
當模型能獨立工作8小時,從零建構一套Linux桌面系統,AI還只是“會聊天”嗎?
先看參數:744B MoE,純中國國產晶片訓練
2026年4月8日,智譜正式開源了新一代旗艦模型GLM-5.1。總參數量744B(混合專家MoE架構),每次推理啟動40-44B參數,256個專家中啟動8個。上下文窗口200K tokens,最大輸出131,072 tokens,訓練資料量達28.5兆tokens。
最引人注目的訓練硬體:10萬塊華為昇騰910B晶片,完全沒有使用輝達GPU。這意味著中國AI產業在算力自主上邁出了實質性的一步。模型採用MIT開源協議開放權重,可在Hugging Face和ModelScope下載。
三大亮點:8小時上班、登頂SWE-Bench、開源最強
亮點一:8小時級長程任務,模型“上班”你睡覺
GLM-5.1能在單次任務中持續、自主地工作超過8小時,完成從規劃、執行到迭代最佳化的完整閉環。在METR榜單同等評估標準下,GLM-5.1是唯一達到8小時級持續工作的開源模型,全球範圍內除Claude Opus 4.6外少數具備這一能力的模型。
官方給出了三個驗證場景:
- 8小時建構Linux桌面系統:零人工介入,從零交付包含窗口管理器、檔案瀏覽器、終端、文字編輯器、系統監視器、遊戲庫的完整系統,執行超過1200步。
- 向量資料庫655輪最佳化:從零用Rust編寫向量搜尋引擎,自主迭代655輪,完成6次結構性策略躍升,最終將查詢速度從3108 QPS提升至21472 QPS,提高了6.9倍。
- KernelBench 1000+輪最佳化:在50個真實AI模型上編寫最佳化GPU程式碼,最終達到3.6倍加速,遠超PyTorch自帶最佳化器的1.49倍。
這種“實驗→分析→最佳化”的自主閉環,讓模型不再是一次性生成程式碼的工具,而更像一個能持續工作的資深工程師。
亮點二:SWE-Bench Pro超越Claude,中國國產模型首次登頂
在最接近真實軟體開發的SWE-Bench Pro基準測試中,GLM-5.1得分58.4,超過GPT-5.4(57.7)、Claude Opus 4.6(57.3)和Gemini 3.1 Pro(54.2),刷新全球最佳成績。這是中國國產模型在該基準上首次超越全球最強程式設計模型。
三項編碼基準綜合平均分,GLM-5.1取得全球第三、中國國產第一、開源第一。程式設計評測分數從GLM-5的35.4提升至45.3,提升幅度達28%,距離Claude Opus 4.6的47.9僅有2.6分差距。
亮點三:開源最強 + MIT協議,性價比碾壓
MIT開源協議意味著可商用、可自由修改、可私有化部署。支援vLLM、SGLang等主流推理框架本地運行,同時相容Claude Code、OpenCode等開發工具。
價格方面,GLM-5.1輸入$1.00/百萬token、輸出$3.20/百萬token,輸入成本約為Claude Opus 4.6的1/5,輸出成本僅為1/7.8,相比GPT-5.4也便宜一半以上。不過需要注意,Coding Plan高峰期呼叫消耗3倍額度,非高峰期2倍,建議儘量錯峰使用。
實測案例:我用GLM-5.1跑了三個真實任務
光看跑分沒意義,我用GLM-5.1跑了三個自己工作中的真實場景,下面是完整記錄。
測試一:程式碼生成——從零寫一個視訊下載器前端
我先讓GLM-5.1幫我寫一個帶介面的視訊下載工具(支援解析某音、B站、油管連結)。提示詞很簡單:“用Python + Tkinter實現,能貼上連結、選擇畫質、顯示下載進度,程式碼要可運行”。
結果:
