
一、那口鐵鍋
大約一千年前,某個中國釀酒師的作坊裡。
一口鐵鍋,滿滿噹噹裝著發酵了十天的酒醅。底下,炭火慢慢燒著。
酒精被加熱,變成蒸汽,順著竹管往上走,遇到冷水,重新凝結成液體,一滴一滴,落入陶罐。
釀酒師彎腰,用手指沾了一點,送到嘴邊。
烈。
比之前濃多了。
他可能沒意識到,他正在重現人類歷史上最精妙的物理提純過程。他不知道"蒸餾"這個詞,但他明白一件事:糧食裡有精華,要把精華取出來,你不能直接擠,不能直接過濾,你要先把它變成氣,再把氣變成液體。
精華,在蒸汽裡。
這個道理沿用了一千年——然後,被一個叫傑佛瑞·辛頓(Geoffrey Hinton)的英國老頭,用到了他絕對沒想到的地方。
二、那個悶聲幹了三十年的人
說到辛頓,先說說他的家譜。
他的高祖父是喬治·布林(George Boole)——今天所有程序裡的 if-else、and/or/not,布林代數,全是他的遺產。你每天用的手機,裡面跑的每一行程式碼,追根溯源都跟這個人有關。
所以有人說:辛頓的 DNA 裡大概真的有點什麼。
1980 年代,AI 界的主流是"專家系統"——把人類知識寫成規則,讓機器執行:"如果患者發燒且白細胞升高,則診斷為感染。"這條路短期有效,吸引了大量資金和人才。
神經網路研究者是邊緣人。
辛頓是邊緣人裡的邊緣人。
他在多倫多大學埋著頭,研究一個沒人覺得有前途的問題:機器能不能從資料裡自己學會規律?不靠規則,不靠人工編碼,靠資料,靠連接,靠迭代。
主流 AI 圈的人覺得他在浪費時間,除了加拿大高等研究院(CIFAR)等極少數機構願意提供關鍵的資金續命,他幾乎是在邊緣地帶孤獨地幹了近三十年。
2012 年,他的學生亞歷克斯·克里熱夫斯基——旁邊還站著一個叫伊利亞·蘇茨克維爾的年輕人,後來 OpenAI 的聯合創始人——用 AlexNet 參加 ImageNet 圖像競賽,把第二名甩開了近 11 個百分點(10.9%)。
AI 圈當天炸鍋。
三十年的孤獨,在一個下午畫上了句號。
三、勝利之後,新的麻煩
但麻煩很快跟上來了。
深度學習爆發後,所有人都在做同一件事:堆參數。
VGG、GoogleNet、ResNet……每一代都比上一代更深更寬,效果也更好。道理簡單粗暴:想要更聰明的 AI,給它更多神經元就行。
然而這些模型,大到沒法用。
2013 年,辛頓加入 Google Brain。Google要把 AI 塞進 Android 手機——語音助手、圖像識別、即時翻譯。但一個動輒幾百 MB 的大模型,手機的晶片和記憶體根本承受不起。
辛頓想到一個問題:這些大模型,真的需要每一個參數嗎?
有人做過實驗:把訓練好的大型網路,隨機刪掉 90% 的參數。
結果……模型性能基本沒變。
等一下。
九成的參數,刪了,沒事。
這說明神經網路裡有大量冗餘。於是有人想:那直接訓練一個小網路代替大網路,行不行?
不行。
同樣的資料,同樣的方法,小網路就是學不到大網路那些精妙的特徵。你想省材料直接建小樓,樓歪了。那些冗餘,恰恰幫助了訓練——更多參數意味著更多梯度通路,更容易找到好的解。
那正確的路是什麼?
