
HBM:從配角到AI時代的命門
當token成為貨幣單位,決定GPU上限的不再是算力,而是記憶體。一條被物理定律鎖死的指數增長曲線,正在重寫整個半導體產業的價值分配。
一、一個讓市場爭吵了三年的問題
HBM多空之爭從未停過。樂觀派說AI帶來的需求跟以前完全不一樣;悲觀派反駁,過去幾次儲存上行周期需求也是20%+增長,最後都沒逃過擴產過剩的宿命,這次憑什麼不同?
這個問題不能靠情緒解決,只能從晶片架構的底層邏輯推導。先從CPU說起。
在CPU主導算力的時代,評價一顆處理器好不好的標準很簡單:跑分。頻率越高越好,後來加入超標量、大快取、分支預測……所有努力都指向同一件事:讓CPU跑得更快。
這個邏輯下,DDR記憶體是個可有可無的配角。業界有個經驗資料:那怕把記憶體頻寬翻一倍,CPU性能的提升通常也不到20%。原因是CPU設計了大量機制來"藏住"記憶體延遲——L1/L2多級快取、亂序執行、暫存器重新命名……DDR只需要在CPU真正撐不住的時候出來幫個忙。
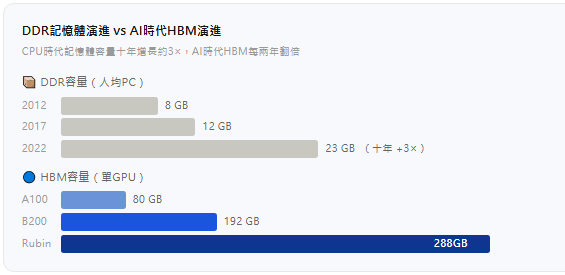
所以DDR3到DDR5整整走了15年,平均每台電腦的記憶體容量從7~8GB爬到23GB,十年只漲了3倍。這麼慢,因為沒人著急。
二、KPI變了,一切都變了
AI推理時代,GPU最重要的指標不再是算力FLOPS,而變成了:單位成本/單位電力,能輸出多少token。
這一個KPI的切換,把整個產業的價值鏈重排了一遍。
Jensen Huang為什麼要造"AI工廠"這個概念?因為AI推理的毛利率相當可觀,邏輯從"買越多GPU省越多"變成了"買越多GPU賺越多"。Nvidia的銷售主張變了:我的GPU是這個世界上讓token最便宜的機器,你買得越多,你就賺得越多。
- Token吞吐量:單位時間/電力產出更多token,降低每個token的成本
- Token速度:Agent時代任務序列,速度直接影響使用者體驗
- Token單價:B200實測約$0.02/百萬token,是H100的4.5倍性價比
三、推匯出這個時代的第一性原理
把token吞吐量拆開來看,它由兩個參數的乘積決定:
Token吞吐量 = 批處理量(Batch Size) × 單使用者Token速度
前者瓶頸在HBM容量,後者瓶頸在HBM頻寬
第一個參數:批處理量,卡在HBM容量上
AI推理不是一個一個請求排隊處理的。要讓GPU跑滿、降低成本,必須同時批次處理儘可能多的請求。
問題是:每一個請求都會帶著自己的KV Cache(對話"工作記憶"),這部分資料隨時需要被GPU高速讀取,必須存在HBM裡。一個大模型比如80層,每生成一個token就要讀80次KV Cache。
批次處理的請求越多,KV Cache加起來就越大,佔用的HBM也越多。HBM裝不下,只能減少同時處理的請求數,吞吐量就上不去。
第二個參數:單使用者Token速度,卡在HBM頻寬上
大模型"decode階段"(逐token生成輸出)是記憶體頻寬密集型操作。每生成一個token,都要把啟動的權重和KV Cache從HBM裡讀很多遍。HBM頻寬越高,token生成速度越快,基本是線性對應關係。
🚌 機場接駁車類比
▎車廂容量 = HBM Size:決定同時能裝多少個請求的KV Cache(即Batch Size上限)。車廂小了,100個旅客得分兩趟送,整體效率直接打折。
▎車門寬度 = HBM頻寬:決定每個token的生成速度(旅客上車速度)。門窄了,那怕車廂再大,大家擠成一隊,等待時間成了主要矛盾。
▎旅客吞吐量 = Token吞吐量:HBM Size × HBM頻寬
Token throughput = HBM Size × HBM Bandwidth