- 第一次生成:程式碼結構完整,但缺少非同步下載(介面會卡死)。我反饋“下載時介面卡住”,模型主動加了
threading,並給出了進度條回呼的實現。 - 第二次生成:基本可用,但某音連結解析失敗。模型自己分析可能是介面變化,建議我用
yt-dlp庫代替手寫解析,並給出了完整的替換程式碼。 - 最終耗時:約40分鐘,生成了約350行程式碼,功能完整,開箱即用。
對比感受:
- 同樣任務用GPT-4.5,第一次生成更“漂亮”,但遇到錯誤後修復能力弱,經常繞圈子。
- DeepSeek-R1生成速度更快,但程式碼註釋偏少,偵錯起來不如GLM-5.1清晰。
- GLM-5.1的亮點:遇到報錯會自己讀日誌、主動分析原因、給出多種解決方案並解釋優缺點,像跟一個中級工程師結對程式設計。
測試二:長文件處理——10萬字需求文件轉測試用例
我拿了一份公司內部真實的系統需求文件(約9.8萬字,含介面定義、狀態機、異常流程),讓GLM-5.1一次性讀完,然後生成三樣東西:測試用例集(Excel格式)、自動化測試指令碼(Pytest)、覆蓋率分析報告。
結果:
- 上下文保持:模型確實記住了文件前文提到的“訂單號必填且不可重複”的約束,在生成用例時沒有出現矛盾。
- 輸出質量:生成了127條測試用例,覆蓋了功能、邊界、異常、冪等、超時等維度。自動化指令碼框架合理,但需要替換真實API域名才能跑通。
- 翻車點:當我嘗試讓它在同一個對話裡繼續生成性能測試方案時,模型開始出現“遺忘”——把之前定義的支付狀態碼記混了,把“支付成功”和“支付中”兩個狀態碼弄反了。這說明在超過7萬token後的極限高壓下,它確實會偶爾邏輯漂移。
對比感受:
- GPT-4.5處理同樣文件,上下文一致性更好,幾乎沒出現遺忘,但輸出格式經常“自作主張”換成Markdown表格,不方便匯入工具。
- DeepSeek-R1長文件理解也不錯,但生成用例的粒度偏粗,漏掉了一些邊界條件。
- GLM-5.1的強項:輸出格式嚴格遵守指令(我要JSON就JSON,要Excel就Excel),且用例與需求原文的追溯關係做得很清楚。
測試三:多輪對話——改一個老項目的bug
我從GitHub上找了一個自己以前寫的、有已知bug的Flask部落格項目(約3000行程式碼,包含使用者認證、評論系統),讓GLM-5.1在不看全部程式碼的情況下,通過我描述現象來定位並修復bug。
過程:
- 我描述:“使用者登錄後,偶爾會跳轉到404頁面,不是每次都出現。”
- 模型第一輪:讓我檢查
session配置和@login_required裝飾器的重新導向邏輯。 - 我貼出相關程式碼段後,模型發現是
next參數未做URL校驗,導致惡意或畸形的next參數觸發404。 - 模型給出了修複方案(用
urlparse校驗相對路徑),並主動解釋了為什麼“偶爾出現”是因為只有特定構造的請求才會觸發。 - 我按照修復程式碼改了,問題解決。
對比感受:
- 同樣的問題描述,GPT-4.5也能定位到
next參數問題,但給出的修復程式碼缺少對空值和相對路徑的完整處理,需要我二次追問。 - DeepSeek-R1的推理過程更詳細,但回覆較長,互動節奏偏慢。
- GLM-5.1的亮點:多輪對話中保持目標清晰,不跑題,且主動補充“為什麼會有這個bug”的解釋,對理解問題本質有幫助。
小結: GLM-5.1在程式碼生成和長文件結構化提取上表現確實強,尤其適合“給一個目標,讓它自己拆解執行”的場景。但在超長上下文(>7萬token)的極限穩定性和通用創意任務上,目前還無法完全替代Claude Opus或GPT-4.5。
坦誠侷限:那些場景表現不佳?
