
Rubin 是多少張 GPU 互聯?比現在最強的資料中心性能強多少?——本報告的分析結論如下:
- 互聯規模的代際跨越:Rubin 架構引入了 Vera Rubin NVL144 平台,在一個機架內實現了 144 個 GPU 計算核心(Die) 的全互聯 1。這不僅在物理數量上是前代 Blackwell NVL72(72 個 GPU)的兩倍,更重要的是,通過第六代 NVLink(NVLink 6)技術,這 144 個核心建構了一個單一的、記憶體一致的邏輯計算域。這意味著模型可以像在一個巨大的 GPU 上運行一樣,在 144 個核心之間無縫共用記憶體和資料,徹底消除了節點間通訊的延遲瓶頸。
- 性能增益的多維躍遷:相比當前最強的資料中心基準——Blackwell GB200 NVL72,Rubin 展現了多維度的性能提升:
- AI 推理性能(FP4):提升幅度約為 3.3 倍,達到 3.6 Exaflops 1。
- 海量上下文處理(CPX):針對百萬級 token 的長上下文任務,Rubin CPX 平台的性能是 Blackwell 的 7.5 倍2。
- 記憶體頻寬:整機架聚合頻寬從 NVL72 的 576 TB/s 激增至 1.7 PB/s,約為 3 倍 的提升 2。
本報告將深入探討驅動這些數字背後的技術邏輯,包括 3nm 工藝製程、HBM4 記憶體革命、銅纜互聯物理學以及 600kW 功率密度帶來的熱力學挑戰。
2. 宏觀背景:計算通膨與推理時代的黎明
要理解 Rubin 架構的設計初衷,必須首先審視當前 AI 產業面臨的根本性矛盾:計算通膨(Computation Inflation) 與 記憶牆(Memory Wall) 的雙重擠壓 4。隨著大語言模型(LLM)從單純的文字生成轉向具備多步邏輯推理能力的“Agentic AI”(代理智能),計算範式正在發生深刻的轉移。
2.1 從訓練原生到推理原生
在 Hopper(H100)時代,資料中心的主要任務是模型訓練,這要求極高的浮點運算能力。然而,隨著模型部署的普及,推理(Inference)——尤其是長上下文、高並行的推理——成為了算力消耗的主體。Blackwell 架構通過引入 FP4 精度初步應對了這一挑戰,但 Rubin 則是為**“推理原生”**時代徹底設計的 2。
Rubin 的出現不僅僅是為了更快的訓練,更是為瞭解決“百萬 Token 級”上下文的即時處理問題。在這一場景下,瓶頸不再是計算核心的速度,而是資料搬運的速度。因此,Rubin 架構的核心哲學可以概括為:以頻寬換算力,以互聯換延遲。
2.2 摩爾定律的終結與系統級擴展
隨著電晶體微縮逼近物理極限,單晶片性能的提升日益艱難。輝達 CEO 黃仁勳明確指出,未來的性能提升將不再依賴單一晶片,而是依賴“資料中心即晶片”的系統級設計 4。Rubin 架構正是這一理念的極致體現:它不再試圖製造一個超強的 GPU,而是試圖製造一個超強的機架(Rack),並讓這個機架在軟體層面表現為一個單一的邏輯單元。
3. 矽基架構:Vera Rubin 超級晶片的技術解構
Rubin 平台的核心建構模組是 Vera Rubin Superchip。這一異構計算模組整合了定製化的 Vera CPU 和下一代 Rubin GPU,通過 NVLink-C2C 實現晶片級的高速互聯。
3.1 Rubin GPU 微架構:3nm 與雙芯封裝
Rubin GPU 將採用台積電(TSMC)的 3nm 工藝(預計為 N3P 或後續最佳化版本)製造 6。相比 Blackwell 使用的 4NP 工藝,3nm 節點提供了顯著的電晶體密度提升和能效最佳化,這是在有限的功耗預算下實現性能翻倍的物理基礎。
3.1.1 封裝策略:Die 與 GPU 的定義重構
在分析 Rubin 的規格時,必須澄清輝達術語體系的變化。在 Blackwell B200 中,一個封裝(Package)包含兩個計算裸片(Compute Die)。在 Rubin 這一代,這種設計得到了延續並擴展:
