
Yann LeCun 大家一定不陌生——圖靈獎得主、CNN 之父、深度學習三巨頭之一。
他的觀點散落在各種訪談和推文裡,零碎又常被斷章取義。所以這次,我們把 LeCun 的判斷系統梳理了一遍,連成一條線,看看在他眼裡,LLM 接下來該往那走。
這篇是 Datawhale DIY-LLM 開放原始碼專案的拓展篇,帶你看看大模型這條路本身能走多遠。 文章有點長,大家可以慢慢讀~
先給結論
1. LLM不是終點,但不會消失。它會長期作為"語言與知識介面層"存在,是智能系統的"語言皮層",而非完整大腦。
2. "下一詞元預測 + 規模化"很難通向通用智能。核心缺口是兩個:預測行動後果的能力,以及基於搜尋的多步規劃。
3. VLA在當前範式下已接近失敗。LeCun直接判斷"VLA pretty much seen as a failure",核心原因是可靠性不足、資料依賴過重、泛化脆弱。
4. 世界模型的關鍵不是"畫出世界",而是"在抽象表徵空間預測可控後果"。水瓶類比精準揭示了像素級預測的無效性。
5. JEPA的價值在於把學習目標從重建細節轉向可預測的語義狀態;其成敗關鍵在於防止表示坍縮。當前最有前景的路徑是SIGReg方向。
6. LLM本質上不安全,且這一問題在當前範式下無法根本修復。目標驅動AI(Objective-Driven AI)才是安全可控智能體的正確架構方向。
7. 開源生態最終會贏得平台戰爭。Tapestry聯邦訓練機制是LeCun對主權AI問題的工程回應。
8. 未來更可能是雙系統分工:LLM負責語言與知識互動,世界模型負責理解物理世界與規劃行動。
一、為什麼LLM不是終點?
LeCun的觀點從一開始就很明確:LLM本身並沒有問題。 它們已經成為許多實用AI產品的基礎設施,我們每天都在使用這些系統,包括他自己也在使用。但他認為,LLM的成功並不意味著它們就是通向通用智能(AGI)的正確路徑。
這一判斷與許多相信“大規模語言模型持續擴展能夠逐步逼近通用智能”的研究者存在明顯分歧,其中包括部分來自Google和OpenAI等研究人員。
在LeCun看來,單純依靠下一詞預測和大規模語言建模,並不足以產生類人級智能,甚至難以達到許多動物所具備的那種智能水平——即理解世界、預測行動後果以及進行長期規劃的能力。因此,LLM是一種極其成功且有價值的技術,但更像是未來智能系統中的一個重要元件,而非最終答案。
讀到這裡,你可能已經想反駁了:"LLM明明能推導數學公式、能解釋物理定律、甚至能輔助科研——這難道不算'智能'?"
這個反駁非常合理,也是整個爭論的核心所在。LeCun並不否認LLM的表現令人印象深刻,但他認為"表現好"和"真正智能"之間存在一個關鍵的“裂縫”——而正是這道”裂縫“,決定了LLM能走多遠。
這道”裂縫“究竟在那裡?我們在第2小節展開分析。
1.1 有意義但不是正確的路線
為什麼說路線本身可能是錯的? 考慮一個簡單的日常場景:“我需要洗車,洗車店離我家100米遠。我應該走路去嗎?”
GPT-5.5的回答(圖1)建議走路去,理由是100米很近、省油省折騰——整個回答聽起來頭頭是道,卻將'車必須被開進洗車店'這一最基本的物理前提降格為邊緣性的例外。它解決的是一個不存在的問題。
對於我們來說,這個問題幾乎不需要思考:你要洗的是車,車必須被開到洗車店才能洗,所以答案是開車去。
但不少的LLM會抓住”100米很近”這一表層線索,建議你”步行“——它在做token等級的預測,而沒有理解”洗車需要把車帶到現場”這一隱含的物理約束。
這個例子雖然簡單,卻暴露了LLM的結構性盲區:它缺乏對真實世界物理約束的內在建模能力。但是,這並非我們通常所說的”幻覺”(hallucination)問題,而這裡的問題更深層:模型缺少”物理世界中的事物如何相互作用”的內部表徵,它只能在語言符號的統計規律中尋找答案。
幻覺通常指模型編造不存在的事實,例如虛構論文、錯誤引用或捏造資料等問題。
從LeCun等研究者的視角來看,目前的一些改進(比如tool呼叫、Prompt改進等方法)本質上仍是在現有框架下不斷最佳化模型的表現,而不是改變模型學習和理解世界的方式。就像是給汽車換上更好的輪胎和更強的發動機一樣,它們確實能讓LLM跑得更快、更穩、更遠,但汽車原本的工作原理並沒有發生改變。同樣,這些方法能提升LLM的表現能力,卻無法解決一個更根本的問題:LLM學到的主要仍然是語言符號之間的統計規律,而不是現實世界的運行規律。
一些研究者也注意到了這一問題,開始嘗試通過多模態訓練來突破純文字學習的限制。一方面,主要是讓模型同時學習文字、圖像、視訊甚至音訊,希望它能夠從這些資料中接觸到更多關於現實世界的資訊,而不僅僅是人類對世界的文字描述;另一方面,近期在高品質文字資料逐漸成為稀缺資源的背景下,多模態資料也被視為新的訓練來源。
然而,在LeCun等研究者看來,問題的核心並不只是資料量是否充足,而在於模型是否能夠從這些資料中學習到世界的結構、因果關係以及行動後果。即使擁有更多模態的資料,如果訓練目標仍然只是預測觀測資料本身,也未必能夠形成真正意義上的世界模型。那麼,為什麼會認為這是一個架構層面的問題,而不僅僅是模型規模還不夠大、資料還不夠多、資料模態有限的問題呢?要回答這一點,我們需要先思考一個更基礎的問題:LLM為什麼會如此強大,而讓LLM變得強大的,會不會也是限制其本身的?