歷史上第一次,記憶體容量直接決定了AI系統最高KPI的天花板
四、資料說話:四代GPU的完美印證
理論需要資料驗證。把Nvidia從A100到Rubin的幾代GPU,HBM Size × HBM頻寬的乘積,和實際token推理性能放在一起比較:
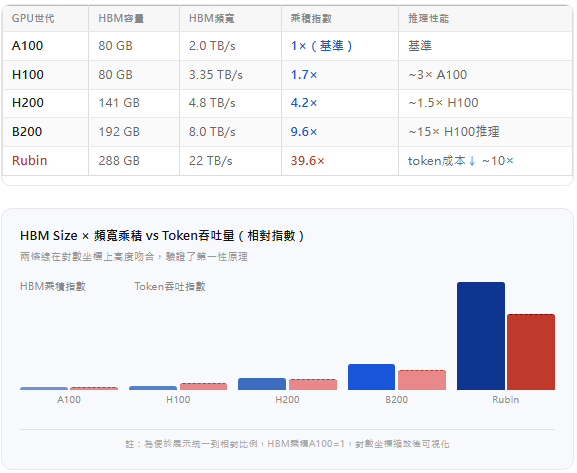
H200相比H100,算力幾乎沒變,但HBM容量翻了近一倍(80GB→141GB),Size×BW乘積提升2.5×——這解釋了為什麼H200的推理性能提升主要來自容量,不是算力。這是記憶體天花板決定GPU性能的最直接案例。
五、供給側三家的市場份額戰爭
需求被架構鎖定,供給側只有三個玩家:SK海力士、三星、美光。
三個關鍵資料點可以說明這一輪周期的結構性:
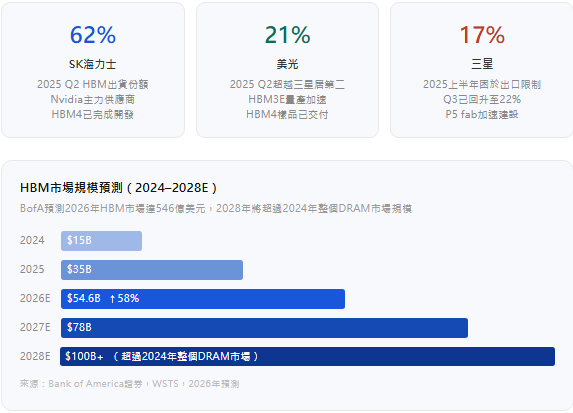
第一,SK海力士已宣佈2026年HBM產能全部售罄,年化營收預期約80億美元。這不是預測,是已簽訂的合同。
第二,2025年全年HBM價格上漲了246%,而且還在漲。TrendForce預測2025年Q4整體DRAM合同價將再上漲50~55%。
第三,2026年HBM4全面進入量產。SK海力士HBM4宣稱功耗效率提升40%、資料速率10Gbps;美光HBM4樣品速率已突破11Gbps;三星HBM4同步推進,目標2026年拿回30%以上份額。而Rubin GPU單顆配備288GB HBM4,頻寬22 TB/s,是H100的6.6倍。
六、軟體最佳化能解耦這個問題嗎?
經常有人問:軟體層面的最佳化,比如量化、稀疏化、KV Cache壓縮,會不會降低對HBM的需求,讓這條曲線"彎掉"?
這個問題其實問錯了。軟體最佳化和硬體代際進步是兩個獨立維度,不能互相抵消。
類比到CPU行業:假設某一年有了一個軟體突破讓程序跑快了50%,Intel和AMD就可以放棄下一代研發了?顯然不可能——只要有競爭,每一代CPU的benchmark跑分就必須更高,否則賣不出去。GPU是同樣的邏輯。
只要token需求還在增長,對token吞吐量的追求就不會停;對吞吐量的追求不停,對HBM Size × BW的追求就不會停。
還有一個更重要的機制:這是Nvidia自己的生存壓力。HBM的天花板就是Nvidia GPU的天花板。如果HBM不進步,Nvidia下一代GPU的旗艦KPI就無法提升,就賣不動。所以老黃會親自推HBM三家加速技術迭代——這是供給側的內生驅動,和宏觀需求景氣與否無關。
軟體讓同樣的硬體跑得更高效,但Nvidia每年還是必鬚髮布benchmark更強的新GPU。這兩件事從不衝突,因為它們針對的是不同層面的競爭壓力。
七、結論:需求被物理鎖死,風險在供給側
HBM這一輪和以往儲存周期根本不同的地方,不在於需求有多旺盛,而在於需求是被GPU架構從第一性原理層面物理鎖定的。只要Nvidia還要每一代讓token吞吐量翻倍,HBM Size × HBM頻寬的乘積就必須翻倍。這不是市場預測,是方程式。
核心結論
📌 2026年HBM市場預期規模546億美元(同比+58%),2028年有機構預測突破千億美元等級,超過2024年整個DRAM市場體量。
📌 SK海力士、美光的2026年產能均已售罄,價格仍在上漲。HBM4全面進入量產,Rubin GPU頻寬達22 TB/s,是H100的6.6倍。
📌 需求端是被架構物理鎖定的指數增長。唯一的不確定變數,是供給側三家的資本開支紀律——歷史上每一次儲存周期崩盤,都是被過度擴產搞崩的,不是需求消失了。
需求被物理鎖定為指數增長,是這次最大的不同。供給側的自律,才是決定周期走向的變數。這是悲觀派和樂觀派真正的分歧所在——不是需求,而是三家儲存廠商在上行周期裡能不能管住自己的capex衝動。 (蚪蚪君)