- 標準 Rubin GPU:包含 2 個全光罩尺寸(Reticle-sized)的計算裸片7。
- Rubin Ultra(2027年):預計將包含 4 個計算裸片1。
因此,當我們討論 NVL144 時,我們指的是 72 個物理封裝,每個封裝內含 2 個裸片,總計 144 個計算核心1。這種設計使得輝達能夠在不突破光刻機掩膜版尺寸限制(Reticle Limit)的前提下,持續擴大單晶片的有效面積。
3.1.2 記憶體革命:HBM4 的引入
Rubin 架構最關鍵的技術躍遷在於首發搭載 HBM4(High Bandwidth Memory 4) 記憶體 6。相比 Blackwell 使用的 HBM3e,HBM4 帶來了質的飛躍:
- 位寬翻倍:HBM4 將記憶體介面位寬從 1024-bit 擴展至 2048-bit8。這使得在同等時脈頻率下,頻寬直接翻倍。
- 堆疊工藝:HBM4 採用了邏輯裸片與記憶體裸片的混合鍵合(Hybrid Bonding)技術,甚至可能直接堆疊在 GPU 邏輯晶片之上(3D 堆疊),從而大幅降低訊號傳輸的功耗(pJ/bit)。
- 容量與頻寬:每個 Rubin GPU 封裝配備了 288GB HBM4 記憶體,頻寬高達 13 TB/s7。作為對比,Blackwell B200 的頻寬僅為 8 TB/s。這額外增加的 5 TB/s 頻寬,是 Rubin 能夠在推理任務中大幅領先 Blackwell 的核心物理原因。
3.2 Vera CPU:徹底的架構自主
與 Grace CPU 採用 ARM 標準 Neoverse 核心不同,Vera CPU 採用了輝達完全自訂的 ARM 架構核心 9。
- 核心規格:單顆 Vera CPU 擁有 88 個物理核心,支援 176 個線程(SMT)11。
- 戰略意義:Vera 的出現標誌著輝達在計算全端上的進一步收束。通過自訂核心,輝達可以針對 AI 資料預處理、CUDA 核心調度以及網路協議棧進行指令集等級的最佳化,進一步降低 CPU-GPU 之間的通訊延遲。Vera 與 Rubin 之間通過 1.8 TB/s 的 NVLink-C2C 互聯 1,確保了 CPU 記憶體與 GPU 視訊記憶體處於統一的定址空間。
3.3 Rubin CPX:為“百萬上下文”而生
在標準版 Rubin 之外,輝達還規劃了 Rubin CPX 變體。這是一個專為處理極長上下文(Massive Context)設計的 SKU 2。
- 技術痛點:在處理長文件或生成長視訊時,Transformer 模型的 KV-Cache(鍵值快取)會佔用海量視訊記憶體,且注意力機制(Attention Mechanism)的計算複雜度隨序列長度呈二次方增長。
- CPX 解決方案:Rubin CPX 並沒有單純堆砌 FP4 算力,而是整合了專用的硬體單元來加速注意力計算,並最佳化了視訊記憶體管理機制。據官方資料,CPX 在百萬 token 級任務上的表現是 Blackwell 系統的 7.5 倍3。這表明 CPX 可能採用了類似於“Ring Attention”的硬體加速技術,利用 NVLink 6 的高頻寬在多個 GPU 間高效流轉 KV 塊。
4. 互聯拓撲:NVLink 6 與 144 芯互聯架構(回答“是多少張GPU互聯”)
回答使用者“是多少張GPU互聯”的核心在於解析 NVLink 6 互聯技術與 NVL144 機架架構。這是 Rubin 區別於所有競爭對手的護城河。
4.1 NVL144:單一機架內的超級電腦
Rubin 架構的旗艦形態是 Vera Rubin NVL144。這是一個液冷機架系統,其互聯規模達到了前所未有的高度:
- 互聯數量:144 個 GPU 計算核心(Die)1。
- 物理形態:72 個 Rubin GPU 封裝(每個含 2 個 Die) + 36 個 Vera CPU 1。
- 互聯性質:全互聯、無阻塞(Non-blocking)、記憶體一致性域。