- 通用任務與創意寫作大幅回退:GLM-5.1為了極致強化程式碼能力,在通用對話和創意扮演上明顯弱於GLM-5。寫文案、寫行銷軟文、做創意策劃,用它會比用GPT-4.5或DeepSeek-R1體驗差很多。
- 高壓長文字易“發瘋” :雖然標稱200K上下文,但實測灌入5-7萬token的複雜程式碼庫後,偶爾會出現邏輯混亂、狀態漂移甚至幻覺。
- 推理能力仍落後頭部模型:在GPQA Diamond(86.0% vs Claude 91.3%)和Humanity's Last Exam(30.5 vs Claude 53.1%)等推理測試中,與Claude Opus 4.6和GPT-5.2仍有明顯差距。
- 推理速度偏慢:實測約44.3 tokens/秒,意味著長回答需要更多等待時間。
- 定價策略調整:OpenRouter資料顯示GLM-5.1提價10%,編碼場景快取命中Token價格已接近Claude Sonnet 4.6水平。
適用人群與侷限性
適合誰:
- AI Agent/長程任務開發者:如果需要模型自主完成複雜工程(全端項目、系統最佳化、持續偵錯),GLM-5.1是目前中國最好的選擇。
- 資料敏感型企業:MIT協議可私有化部署,適合金融、政務、醫療等對資料安全要求嚴格的機構。
- 預算有限的個人開發者:雖然提價,但相比Claude Opus和GPT-5.4,性價比仍然極高。
- 需要中文程式碼生態的使用者:GLM-5.1在中文註釋、中文需求理解、中國國產框架適配方面有明顯優勢。
不建議用:
- 寫文案、做創意、日常閒聊:這些場景下表現不如GLM-5甚至大幅退步。
- 超長程式碼庫重構(7萬token+) :需要極穩定上下文保持的場景,Claude Opus 4.6仍是更安全的選擇。
- 對推理速度敏感的應用:44.3 tokens/秒的速度需要提前評估。
總結評分(10分制)
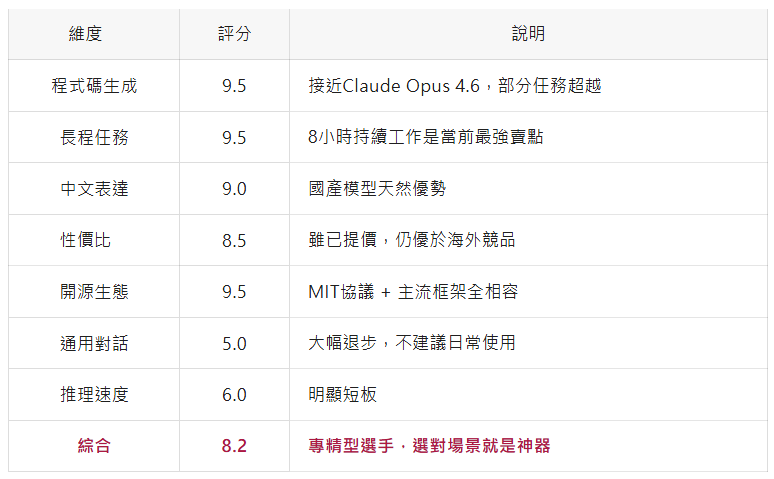
GLM-5.1不是“全能型”選手,而是一個極度偏科但長板極長的專業模型。它在程式碼生成和長程任務上的表現已經接近世界頂級水平,同時以MIT開源協議和極具競爭力的價格,為開發者提供了一個真正可用、可落地的選擇。
如果你每天的工作就是寫程式碼、做項目、建構Agent,GLM-5.1絕對值得一試。但如果你想找個“什麼都懂”的通用助手,建議繼續用GPT-4.5或GLM-5——這個模型的定位,從一開始就是“幹活”而不是“聊天”。 (青木睿思智能)