

輝達的下一代Blackwell 架構可以發揮相當大的作用。
根據輝達( Nvidia )的路線圖,它將推出其下一代black well架構很快。該公司總是先推出一個新的架構與資料中心產品,然後在幾個月後公佈削減的GeForce版本,所以這也是這次的預期。作為Nvidia即將推出其新的資料中心GPU的證據,一位戴爾高層已經分享了一些關於下一代Nvidia硬
體的有趣信息,在最近的一次收入電話會議上說,該公司有一個1000W的資料中心GPU在計劃中。
戴爾營運長傑夫克拉克(Jeff Clarke)在2 月29 日的財報電話會議上討論了戴爾的工程優勢,以及Nvidia 即將推出的硬體可提供哪些優勢。
他說:「我們對B100 和GB200這兩款產品感到興奮,下圖是Nvidia 下一代資料中心GPU 及其後繼產品的晶片名稱。Nvidia 目前將H100作為其旗艦資料中心GPU,並且剛剛推出了具有更快HBM3e 記憶體的第二代產品,稱為H200。」我們都知道B100 是該晶片的Blackwell 後繼產品,因此GB200 似乎將是該GPU 的第二次迭代,儘管它目前沒有出現在Nvidia 的路線圖上(如下)。
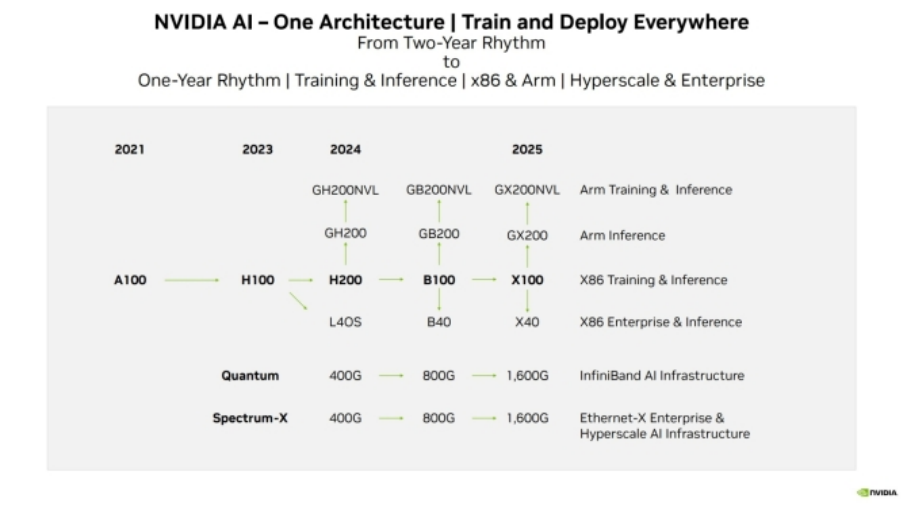
然後,Clark 開始討論這些下一代部件的熱性能,並表示:“您實際上並不需要直接液體冷卻即可達到每個GPU 1,000W 的能量密度。明年的一些產品就會實現這一點,”
目前的GH200 Grace Hopper CPU+GPU 的TDP 已經達到450W 到1,000W,具體取決於配置,因此看到下一代版本的該數字保持不變會有點令人驚訝。同時,現有的H100是700W GPU,但我們不知道它的後繼者B100對功耗有何要求。Nvidia 似乎可以將其功率提高到1,000W,但我們還沒有聽到有關B100 功耗的任何消息。
目前,我們必須等到3 月18 日才能看到Nvidia 為Blackwell 資料中心準備了什麼,而身為遊戲玩家,我們或許也能從該公告中收集到一些細節。鑑於該公司在人工智慧市場的地位有多高,全世界都將專注於今年的GTC,看看Nvidia 有何高招。儘管距離發布已經很近了,但我們對Blackwell 的了解仍然不多,只知道它將使用台積電的3nm 工藝,並且Nvidia 可能會首次採用小晶片設計。輝達也透露,短期內這些晶片的需求將超過供應。
輝達也揭露了X100 晶片的計劃,計劃於2025 年發布,該晶片將擴大產品範圍,包括企業用途的X40 和GX200,在Superchip 配置中結合CPU 和GPU 功能。同樣,GB200預計將效仿B100,融入超級晶片概念。
從輝達的產品路線來看,在未來1-2 年,AI 晶片市場將再次天翻地覆。
值得注意的是,在輝達佔據絕對地位的AI晶片領域中,AMD是少數具備可訓練和部署AI的高階GPU公司之一,業界將其定位為生成式AI和大規模AI系統的可靠替代者。AMD與輝達展開競爭的策略之一,就包括強大的MI300系列加速晶片。目前,AMD 正透過更強大的GPU、以及創新的CPU+GPU平台直接挑戰輝達H100的主導地位。
AMD最新發布的MI300目前包括兩大系列,MI300X系列是一款大型GPU,擁有領先的生成式AI所需的內存頻寬、大語言模型所需的訓練和推理性能;MI300A系列集成CPU+GPU,基於最新的CDNA 3架構和Zen 4 CPU,可以為HPC和AI工作負載提供突破性能。毫無疑問,MI300不僅是新一代AI加速晶片,也是AMD對下一代高效能運算的願景。
除此之外,輝達還要面臨自研AI晶片選手的競爭。
今年2月,科技巨頭Meta Platforms對外證實,該公司計劃今年在其資料中心部署最新的自研定制晶片,並將與其他GPU晶片協調工作,旨在支持其AI 大模型發展。研究機構SemiAnalysis創辦人Dylan Patel表示,考慮到Meta的營運規模,一旦大規模成功部署自研晶片,可望每年節省數億美元能源成本,以及數十億美元晶片採購成本。
OpenAI也開始尋求數十億美元的資金來建造人工智慧晶片工廠網路。外媒報道,OpenAI正在探索製造自己的人工智慧晶片。而Open AI的網站開始招募硬體相關的人才,官方網站上有數個軟硬體協同設計的職位在招聘,同時在去年九月OpenAI還招募了人工智慧編譯器領域的著名牛人Andrew Tulloch加入,這似乎也在印證OpenAI自研晶片方面的投入。
不只Meta和OpenAI,根據The Information統計,截至目前,全球有超過18家用於AI 大模型訓練和推理的晶片設計新創公司,包括Cerebras、Graphcore、壁仞科技、摩爾線程、d-Matrix等。(半導體產業縱橫)