
核心論點:
過去一年AI價值鏈正發生劇烈遷移:AI實驗室從幾乎"零毛利"躍升為價值大贏家。
Anthropic ARR從9B暴漲至44B+,推理毛利從38%飆至70%。
而身處供給瓶頸的TSMC與Nvidia卻仍未對定價做出明顯反映。

01. AI價值鏈的劇烈遷移
"AI的一天,勝過其他行業的一年"
模型發佈、軟體突破、硬體迭代,正把其他行業以年為單位的周期壓縮到以"周"為單位。
過去幾個月,Agentic AI跨過了真正的拐點——Token的"價值"經歷了一次躍升,而生產Token的"成本"卻在同步快速下降。
這股需求洪流來自終端使用者從消費Token中獲得的巨額ROI。
僅以本年為例,Anthropic的ARR從9B暴增至44B+,與此同時其推理基礎設施毛利率從38%躍升至70%以上。
獨特現象:"AI浪潮在堆疊的所有層都創造了價值——但過去一年裡,幾乎所有價值都在向AI實驗室集中,而它們一年前幾乎沒有獲取任何價值。"
終端使用者的"生產力豐收"
過去需要數十人時、耗費數千美元的工作,如今幾分鐘、價值幾美元的Token就能完成。Token產生的商業價值正在劇烈改善企業經營。
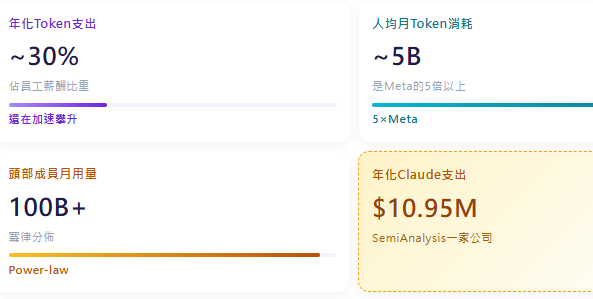
SemiAnalysis自身在Anthropic Claude Token上的年化支出已高達1095萬美元,但由此獲得的價值讓其能夠在與所有競爭對手的競爭中勝出並擴大市場份額。
- 2023年5月 ── AI交易元年
Nvidia首次"重磅炸彈"業績公告,盤後大漲25%,正式拉開AI交易序幕。
- 2024年 ── 電力成為新瓶頸
Vistra +265%、GE Vernova +146%,躋身S&P 500表現最佳個股。
- 2025年 ── 儲存搶鏡
SanDisk、Western Digital、Seagate、Micron全部錄得200%+漲幅。
- 2025年12月 ── Agentic AI"真正可用"的拐點
Agentic AI開始真正發揮效用,從程式設計蔓延至建模、Excel轉Dashboard、財務分析等場景。
- 2026年至今 ── 價值"全面回流"模型層
從硬體層向模型層的價值大遷徙正在發生,AI實驗室成為新主角。
02. Agentic AI改變了遊戲規則
SemiAnalysis的"自家實測":Token用量已是Meta的5倍
Agent早已不止於程式設計。SemiAnalysis分析師每天用Agent把Excel轉為儀表盤、自動生成圖表、建構財務模型、分析公司財報——這些任務此前要麼根本做不了,要麼需要初級分析師花費數小時,擠佔其本可投入更高價值工作的時間。
