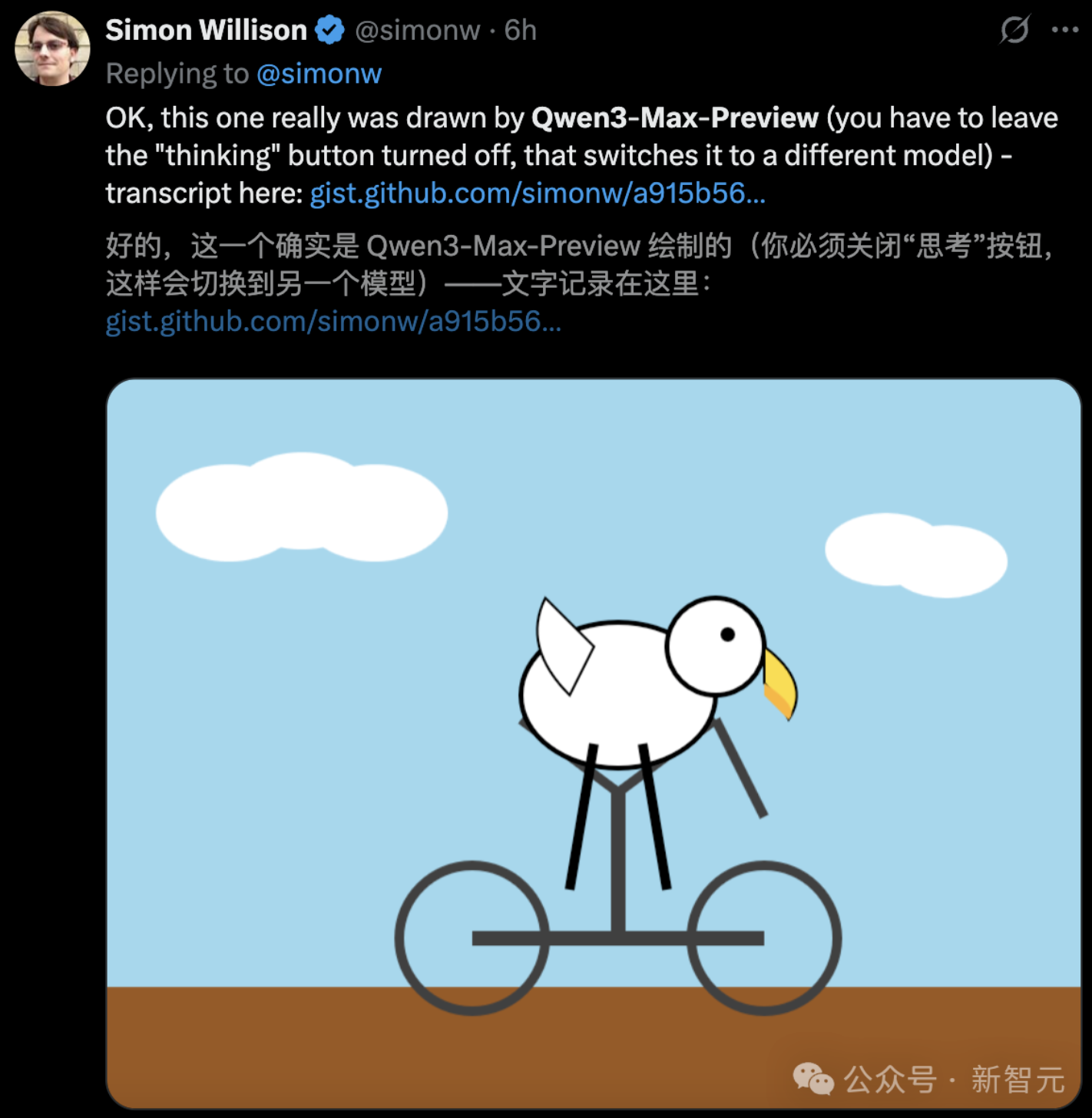
Qwen3-Max-Preview還能完美產生一個騎自行車的鵜鶘SVG、一鍵直出精美前端網頁,一張照片做出像素花園。
目前,模型已正式上線阿里雲百煉平台,可透過API直接呼叫。同時,Qwen Chat也同步上線新模型,支援免費使用。
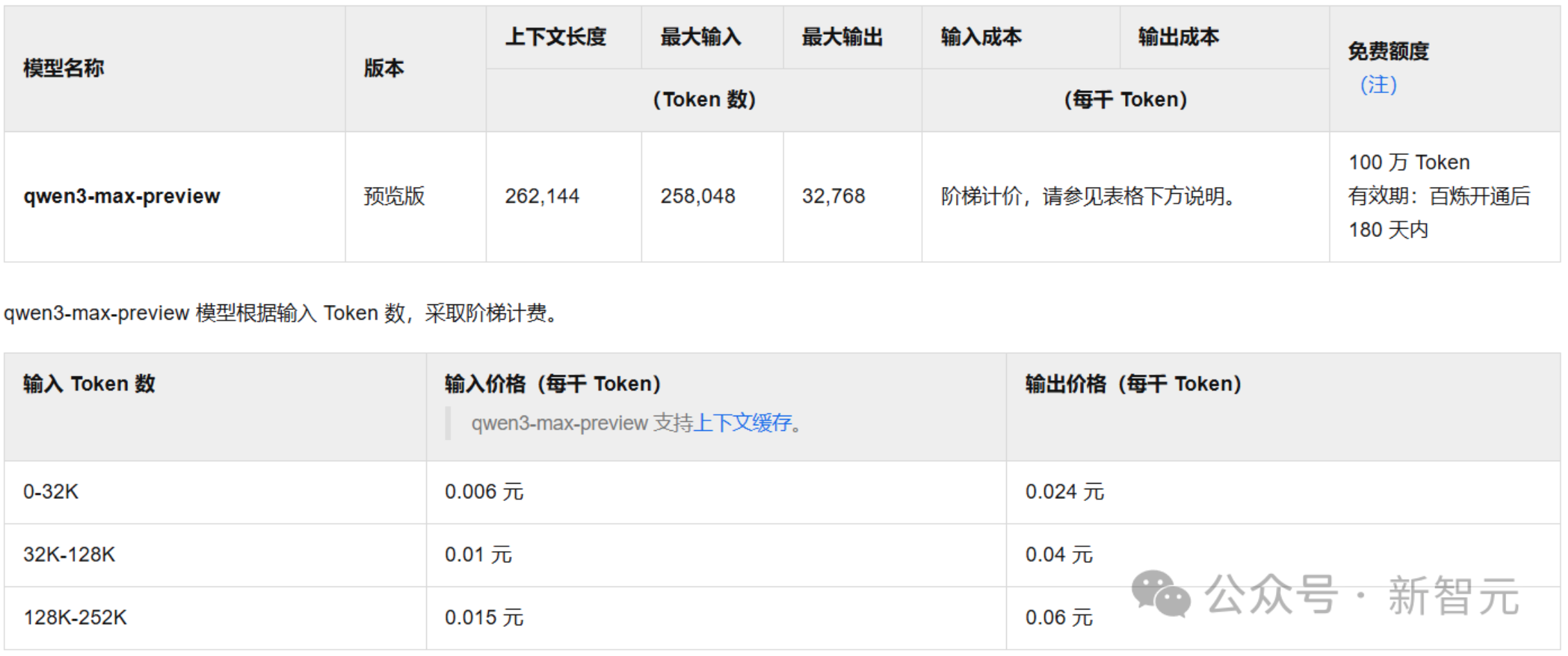
在百煉平台上,最大支援256k上下文,依token數階梯計費:
- 0-32k token:輸入0.006元/千token;輸出0.024元/千token
- 32k-128k token:輸入0.01元/千token;輸出0.04元/千token
- 128k-252k token:輸入0.015元/千token;輸出0.06元/千token (新智元)