
上周末開始,大摩 Howard Kao 團隊 2026 年 5 月 22 日發的一張 NVIDIA NVL72 單機櫃 BOM 拆解圖,在中文投資圈持續刷屏。這張圖把現役旗艦 GB300 估算到 399 萬美元一櫃,下一代 VR200 拉到 780 萬美元,整櫃漲 95%;其中記憶體 +435%、PCB +233%、MLCC +182%、NVLink Switch 晶片 +122%、Other networking chips +121%、ABF +82%、GPU +57%。
24 小時內,很多人把它拆出了兩種讀法。一種是順著記憶體、PCB、覆銅板、MLCC、ABF、液冷、電源的漲幅排序,給出一份公司清單。另一種是把 Other networking chips 這一行的 +121%,直接讀作「光模組要爆發」。
第二種解讀,這周大機率還會繼續放大。但這張 BOM 不能用來證明光模組爆發,因為它統計的是機櫃內成本;真正的光模組用量發生在機櫃外,在這張表裡看不到。光模組的需求是真的在翻倍,只是它的證據不在這張圖裡。
今天的這篇文章,我們一起從光電的視角,來聊一聊這個 BOM 清單。
這張 BOM 算了什麼
正文之前,先用一張表把 BOM 的「邊界」畫清楚。
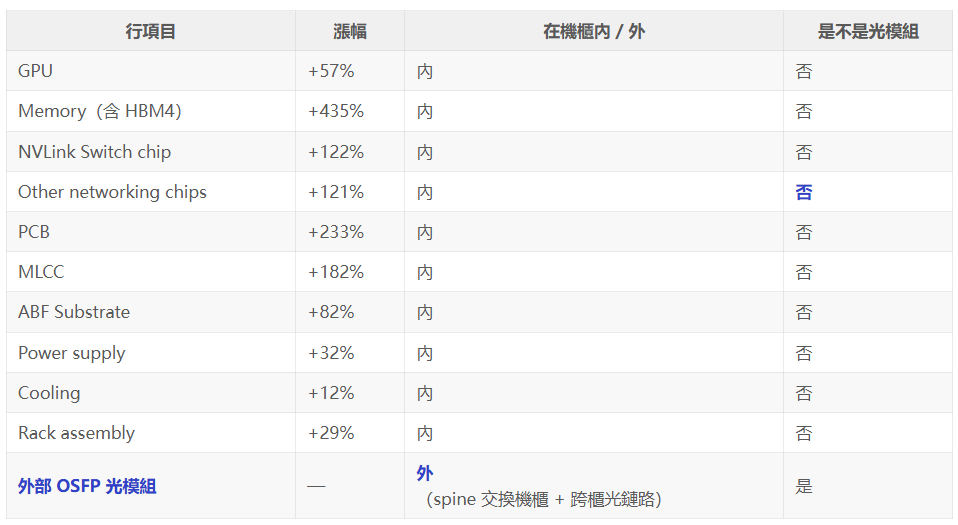
機櫃內的物料漲價是真的,但外部光模組屬於跨櫃網路,不在這張 BOM 裡。
NVIDIA 自己披露的資料可以印證這件事。NVIDIA FY27 Q1(對應自然年 2026 年 2-4 月)業績公告披露,Data Center networking 收入達到 148 億美元,同比 +199%、環比 +35%。這個體量是 NVIDIA 網路業務的總盤子(包含 NIC、Spectrum/Quantum 交換機、Spectrum-X Photonics 等),不在 MS 這份機櫃 BOM 裡;光模組和外部 scale-out 網路的真實增量,要去這本帳裡看。
+121% 為什麼不是光模組
機櫃內 +122% 的 NVLink Switch 這一行,背後只有一個原因:NVSwitch ASIC 數量從 18 顆翻倍到 36 顆。NVIDIA Rubin 平台官方技術部落格與 SemiAnalysis 都核到 VR200 的 NVL6 switch tray 每個裝 4 顆 ASIC,9 個 tray 合 36 顆,對應的恰好是數量翻倍。
Other networking chips 這一行的 +121% 沒有公開的逐項明細,但綜合 NVIDIA Rubin 平台 blog 與 SemiAnalysis 的拆解,主要構成是 ConnectX-9 SuperNIC 升級(CX-9 單 NIC 1.6 Tb/s,CX-8 為 800G)、BlueField-4 DPU 代際接替 BlueField-3、以及 NVSwitch / CX-9 普遍進入 224G SerDes 代際帶來的 IP 與 royalty 抬升。這些都是機櫃內的電晶片,沒有一項是外部光模組。
PCB +233% 是 BOM 內漲幅第二高,原因是 Rubin 的 compute board 從 GB300 的 22 層升到 26 層 HDI,材料從 M6/M7 類換到 M8 級高頻低損耗,switch tray PCB 升到 32 層,midplane 引入 44 層。直接動因是 224G PAM4 的單位間隔約減半,插損、串擾和均衡預算顯著收緊。要支撐這個速率,板層數必然增加,板材也必然換更高頻。MLCC +182% 與 ABF +82% 是同一脈絡,HBM4 與多 die 封裝把電源完整性與載板面積一起推高。
還有一件事實值得專門提一下,VR200 這一代,機內 NVLink 仍然是銅。SemiAnalysis 公開摘要確認,VR200 的機內 NVLink scale-up backplane 走的是 5,184 根 passive 銅飛線、4 個 cable cartridge、總長超過 2 mile,這套方案和 GB300 大致延續。只要單櫃內最長鏈路在 1-2 米以內,銅在 224G 時代仍然勝過光。在機櫃內,「光進銅退」目前還是個偽命題。這也是 BOM 內不出現光模組的物理根因。