1.2 LLM為什麼會成功?
LeCun認為,LLM能在語言任務上取得巨大成功,一個關鍵原因在於語言本身是由有限數量的離散token組成的。
這意味著模型的預測目標非常具體:給定已有的文字,從固定大小的詞表中預測下一個token的機率分佈。這個目標是可計算的,損失函數也是明確的。
在訓練過程中,LLM通過閱讀海量文字,學習token之間的統計關係和結構模式。LLM十分擅長解決規則明確、可客觀驗證的領域——數學答案可以代入檢驗,程式碼可以直接運行,這讓模型在訓練時能獲得清晰精準的反饋訊號,從而被更有效地糾偏和強化。然而,表現出色並不等於真正理解。模型更可能是通過反覆見過大量相似模式,習得了一種模式化的解題能力,而非真正理解了數學規律或程式碼邏輯。就像一個做了十萬道例題的學生,解題很厲害,但如果你問他"為什麼這個方法成立",他可能說不清楚。一句話總結就是:“知道怎麼做 ≠ 理解為什麼"。
那麼,LLM是如何通過訓練泛化到解決不同類型問題的?
LLM本質上是一個巨大的神經網路。預訓練階段,通過反覆的前向傳播與反向傳播梯度更新,將資料中的統計規律逐漸編碼進權重空間。而中訓練、後訓練等階段,則主要是在這個基礎上調整模型的輸出分佈——讓它更符合人類期望的回答風格、價值取向或特定任務需求。
打個比方:預訓練像是在一塊空地上建造了一座擁有海量藏書的圖書館;而後訓練則更像是培訓圖書館員,讓其知道該怎麼回答讀者的問題、那些話該說那些話不該說——書的內容基本不變,改變的是服務方式。
一些研究發現,LLM在生成回答時,還能夠通過鏈式推理(CoT)或結合顯式搜尋機制(如MCTS)等方法,表現出一定的推理路徑搜尋能力。提到搜尋能力,這雖很容易讓人聯想到AlphaGo Zero,但二者之間存在一個根本性的限制值得注意:
為什麼不能直接把AlphaGo Zero的方法復刻到LLM上?
AlphaGo Zero的核心優勢在於:有明確且可執行的圍棋規則作為環境,每一步都能獲得真實反饋,最終勝負可以明確驗證決策質量,並通過自博弈不斷最佳化策略,整個過程完全不依賴人類棋譜。
而LLM面對的大多數現實任務,根本不存在這樣清晰的規則、狀態轉移和反饋訊號。即使引入搜尋機制,也很難穩定判斷那條推理路徑是"正確的"——這是兩者難以直接類比的根本原因。總結來看,LLM的成功建立在兩個支柱上:大規模高品質的人類文字資料,以及通過反向傳播不斷最佳化權重的訓練機制——模型正是在這個過程中,學會了借助統計規律泛化到各類問題的解法。
然而,這一成功路徑本身也埋下了它的限制。自OpenAI提出Scaling Law以及DeepMind的進一步完善以來,業界形成了一個主流共識:模型規模越大、資料越多,能力就越強。既然成功高度依賴資料,那當資料本身開始觸及上限,這條路還能走多遠?
