
「借助OpenAI 的能力,Figure 01 現在可以與人全面對話了!」
本週三,半個矽谷都在投的明星機器人創業公司Figure,發布了自己第一個OpenAI 大模型加持的機器人demo。
這家公司在3 月1 日才剛宣布獲得OpenAI 等公司的投資,才十幾天就直接用上了OpenAI 的多模態大模型。
如你所見,得到OpenAI 大模型能力加持的Figure 01 現在是這個樣子的。

它可以為聽從人類的命令,遞給人類蘋果。

將黑色塑膠袋收拾進框框。

將杯子和盤子歸置放在瀝水架上。

需要強調的是:你看到的這一切,只用到了一個神經網路。
廣大網友在看到如此驚豔的demo 後,對機器人的發展速度感到震驚,我們似乎正處於這場洶湧的進化浪潮中。甚至有人感嘆,已經準備好迎接更多的機器人了。

還有網友調侃道:「波士頓動力:好的,夥計們,這是一場真正的競爭。讓我們回到實驗室,設計更多舞蹈套路。」

所有這些,全是機器人自學的!
Figure創辦人Brett Adcock表示,影片中Figure 01展示了端對端神經網路框架下與人類的對話,沒有任何遠端操作。並且,機器人的速度有了顯著的提升,開始接近人類的速度。

Figure機器人操作資深AI工程師Corey Lynch介紹了此次Figure 01的技術原理。他表示,Figure 01現在可以做到以下這些:
●描述其視覺體驗
●規劃未來的行動
●反思自己的記憶
●口頭解釋推理過程
他接著解釋道,影片中機器人的所有行為都是學到的(再次強調不是遠端操作),並以正常速度(1.0x)運作。
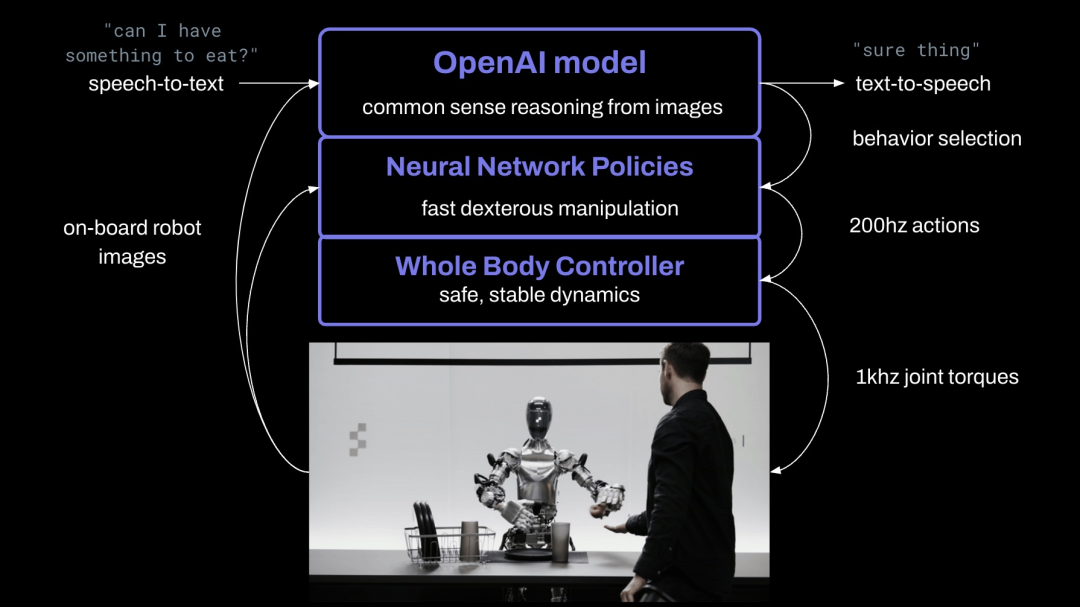
在具體實現過程中,他們將機器人攝影機中的圖像輸入,並將機載麥克風捕獲的語音文字轉錄到由OpenAI訓練的大型多模態模型中,該模型可以理解圖像和文字。該模型對整個對話記錄進行處理,包括過去的圖像,從而獲得語言回應,然後透過文字轉語音的方式將其回復給人類。
此外,該模型負責決定在機器人上運行哪些學習到的閉環行為以完成給定的命令,從而將特定的神經網路權重加載到GPU上並執行策略。
將Figure 01 連接到大型預訓練多模態模型為其提供了一些有趣的新功能。Figure 01 + OpenAI 現在可以:

理解對話歷史的大型預訓練模型為Figure 01提供了強大的短期記憶
考慮一個簡單的問題:「你能把它們放在那裡嗎?」
其中「它們」指的是什麼?「那裡」又是哪裡?正確回答這個問題需要反思記憶的能力。
透過預先訓練模型分析對話的圖像和文字歷史記錄,Figure 01快速形成並執行計劃:1)將杯子放在瀝水架上,2)將盤子放在瀝水架上。

關於學習的低階雙手操作,所有行為均由神經網路視覺運動transformer策略驅動,將像素直接映射到動作。這些網路以10hz 的頻率接收機載影像,並以200hz的頻率產生24-DOF 動作(手腕姿勢和手指關節角度)。
這些動作充當高速“設定點”,以供更高速率的全身控制器追蹤。這是一個有用的關注點分離,其中:
最後他表示,即使在幾年前,自己還認為人形機器人規劃和執行自身完全學得行為的同時與人類進行完整的對話是幾十年後才能看到的事情。顯然,現在已經發生太多變化了。
Figure,具身智慧時代最熱新創公司
最近,生成式AI 的競爭正走向長文本、多模態,各家科技公司和機構也沒有忘記投資下個熱點——具身智能。
具身智能,對於電腦視覺、機器人等領域來說是一個很有挑戰的目標:假設AI 智能體(機器人)不僅能接收來自資料集的靜態影像,還能在三維虛擬世界甚至真實環境中四處移動,並與周圍環境交互,那我們將迎來技術的一次重大突破,從識別圖像等機器學習的簡單能力,轉變到學習如何通過多個步驟執行複雜的類人任務。
被生成式AI 龍頭OpenAI 看好的具身智能,最有希望通往具身智能的公司,似乎就是這家Figure。
3月1日,Figure 宣布完成驚人的6.75 億美元B 輪融資,公司估值達26 億美元。一眼望去,感覺半個矽谷都投了它:微軟、英特爾、OpenAI Startup Fund、Amazon Industrial Innovation Fund 、英偉達、貝佐斯、「木頭姊」的方舟投資、Parkway Venture Capital、Align Ventures 等。
該公司的產品Figure 01,據稱是世界上第一個具有商業可行性的自主人形機器人,身高1.5 米,體重60 公斤,可承載20 公斤貨物,採用電機驅動。它的可工作時長是5 小時,行走速度每秒1.2 米,可以說很多指標已經接近人類。
自2023 年1 月以來,人們對Figure 的關注度一直在上升。雖然到目前為止,公司一共才發布過四個demo 影片。其中的一個展示了Figure 01 是如何製作咖啡的:

根據Figure表示,機器人練習這些動作的方法是端到端的,神經網路的訓練時間是10小時。
在2 月27 日的影片裡,Figure 01 自主完成了一個典型的物流環節任務-搬運空箱。

當然,速度還是比人類慢了許多。不過在這些任務中,Figure 01 都是完全自主地執行任務。所謂「完全自主」,是指只需將機器人放在地面上(無論放在屋裡什麼地方),在沒有其他用戶輸入的情況下,直接按開始就行。
在受過訓練的大型視覺語言模型( VLM )幫助下,人形機器人會先辨識、定位目標箱子,然後推理合適的拿放姿勢。接下來,Figure 01 會導航自己到目標跟前,偵測抓取點和手部力量,嘗試抓取成功並將箱子放到傳送帶上。
這些技術亮點也是Figure 和一直希望回歸機器人領域的OpenAI 達成合作協議的重要原因之一——將OpenAI 的研究與Figure 的機器人經驗結合起來,為人形機器人開發下一代AI 模型。OpenAI 也希望將自己的高效能多模態大模型擴展到機器人領域。
除了接受大筆創投之外,Figure 也在積極拓展落地場景。目前,Figure 01 已經開始在寶馬位於南卡羅來納州斯帕坦堡的汽車工廠接受測試,人們計劃讓機器人取代人類從事一些危險度高的任務。 (機器之能)
參考連結:
https://twitter.com/i/status/1767913661253984474
https://www.figure.ai/