辛頓想到了那口鐵鍋,想到了那縷蒸汽。
四、答案藏在"錯誤"裡
2015 年,辛頓和Google工程神傑夫·迪恩(Jeff Dean)等人發了一篇論文——
Distilling the Knowledge in a Neural Network
知識蒸餾(Knowledge Distillation),正式登場。
核心思想,一句話:讓小模型不只學正確答案,而是學大模型對答案的完整"理解"。
聽起來抽象,我翻譯一下。
給大模型看一個手寫數字"2",它的輸出是這樣的:
數字 2:機率 96.2%
數字 3:機率 2.1%
數字 8:機率 1.4%
其他數字:合計 0.3%傳統訓練叫硬標籤:答案是 2,對;不是 2,錯。非黑即白。這就像一個只會打勾打叉、從不解釋為什麼的老師改卷子。
但辛頓盯著那個輸出,看到了別的東西——數字 3 有 2.1% 的機率,數字 8 有 1.4%。
這不是噪聲。這是知識。
這說明大模型認為:這個"2"的某些筆畫特徵,和"3"有點像;某些彎曲的方式,和"8"有點關聯。這是它看過數百萬張手寫數字之後,內化的對數字結構的深層理解——2 和 3 同族,和 8 也有淵源,和 7 基本沒關係。
這些藏在機率分佈裡的細微關聯,辛頓給它起了一個極好聽的名字:
暗知識(Dark Knowledge)。
物理學裡有暗物質——無法直接觀測,卻真實存在,影響著宇宙的結構。暗知識也是這樣:它不出現在最終答案裡,卻藏在那些微小的機率數值裡,代表著模型真正理解這個世界的方式。
用這些豐富的機率分佈來訓練小模型,而不是只告訴它"答案是 2",小模型就能學到大模型對數字結構的深層理解,而不只是記住幾個正確答案。
這就是蒸餾的本質:傳遞理解,而不只是傳遞結論。
就像那口鐵鍋——你蒸餾的,不是酒醅本身,而是酒醅裡那縷昇華的精華。
五、溫度:把藏著的東西逼出來
但還有一個技術問題:大模型輸出的機率,通常極度集中。
"數字 2 的機率 96.2%,其他幾乎為 0"——這和硬標籤幾乎沒區別,那 2.1% 的暗知識幾乎看不見,淹沒在小數點後面。
怎麼把暗知識逼出來?
辛頓的解法叫溫度(Temperature)。
想想那口蒸餾鐵鍋。火候不夠,酒精蒸發太慢,雜質也多;火候太猛,水分全蒸發,精華也跑了。恰到好處的溫度,才能讓酒精那縷蒸汽,穩穩地順管升上去。
溫度參數的作用類似:把機率分佈"加熱",讓原本壓縮在一個類別裡的確定性慢慢擴散到其他類別,那些被遮蔽的暗知識就浮出了水面。
訓練時溫度升高,暗知識清晰;推理時溫度恢復正常,給出明確答案。
學習時需要模糊,判斷時需要清晰。
這個邏輯,其實挺像人的。
論文發出去,一開始反響平平——很多人覺得"不就是軟化一下輸出嘛,有什麼大不了的"。但隨著時間推移,引用次數慢慢攀升,最終突破 2 萬次。每一次引用,都是一個研究者在說:這個洞察,改變了我的工作。
2018 年,辛頓獲得圖靈獎,電腦科學的諾貝爾獎。
那個在黑暗裡挖了三十年的人,終於看到了泉水湧出。
六、2023 年:600 美元的革命
辛頓的蒸餾論文誕生於 2015 年。那時候深度學習主要處理圖像分類這類"選擇題",蒸餾用起來順手。
然後,語言模型來了。
2022 年 11 月,ChatGPT 橫空出世。普通人第一次覺得 AI 真的懂了自己的意思——能聊天、寫程式碼、分析合同、安慰失眠的人。
但這個東西,帶不回家。
GPT-4 的參資料傳超過兆,推理一次需要幾十張專業顯示卡同時工作,每次對話成本以美分計。部署到自己的伺服器上——那是大公司的遊戲。
於是一個樸素的念頭,在很多人腦海裡冒出來:
有沒有可能,讓一個小模型,學會 ChatGPT 的本事?
2023 年 3 月,史丹佛大學。幾個研究生坐在一起,做了一個頗為大膽的決定——用 ChatGPT 生成訓練資料,然後拿這些資料,微調 Meta 剛開放原始碼的 LLaMA-7B。
流程不複雜:先手工寫 175 條不同類型的指令,喂給 GPT-3.5,讓它基於這些例子自動生成更多的同類指令和對應回答。就這樣滾雪球,生成了 52000 條"指令-回答"資料。然後用這些資料微調 LLaMA。
整個計畫的預算:600 美元。
他們把訓練好的模型取名Alpaca(羊駝)。發佈當天,人們湧入試用,然後——
驚呆了。
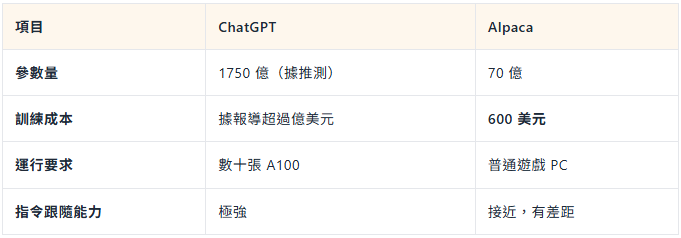
這件事證明了一件重要的事:
大模型的"行為能力",可以通過資料傳遞給小模型。
不需要復刻大模型的每一個參數,只需要讓大模型"表演"足夠多次,然後讓小模型照著學——這是一種新的蒸餾,不蒸機率分佈,蒸行為。