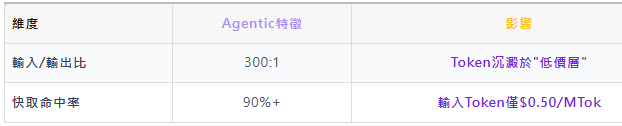
"貼牌價"vs"真實混合價":Opus 4.7的隱藏邏輯
Opus 4.7的官方掛牌價為$5/$25 per MTok(input/output),但其在Agentic任務上的真實混合價僅約$0.99/MTok。原因有二:
03. Token生產成本崩塌式下降
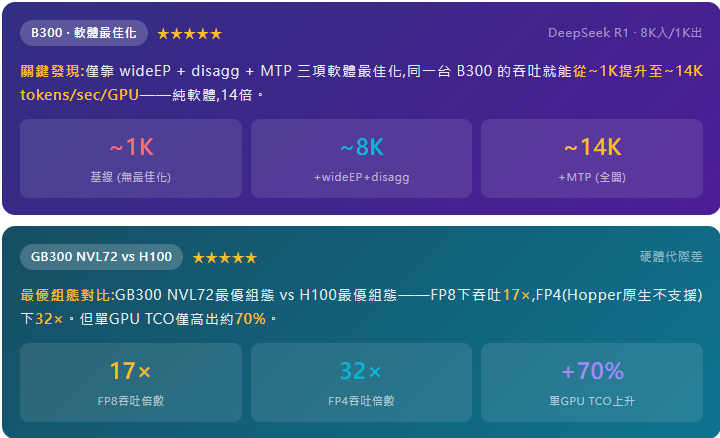
Opus降價≠毛利下降:Anthropic利潤仍在擴張
Anthropic在2025年11月以低於前代3倍的價格發佈Opus 4.5,引發市場驚愕。但事實是——由於Trainium與Nvidia GPU上的軟體改進、以及用Blackwell替換Hopper的硬體升級,其Opus Token的毛利率反而上升了。
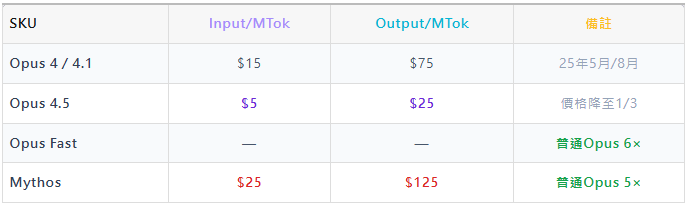
04. 為何模型利潤不會被競爭"卷"掉
- 理由一:前沿模型仍保有定價權
無論benchmark怎麼說,在真實知識工作場景下,開源模型與閉源前沿模型仍存在顯著差距,而這一差距沒有理由很快收斂。Kimi K2.6 ($0.95/$4) 對Opus定價幾乎構不成下行壓力。
- 理由二:算力供給約束 → 沒有任何一家能"獨食市場"
Anthropic已開始用$100+/月的Claude Code訂閱牆、遮蔽OpenClaw等第三方harness來主動疏離部分使用者。Token需求將在可預見的未來遠超供給,這意味著任何能提供前沿質量的實驗室,都可以按"Token產生的經濟價值"而非"內卷價"來定價。
05. TSMC與Nvidia——兩個未漲價的霸主

需求"複利式增長",但供給方仍在用舊框架定價
Anthropic ARR已達$44B+(我們上次更新時還是$30B),GLM、Kimi等開源模型也在擴大可定址算力總池。
AI實驗室與Neocloud的融資正在直接轉化為增量GPU部署。
而Nvidia仍在用一套"為單位算力支付意願會隨時間衰減"的舊假設來定價——這個假設已經不成立。
需求不是線性,而是複利級。
SemiAnalysis觀點:
"TSMC本可以大幅漲價,但他們沒有。這是戰略失誤。退一步,他們至少應該要求更大額的預付款。Jensen本人在2024年就說過TSMC的晶圓該貴一點——他是真心的。"
06. SOCAMM:Nvidia下一個利潤槓桿
為什麼是"記憶體"而不是"算力"?
