
2026年5月一個普通的星期一,美國程式設計師 Jake 打開 Cursor 準備寫程式碼。他什麼都沒想,只是像往常一樣敲下第一行註釋,等待 AI 補全。
但這一次,他消耗的算力,來自杭州。
Jake 不知道這件事。大多數美國開發者不知道這件事。甚至很多科技記者也不知道。
然而資料不會撒謊。
01 /什麼是Token?理解這一切的起點
Token,是AI處理資訊的最小單位。你向AI提一個問題,這個問題被切碎成一個個Token輸入;AI給你的回答,也以Token為單位生成輸出。計算量越大,消耗的Token越多。
黃仁勳在2026年GTC大會上說了一句話,很多人沒太在意:
"未來的資料中心,是生產Token的工廠。"
Token不是虛資料,它是真實的算力消耗,對應真實的電費、晶片折舊和機房成本。每一個Token背後,都有人在付錢。
現在問題來了:全球使用者每天消耗的海量Token,是誰在生產?答案正在發生根本性改變。
"全球開發者每一次呼叫中國模型,實質上都在購買由中國電力、算力設施和演算法效率共同生產的Token服務。"── 摩根大通AI產業報告,2026年Q1
02 /一個讓矽谷震驚的周榜
2026年2月9日那一周,全球最大AI模型聚合平台OpenRouter發佈了周度資料。
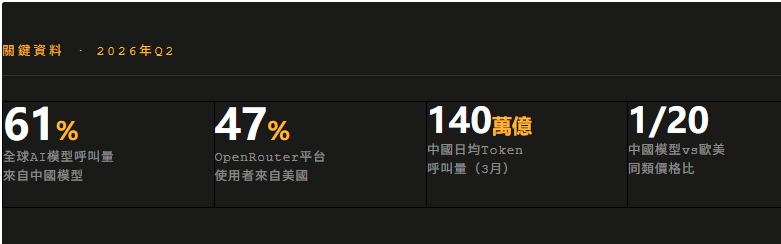
中國模型的Token呼叫量,第一次超過了美國。
接下來的三周,中國模型不僅沒有回落,反而連續上漲。到2月23日那一周,峰值達到5.20兆Token——每秒860億個。
更讓人意外的是呼叫這些Token的人是誰:該平台47%的使用者來自美國,中國開發者只佔6%。也就是說,推動中國模型登頂的,主要是美國人。
03 /誰在用?美國開發者的悄悄話
"即便是在矽谷,大部分人都認為應用和智能體是用Claude或ChatGPT跑的——然而事實上,50%以上的LLM呼叫是通過廉價的開源模型完成的。"── 矽谷投資人 Agrawal,2025年11月
這話背後是一個真實的成本邏輯:一個Agent任務可以消耗數十萬乃至百萬Token。用GPT-4或Claude跑,月帳單能把初創公司的現金流直接打穿。
最具戲劇性的例子是Cursor事件。
一位開發者架了一台伺服器充當中介軟體,讓Cursor發出的請求暴露出真實的模型ID:kimi-k2p5-rl-0317-s515-fast
Cursor用的底座,是中國公司月之暗面的Kimi K2.5。Cursor副總裁後來確認:團隊評估了多個底座,K2.5在程式設計指標上表現最強,同時成本比頂級閉源模型低得多。
Cursor不是孤例。Cognition的Windsurf採用了類似路徑,Manus(被Meta開出20億美元價碼)底層完全依賴中國模型。
04 /核心玩家:誰在賣這些Token
01 MiniMax
MiniMax M2.5 · $0.30/百萬Token
OpenRouter呼叫量全球第一。旗下海外產品Talkie(情感陪伴)覆蓋200+國家,出海收入佔總營收超70%,毛利率已升至25.4%。2026年1月港股上市後市值翻倍,是目前中國AI出海商業化最成熟的公司。
海外營收佔比 >70%
02 月之暗面(Moonshot AI)
Kimi K2.5 · Cursor Composer 2底座
Kimi K2.5比同級Claude Opus便宜七分之一,是程式設計領域殺手級產品。KimiClaw(雲端Agent框架)用20天驗證了此前一年沒走通的變現模型,在海外付費使用者中大爆。估值180億美元。