在 NVL144 中,任意一個 GPU 都可以通過 NVLink Switch 直接訪問機架內其他 143 個 GPU 的 HBM4 記憶體,且訪問速度高達 3.6 TB/s。這與傳統的乙太網路或 InfiniBand 互聯有著本質區別:在軟體看來,這 144 個 GPU 就是一個擁有 ~41 TB 統一視訊記憶體(288GB x 144)的巨型 GPU。
4.2 NVLink 6:銅纜的物理極限
支撐這一互聯規模的是第六代 NVLink 技術。
- 頻寬翻倍:NVLink 6 的雙向頻寬提升至 3.6 TB/s,是 Blackwell 所用 NVLink 5(1.8 TB/s)的 2 倍8。
- 機架總頻寬:NVL144 機架背板的交換容量高達 260 TB/s1。
- 物理介質:為了在機架內實現如此高的密度和極低的延遲,輝達繼續採用了**銅纜背板(Copper Backplane)**設計 13。儘管業界對光學互聯(Silicon Photonics)呼聲甚高,但在機架內部(<2米距離),銅纜依然具有功耗低、無需光電轉換延遲的優勢。NVL144 的背板是一個工程奇蹟,它整合了超過 5000 根高速銅纜,構成了一個類似脊椎的通訊骨幹。
4.3 與 Blackwell NVL72 的對比
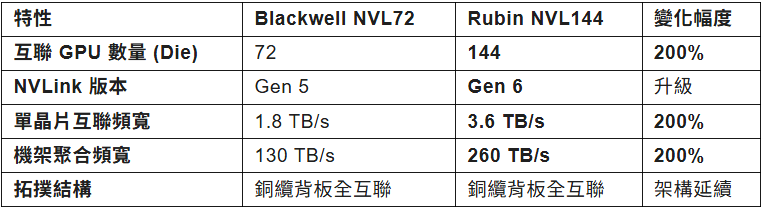
通過對比可見,Rubin 並非簡單的數量堆砌,而是通過互聯頻寬的翻倍來支撐節點數量的翻倍,從而保證了**網路直徑(Network Diameter)**不隨節點增加而惡化,維持了極低的通訊延遲。
5. 性能基準:超越最強資料中心(回答“強多少”)
使用者關注的第二個核心問題是:“比現在最強的資料中心性能強多少?” 目前的基準是 Blackwell GB200 NVL72。Rubin 的性能提升並非單一數值,而是根據工作負載的不同呈現出分層差異。
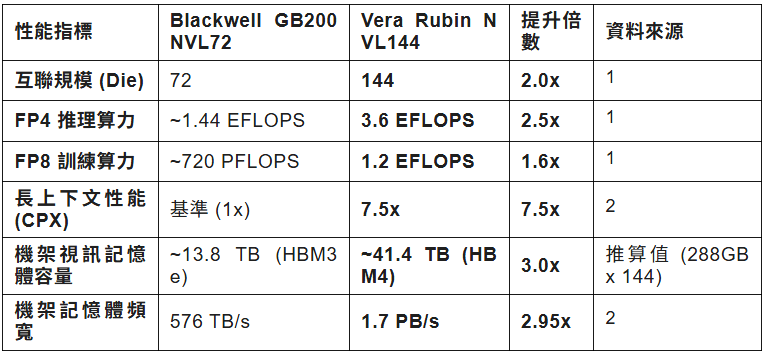
5.1 AI 推理性能(Inference):3.3 倍的躍升
在 FP4(4-bit 浮點)精度下,Vera Rubin NVL144 的理論峰值性能達到 3.6 Exaflops(每秒 360 億億次運算)1。
- 對比基準:Blackwell NVL72 的 FP4 性能約為 1.44 Exaflops。
- 提升幅度:約 2.5 倍至 3.3 倍1。
- 技術歸因:這一提升不僅源於 GPU 數量的翻倍(從 72 到 144),更源於 Rubin 架構 Tensor Core 的效率提升以及 HBM4 提供的 13 TB/s 頻寬,使得計算單元能夠滿負荷運轉,避免了“記憶體牆”導致的閒置。
5.2 複雜推理與長上下文(CPX):7.5 倍的質變
對於生成式 AI 的未來——即涉及數百萬 Token 上下文、視訊生成或複雜程式碼分析的任務——Rubin CPX 展現了驚人的統治力。
- 性能資料:輝達宣稱 Rubin CPX 系統在“海量上下文推理”任務中比 GB200 NVL72 強 7.5 倍2。
- 技術歸因:這 7.5 倍的差異遠超算力本身的提升,主要歸功於 CPX 針對 Attention 算子的硬體最佳化和 NVLink 6 的極低延遲。在長文字推理中,資料在 GPU 間的搬運是最大瓶頸,Rubin 的超高頻寬讓跨 GPU 的 KV-Cache 訪問如同訪問本地視訊記憶體一樣快。
5.3 訓練性能(FP8):穩健增長
在傳統的模型訓練(FP8 精度)方面,Rubin 的提升相對溫和但依然顯著。
- 性能資料:NVL144 提供 1.2 Exaflops 的 FP8 算力 1。
- 對比基準:Blackwell NVL72 約為 720 Petaflops。
- 提升幅度:約 1.6 倍。
- 解讀:訓練任務對計算密度的依賴高於記憶體頻寬,因此提升幅度更接近於電晶體規模的線性增長。但考慮到 Rubin 支援更大的單節點模型,其實際訓練效率(收斂速度)可能高於理論算力的提升。
5.4 性能資料彙總表
