
兩個月前,Google發佈了 Gemma 4 系列模型。此後,他們一直沒停:先是引入了多token預測(MTP)加速推理,兩天前補發了 12B 參數版本,填上 E4B 和 26B MoE 之間的空白。
今天,Google又推出了新的檢查點版本,核心技術是量化感知訓練(QAT),目標只有一個:讓 Gemma 4 能在手機、筆記本這類普通消費硬體上跑起來,質量幾乎持平量化之前
其中最關鍵的結果是:Gemma 4 E2B 的記憶體佔用被壓縮到了 1GB。
另外12B雖然可以在16G記憶體/視訊記憶體本上跑,但是速度太慢了,這次全新量化後12B-QAT,我在16G記憶體 M5 Macbook Air用LM Studio用了一下,果然比量化前的12B好用多了,token速度已經能接受了,建議上32G記憶體/視訊記憶體的本子,本地就有了真正可用的多模態模型了。
以下是詳細內容
量化為什麼難
量化是大模型上裝置的核心手段,原理是減少模型參數的精度,從而降低記憶體佔用、提高推理速度。但問題也在這裡:精度一低,模型質量往往跟著掉。
傳統方案叫"訓練後量化"(PTQ),即先訓練好模型,再壓縮。簡單粗暴,但質量損失難以避免。
Google這次採用的 QAT 方案不同。它把量化過程直接嵌入訓練階段,讓模型在訓練時就學會如何在壓縮狀態下正常工作。結果是:同等壓縮比下,QAT 的質量比 PTQ 更高。
各型號記憶體佔用一覽
Google為 Gemma 4 全系發佈了 Q4_0 格式的 QAT 檢查點,同時為 E2B 和 E4B 這兩款邊緣模型專門設計了一套移動端量化方案:
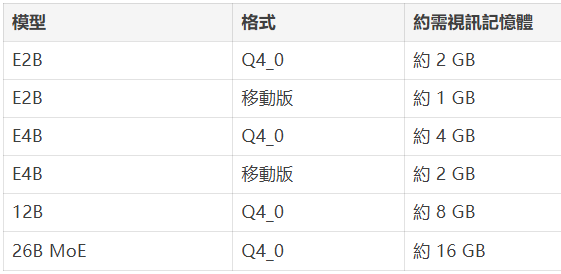
對於只需要文字功能的場景,由於音訊和視覺編碼器可以不載入,Gemma 4 E2B 純文字模型的記憶體佔用可以低於 1 GB。
移動端量化方案的細節
標準壓縮格式往往對手機晶片不友好,計算效率低。Google針對移動端硬體特性,專門設計了一套量化方案,主要包含以下幾個機制:
靜態啟動值。 通常模型在推理時需要即時計算啟動值的縮放參數,這會消耗額外算力。Google把這些參數在訓練階段就預先算好固定下來,減少了手機晶片在執行階段的負擔,響應速度也更快。
通道級量化。 壓縮後的資料結構按照移動端加速器的設計方式來組織,讓手機可以直接原生執行計算,不需要額外的轉換步驟。
2 位定向量化。 對負責生成token的部分進行高強度的 2 位量化壓縮,而核心推理層仍保持較高精度。這樣可以大幅節省儲存空間,同時不損害模型的理解和推理能力。
嵌入層與 KV 快取最佳化。 重點壓縮模型的詞彙表(嵌入層)和對話短期記憶(KV 快取),大幅降低執行階段的活躍記憶體佔用,讓使用者可以進行更長的對話而不會記憶體溢出。
怎麼用
Google已經和多個主流開發工具完成了對接,今天起即可使用:
獲取權重: Q4_0 和移動版模型權重已在 Hugging Face 上線。GGUF 格式可直接用於 llama.cpp,壓縮張量版本適配 vLLM。
本地桌面運行: 支援 llama.cpp、Ollama、LM Studio 等常用工具,下載即用。
端側部署: 可以使用Google的輕量化執行階段 LiteRT-LM,也可以通過 Transformers.js 直接在網頁端運行。
開發工具鏈: 大模型服務支援 SGLang 和 vLLM,Apple Silicon 平台可用 MLX 最佳化,微調支援 Hugging Face Transformers 和 Unsloth。MTP QAT 檢查點可在量化的同時保留 MTP 帶來的推理加速效果。 (AI寒武紀)