SOCAMM (System-On-Chip Attached Memory Module)是 VR NVL72 上一種基於 LPDDR 的可插拔(Socketed)模組化記憶體方案。它專為機櫃級系統而生,具備更高容量、模組化、能效以及——獨立於算力的可定價能力。
在GB300中,DRAM被銲接(soldered)上板,與系統毛利捆綁。但在Rubin中,SOCAMM2是Socketed模組——這意味著Nvidia可以把記憶體"拆出來單獨定價",在板級毛利不變的前提下,單獨調高記憶體毛利。
SOCAMM 60% 毛利完全合理(來自SemiAnalysis測算)
SOCAMM合約價路徑(Nvidia採購)
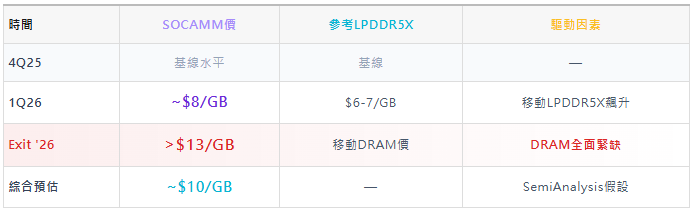
為何客戶會接受Nvidia在SOCAMM上索取60%毛利:
① 供應鏈籌碼:DRAM全面緊缺,Nvidia鎖住最大份額
② 平台護城河:VR NVL72是性能/TCO最佳平台,客戶被迫接受
③ 成本傳導合理:Nvidia自身也面臨SOCAMM2進價上漲
07. Capex/W:GB300 →VR NVL72 的反常停滯
系統躍遷巨大,但Capex/W幾乎沒動
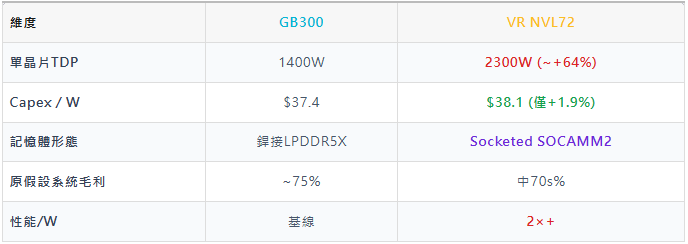
這與AMD/Nvidia/ASIC歷史代際趨勢完全相反——意味著Nvidia"留了一手"
08. Neocloud被歧視性定價的"祭壇"
SN5610交換機:Neocloud買價竟是Hyperscaler的2倍
Nvidia在GPU上幾乎不做客戶分級定價,但在網路裝置上對Neocloud實施明顯的歧視性定價。原因不是Hyperscaler採購量更大,而是Hyperscaler有直接對接OEM/ODM、自建網路方案的工程能力,而Neocloud只能選擇Nvidia的Turnkey方案。
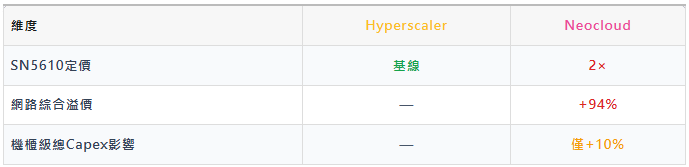
即:網路裝置的94%差價被攤薄成10%總capex差異——Nvidia已最大化壓榨這一槓桿,繼續往下摳的空間已經不多。
09. One Chart to Rule Them All VR NVL72租賃定價框架
- 成本基礎定價 (Floor) 滿足Neocloud項目最低IRR的租金,低於此線則不會有新部署
- 價值基礎定價 (Ceiling) 基於$/PFLOP的代際平價,客戶在新舊GPU間無差別選擇的臨界點

從"成本定價"到"價值定價"——Nvidia的下一跳
Nvidia當前仍在用"成本框架"定價。但隨著推理ROI越來越被廣泛接受,定價基準會自然向"價值定價"遷移——這正是反壟斷阻力下降、Nvidia可以堂堂正正漲價的窗口。
需要強調,以上分析僅基於"租金/FLOP"。但推理性能/TCO的代際改善,速度比FLOP還要快得多——VR NVL72的真實"價值天花板"可能比我們當前測算更高。Nvidia可以捕獲的價值空間,遠沒有觸頂。
RISK 風險與潛在反方向變數
- 反壟斷:Nvidia在GPU、互聯、軟體全端的支配地位已招致更嚴密的反壟斷審視。激進漲價可能加劇監管壓力,這正是Nvidia與TSMC都傾向"克制定價"的核心原因。
- 客戶多元化加速:過快搾取價值會促使客戶加速遷移至TPU、Trainium等替代算力;但這些方案同樣受N3晶圓與DRAM上游約束。
- 前沿模型質量收斂:若開源模型在真實知識工作場景下顯著縮小與閉源前沿的差距,AI實驗室的定價權將受到壓縮——但目前沒有證據顯示這一收斂正在發生。
- DRAM周期反轉:當前DRAM緊缺局面是支撐Nvidia在SOCAMM上索取高毛利的關鍵。若供給端在2027年大幅釋放產能,記憶體定價槓桿會被削弱。(FinHub)