Alpaca 之後,開源社區沸騰了。Vicuna 來了,WizardLM 來了,微軟研究院的 Orca 來了……一串名字,代表了 2023 年最精彩的一段 AI 賽跑。
但這些模型有一個共同的天花板:
它們學會了怎麼聽起來聰明,但沒有真正學會怎麼想。
遇到真正需要推理的問題,很快就原形畢露。
這個天花板,兩年後被徹底打破了。
七、深水炸彈
2025 年 1 月 20 日,周一。
DeepSeek——杭州一家 2023 年成立的 AI 公司,背後是量化基金幻方科技——在 GitHub 上發佈了 R1 模型的技術報告,同時開放了一系列蒸餾版本的模型權重。
矽谷的研究者們陸續醒來,打開報告,沉默了相當長的時間。
一個320 億參數(32B)的蒸餾版本,在數學競賽測試 AIME 2024 上,得分 72.6%,超過了 OpenAI o1-mini 的 70.0%——而 o1-mini 的參數量,估計是它的數十倍。
數字是真實的,不是筆誤。
但比數字更讓人震撼的,是 DeepSeek 告訴了所有人:他們是怎麼做到的。
秘密並不神秘:蒸餾的不是答案,而是推理過程本身。
DeepSeek-R1 全量版是一個 671B 的巨型模型,通過強化學習訓練出了極強的推理能力。它解一道數學題時,會先在"思考區域"裡寫出完整過程——嘗試因式分解,展開驗證,代入檢驗,發現算錯了,重頭再來——像一個認真的學生打草稿,把所有中間步驟都寫出來,才給出最終答案。
然後,DeepSeek 把 R1 生成的這些帶完整推理過程的資料,用來訓練 7B 的小模型。
小模型學到的,不是"這道題答案是 x=2 或 x=3",而是"遇到二次方程,先試因式分解,展開驗證,最後代入檢驗"——一套推理範本,思維方式本身。
這就是為什麼效果截然不同:
Alpaca 的學生,背了很多優秀作文,能模仿語氣,但不會真正寫作。
DeepSeek 蒸餾出來的學生,跟著老師做了大量解題,真正學會瞭解題。
這是蒸餾技術的一次質的飛躍:從傳遞知識,到傳遞能力。從讓小模型知道答案,到讓小模型學會思考。
八、三扇門
退一步,看清這場十年演變的全貌。
2015 年,辛頓的論文。知識可以蒸餾,答案裡有暗知識,用軟標籤傳遞大模型的深層理解。
這是奠基。一個大腦對世界的理解,可以流進一個更小的大腦。
2023 年,Alpaca。大模型的行為可以用資料傳遞,開源社區可以用 600 美元蒸餾出有用的小模型。
這是民主化。AI 的能力開始流出大公司的邊界,流向普通人的手裡。
2025 年,DeepSeek-R1。推理能力本身可以被蒸餾,小模型能獲得真正的思維能力,而不只是表面的流暢。
這是突破。我們第一次看到,一個真正會推理的小模型,從一個更大的大腦裡被蒸餾出來。
三次進步,三扇門。
但為什麼這件事重要?重要的不只是"小模型變強了",重要的是:
AI 的能力,不再只屬於少數擁有巨型算力的機構。
OpenAI 訓練 GPT-4,據說超過一億美元。通過蒸餾,一個初創公司、一所大學、一個有好奇心的工程師,可以在有限資源下,訓練出在特定任務上接近 GPT-4 水平的專用模型。
這個邏輯,有點像當年的 Android——智慧型手機不再只是蘋果一家的專屬,製造門檻被拉低,能力被廣泛分發。
蒸餾,是 AI 世界的 Android 時刻。
當然,隱憂也是真實的。蒸餾有天花板——小模型最多和老師一樣強,不能超越。蒸餾有倫理爭議——OpenAI 的服務條款明確禁止用 API 輸出訓練競爭產品,整個開源社區都在這條線上跳舞。這些問題,沒有簡單的答案。
但有一點是確定的:這扇門,已經打開了。
尾聲:那縷蒸汽
我們繞了一圈,回到開頭那口鐵鍋。
一千年前的釀酒師不知道"蒸餾"這個詞,但他明白精華在蒸汽裡。後來,煉金術士繼承了這個思路,阿拉伯學者把它系統化,歐洲化學家把它提煉成科學,香水師用它萃取玫瑰的靈魂,醫藥師用它提純有效成分……
蒸餾這件事,在人類歷史裡出現了無數次,每次介質不同,但道理相同:
複雜裡有精華。提取精華,讓精華流動,讓更多人用上精華——這是人類對知識傳遞最本能的衝動。
從糧食裡提酒,從教師的大腦裡提知識,從兆參數的模型裡提推理能力——形式變了,本質沒變。
辛頓當年在多倫多堅持的那個信念——智能可以從資料裡學出來——現在有了一個新的推論:
智能,也可以從大腦傳遞到小腦。
那縷蒸汽,升起來了。
它會凝結成什麼,落在那裡,我們還不知道。
但它已經在路上了。 (AI Native啟示錄)