光模組需求為什麼仍然翻倍
真正的光模組邏輯在機櫃外。
GB300 時代,每個 GPU 通過一顆 ConnectX-8 SuperNIC 拉出 800G scale-out 出口,72 GPU × 800G = 57.6 Tb/s 整櫃外聯頻寬。VR200 時代,每個 GPU 通過 ConnectX-9 拉出 1.6 Tb/s,72 × 1.6 = 115.2 Tb/s,整整翻一倍。NVIDIA 官方 Rubin 平台頁的「每 GPU 1.6 Tb/s scale-out 頻寬」是硬資料。當模組形態不變時,外部光連接的頻寬需求至少翻倍,光模組用量大體同步。
光模組公司的一季報已經在兌現這件事。中際旭創 Q1 營收 194.96 億、同比 +192%,5-15 投資者關係活動記錄裡公司原話是「1.6T 產品早已批次出貨,3.2T 持續研發完善中」;新易盛 Q1 營收 83.38 億、同比 +106%。但這一輪 1.6T 的錢不是均勻分佈的。兩條供應鏈口徑值得對照:天孚通訊 4-22 投關原話是「1.6T 光引擎已量產,但個別物料缺料尚未達到預期產量」;Lumentum 在 Q3 FY26 電話會上則明確說 200G EML 這一段「supply-demand imbalance greater than 30%」、公司「significantly undershipping demand」。中遊說等料沒等到,上遊說顯著欠交需求,方向是一致的。真正的錢有相當一部分正在向 EML / 雷射器這一段轉移。
2-3 年的現金流窗口
光模組需求翻倍是當下的事實,下一個問題是,這部分錢能賺多久?
NVIDIA 公開路線圖把 CPO 入機櫃分成三層。2026 H2 Rubin / VR200 代上市,Spectrum-X Photonics 與 Quantum-X Photonics 102.4T CPO 交換機首發,scale-out 網路側的 CPO 開始量產;機櫃內的 NVLink scale-up 仍然是銅。2027 H2Rubin Ultra 這一代換上 Kyber 高密度機櫃,按目前的公開路線圖,scale-up CPO 首次出現,但落在多個機櫃之間的 NVLink 互連上,機內仍以銅為主;Coherent CEO 在 Q3 FY26 電話會也確認了 scale-up CPO 收入預計要到 2027 日歷年下半年。2028 H2才是 Feynman。按市場和路線圖資料指向,NVLink 8 首次走光,CPO 進入更靠近 GPU 封裝的位置。
把這條時間線翻譯過來,機內 NVLink 真正光化要等到 2028。從 VR200 量產到 Rubin Ultra 切換,中間至少有兩代是 1.6T 可插拔的現金流窗口。Lumentum Q3 FY26 已經披露 200G EML 收入環比翻倍、1.6T transceivers Q4 FY26 ramp;產業鏈已經在兌現這個窗口。
這個窗口不是無限的。CPO 如果提前到 2027 H1 落地機內、1.6T ASP 在 2027 走出 10% 以上的降幅、Broadcom Taurus 把 3.2T / 400G-per-lane 節奏前推半年,這三件事裡任一發生,窗口都會被壓縮。三件事的機率目前看都不高,但值得放在 Q3 之後的電話會裡持續驗證。
回到開頭。一張大摩 BOM 圖,把光模組、PCB、覆銅板、MLCC、ABF 一起推到了 A 股 watchlist 上。每一列都有它的邏輯,但把「Other networking chips +121%」直接讀作光模組爆發,是在拿機櫃的帳本算網路的收入。同樣,這張圖也無法證明 PCB / 覆銅板 / MLCC 一定能傳導到對應公司的業績彈性,那是另一段鏈條的事。
接下來的這一周,我們將持續關注,NVIDIA Q1 財報電話會上 networking 業務的更多問答細節,以及 Lumentum 是否在 6 月給出 1.6T 模組 Q4 FY26 ramp 的具體節奏指引。 (光電前瞻)