Cursor底座 · KimiClaw爆款
03 DeepSeek(幻方科技)
DeepSeek V3.2 · $0.14/百萬Token · 全行業價格錨
創始人梁文鋒用量化基金的錢自給自足,84%控股未被稀釋,沒有融資壓力,專注長期研究。DeepSeek R1被Time評為2025年最佳發明。它不需要賺錢,卻逼著整個行業降價。
最低定價 · 全行業價格錨
04 阿里巴巴(Qwen)
Qwen3.5 · Alibaba Token Hub(ATH)事業群
2026年3月,阿里成立ATH事業群,與電商、雲智能並列,CEO吳泳銘直接帶隊。Qwen在HuggingFace下載量超越Meta Llama,成為全球最多人下載的開源模型系列。
HuggingFace下載量全球第一
05 小米(Xiaomi AI)
MiMo-V2-Pro · 單模型份額21.1%
最反直覺的榜首。MiMo-V2-Pro在OpenRouter單模型使用量排全球第一,市場份額21.1%,是OpenAI全部模型加總的3倍。它不是最聰明的模型,但極致性價比讓開發者大量呼叫。
單模型呼叫量 #1
06 智譜AI(Z.ai)
GLM-5 · MIT開源 · 744B參數
270萬API付費使用者,to B訂閱制路線最穩健。GLM-5以MIT協議開源,是目前開源協議最寬鬆的超大模型,面向法律、金融、研究等高價值場景。港股+A股雙線上市。
270萬付費API使用者
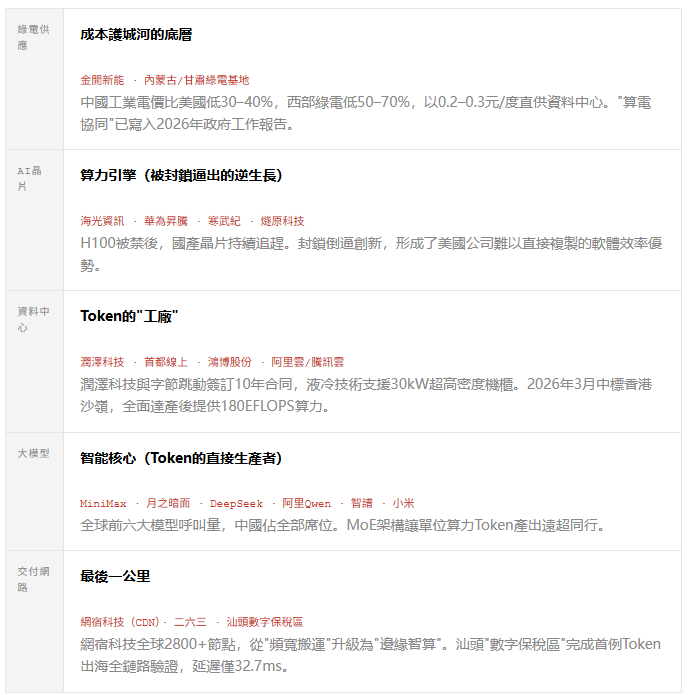
05 /冰山之下:完整產業鏈
使用者呼叫的只是海面上露出的冰山一角。這背後,是一條完整的"Token生產線"。
06 /為什麼這麼便宜?三重護城河
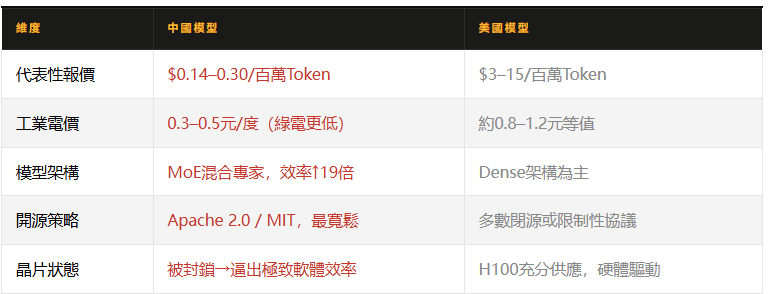
有一個細節值得單獨說:中國模型的價格之所以這麼低,部分原因恰恰是晶片封鎖。用不了最好的硬體,就只能把軟體效率做到極致。這種在約束下磨煉出來的創新,形成了美國公司很難直接複製的競爭力。
07 /一個重要爭議:Token真的"出海"了嗎?
目前中國模型出海的四條路徑:
路徑一:開發者平台直接呼叫
對合規不敏感、對成本極敏感的個人開發者,直接呼叫國內節點API,接受一定延遲。
路徑二:海外雲本地化部署
模型權重部署到海外雲,在當地算力推理,資料不出境。配方是中國的,裝罐在當地。
路徑三:數字保稅區近岸服務
汕頭模式:物理隔離區+國際海纜直連,延遲32.7ms,在成本和合規之間找平衡。
路徑四:開源模型輸出(最深遠)
發佈權重,全球開發者自行下載微調,中國獲得的是生態話語權——這是Android的邏輯。
08 /這件事的真正影響,還沒被充分理解
很多人把這件事理解為"中國AI進步了"或"中國模型便宜"。但這兩個理解都停在表面。
更深層的變化是:這是全球AI供應鏈的底層重構。
過去,一家美國初創公司的AI成本結構是:租OpenAI API → 帳單給OpenAI → 錢在美國內部流轉。
現在越來越多的公司是:Kimi/DeepSeek API → 帳單給中國公司 → 錢流向杭州、北京的模型團隊,流向潤澤科技的機房,流向內蒙古的綠電營運商。
摩根大通預測,中國AI推理Token消耗將從2025年的10千兆,飆升至2030年的3900千兆——五年漲370倍。這意味著這個市場還在最開始的階段。
"Token出海的本質是:電力留在國內,收益流向全球。中國正從世界工廠,走向世界算廠。" ── 預商數字經濟研究院,2026年4月 (The AI Frontier)