以下表格總結了 Rubin NVL144 與 Blackwell NVL72 的關鍵性能對比:
6. 熱力學與基礎設施:600kW 的工程挑戰
Rubin 架構的性能飛躍並非沒有代價。為了在單一機架內壓縮 144 個高性能 GPU 和 36 個 CPU,其對資料中心的基礎設施提出了極其嚴苛的要求。
6.1 功率密度的爆炸:邁向 600kW
雖然標準的 NVL144 機架功耗預計在 120kW - 140kW 左右(與 NVL72 相似),但 Rubin 架構的終極形態——Rubin Ultra NVL576——預計將單機架功耗推向 600kW 的恐怖量級 10。
- 對比:傳統企業級機架功耗僅為 10kW 左右;即使是當前的高密度 AI 機架通常也在 40-50kW。Rubin Ultra 的 600kW 相當於將一個小區的用電量壓縮到了一個衣櫃大小的空間內。
6.2 800V 高壓直流供電(HVDC)
為了應對如此巨大的電流,傳統的 48V 配電架構已徹底失效(電流過大會導致銅排熔化)。Rubin 平台推動了 800V 直流配電 標準的落地 17。
- 原理:根據 $P=UI$,在功率 $P$ 極大的情況下,提高電壓 $U$ 是降低電流 $I$ 的唯一途徑。800V 架構允許使用更細的母線(Busbar),減少傳輸損耗,並提高電源轉換效率。
6.3 液冷成為唯一選項
對於 Rubin NVL144,風冷已在物理上不可行。該系統採用了 100% 全液冷設計14。
- Kyber 機架:輝達為 Rubin 重新設計了名為“Kyber”的機架架構(接替 Blackwell 的 Oberon 機架)。Kyber 專為高密度液冷最佳化,冷卻液直接流經 GPU、CPU 和 NVSwitch 晶片表面的冷板(Cold Plate),並通過機架內的 CDU(冷卻分配單元)進行熱交換。這意味著部署 Rubin 的資料中心必須具備完善的液體回路基礎設施。
7. 軟體生態與經濟學模型
硬體的堆砌只是基礎,Rubin 的真正威力在於其軟體棧和經濟效益。
7.1 CUDA 與 NIM 的進化
為了駕馭 144 晶片的互聯域,輝達的 CUDA 軟體棧將進一步演進。Rubin 將深度整合 NVIDIA NIM (NVIDIA Inference Microservices),這是一套預最佳化的微服務容器,能夠自動識別底層的 NVL144 拓撲,並將模型層(Layer)智能切分到不同的 GPU Die 上,以確保儲存和計算的負載平衡 4。
7.2 代幣經濟學(Tokenomics)
雖然 Rubin NVL144 機架的單價將極其昂貴(預計數百萬美元),但其 TCO(總體擁有成本) 在大規模推理場景下可能反而更優。
- 推理成本降低:由於 Rubin CPX 在長上下文任務上擁有 7.5 倍的性能優勢,這意味著單位 Token 的生成能耗和時間成本大幅下降。對於像 OpenAI、Anthropic 這樣每天處理數十億 Token 的服務商而言,Rubin 是降低營運成本的必要工具。
8. 結論與展望
輝達的 Rubin 架構不僅僅是一次產品的迭代,它是對“摩爾定律已死”這一論斷的有力回擊。通過將 144 個 3nm GPU 封裝在一個通過 NVLink 6 互聯的單一機架中,輝達成功地將計算的邊界從微米級的晶片擴展到了米級的機架。
回答使用者的核心疑問:
- 互聯規模:Rubin 實現了 144 張 GPU(裸片) 的全互聯,建構了當前世界上密度最大的單一記憶體計算域。
- 性能對比:相比當前最強的 Blackwell NVL72,Rubin 在 AI 推理上強 3.3 倍,在處理長上下文任務時強 7.5 倍,在記憶體頻寬上強 3 倍。
Rubin 的出現標誌著 AI 基礎設施正式進入了“巨型機”時代。在這個時代,資料中心的衡量單位不再是伺服器的數量,而是機架(NVL144)的數量。對於追求極致算力的科研機構和科技巨頭而言,Rubin 不僅是下一代工具,更是通往通用人工智慧(AGI)的物理基石。 (成癮大腦神經重塑)