1.3 規模化或已觸及天花板
LeCun分析LLM的發展瓶頸時指出,高品質的人類文字資料正在逐漸接近極限。雖然網際網路每天仍在持續產生新的內容,但真正適合訓練前沿大型語言模型(LLM)的高品質公開文字並不是無限的。
根據Epoch AI的估算,目前可用於訓練的大規模高品質公開人類文字資料約為300兆Token,其95%置信區間約為100兆至1000兆Token。研究者進一步指出,如果未來模型繼續採用“過訓練”策略,即使用更多資料來提高推理階段效率,那麼高品質公開文字庫存甚至可能更早被充分利用。
為了直觀理解這個數量級,我們可以回顧一下這個場景——Llama 3-70B訓練使用的資料規模約為7000億Token(700 Billion),而300兆Token大約相當於其訓練資料規模的429倍。然而,近年來訓練資料規模增長極快,因此研究者開始擔心高品質人類資料會逐漸成為新的擴展瓶頸。例如其分析中提到,在較高過訓練倍率下,資料瓶頸可能出現在2025至2030年之間。
因此,越來越多AI公司開始探索新的資料來源,主要包括:
- 獲取版權資料或私有資料授權;
- 使用合成資料訓練模型,或者是提升資料利用效率;
- 從程式碼、視訊、機器人互動等其它模態獲取訓練訊號。
不過,“資料耗盡”並不意味著AI發展停止。近期,來自OpenAI的研究員在一次訪談中提到大家最關注的資料牆問題,業內已採用多種方式解決來克服這個問題,值得注意的是他也特別提到了合成資料。雖然合成資料已經成為緩解資料瓶頸的重要手段,並在數學、程式碼和推理任務中取得了顯著效果,但這種方式不僅適用場景存在不小侷限,還可能引發 “模型崩塌” 等問題。
模型崩塌是指AI在訓練過程中大量使用由AI生成的合成資料,而這些資料又缺乏嚴格的質量篩選時,生成資料中的偏差和誤差會在多輪訓練中不斷累積,使訓練資料逐漸偏離真實資料分佈。隨著這種偏離不斷擴大,模型會逐漸丟失真實資料中的稀有但重要的資訊,最終導致生成內容變得越來越單調、失真,並降低對真實世界資料的泛化能力。
資料瓶頸只是外部約束,LLM還面臨更根本的結構性限制,這是我們接下來會一起來分析的問題。
二、兩個核心缺口:為什麼LLM無法通向通用智能
事實上,LLM已經展現出了極強的語言能力和知識呼叫能力。但語言能力並不等同於對世界的理解——語言的成功建立在"離散token + 可計算預測目標"這一前提之上,而現實世界是連續的、混亂的、充滿不確定性的,無法被簡單地切割成有限個離散符號。
這正是LeCun近年來持續推動世界模型研究的核心原因:他認為通往真正智能的路,不在於把大語言模型越做越大,而在於讓模型學會像人類一樣,在內部維護一個"世界的運行模型",能預測行動的後果、理解因果關係,才能真正應對開放世界的問題。
一個具備通用智能的系統,不僅要能描述世界,還必須能理解世界如何運作,並預測自己的行動會帶來什麼後果。人之所以能完成複雜任務,並非依託語言表達能力,而是因為我們能在行動之前,先在腦海中預演各種可能的結果,再決定下一步怎麼走。
比如過馬路時,大腦會自動模擬:
- 現在向前走,會不會有車?
- 等幾秒,會不會更安全?
- 換條路,會不會更快?
整個過程中,人並不需要真正執行這些動作,而是在腦海中建立一個簡化的世界模型,對未來進行模擬和評估,然後才做出選擇。
LLM卻沒有這樣的內部模擬器。對它來說,輸出每一個token就是它的"行動"——它固然能說出"如果我這樣做,可能會發生什麼",但這更像是在復現訓練資料裡見過的類似表達,它在用文字模仿對世界的描述,而不是真正在內部模擬世界的運行。
這就引出了第一個侷限——缺少對行動後果的預測能力。
除了預測未來,智能還需要規劃未來。假設你要從重慶飛去巴黎,你不會隨機嘗試各種方案,而是會在腦海中同時比較多個選項:
- 直飛還是轉機,那個更便宜?
- 高鐵加飛機,反而更方便?
- 不同方案分別需要多少時間和開銷?
這是一個典型的搜尋與規劃過程:生成多個候選方案,評估每個方案的代價與收益,最終選出最優解。
LLM的工作方式與此截然不同。它生成回答時是逐token順序輸出的,根據前文預測下一個token,再預測下下個token,直到結束。它沒有一個內部系統去真正"構想多個未來、評估不同路徑、尋找最優策略"。
說到這裡,可能有部分小夥伴會感到疑惑:LLM明明有CoT多路徑解碼策略,怎麼能說它沒有"多路徑評估"呢?
這裡需要區分兩種"多路徑"的含義。LLM的多路徑,是在語言空間裡展開的——它生成好幾條不同的推理鏈,然後挑出最合理的那個答案。這個過程中,外部世界沒有任何變化,只有文字在變。
而我們這裡說的"多路徑規劃",指的是在物理狀態空間裡展開的——智能體先在"腦子"裡模擬"如果我往左走,世界會變成什麼樣;如果往右走,又會變成什麼樣?",再比較那條路更優。每一條路徑對應的是環境的真實變化,而不僅僅是一串文字的變化。
簡單來說:LLM的多路徑是換一種“說法”,世界模型的多路徑是換一種“走法”。近年來,Chain of Thought、Tree of Thoughts等技術確實增強了LLM的推理能力。但這些方法本質上仍然是在token序列的語言空間裡搜尋更合理的文字,而不是在真實世界的狀態空間裡推演未來變化——LLM比較的是"那段話聽起來更像一個好計畫",而不是"執行這步之後現實中還有那些選擇"。
這便引出了第二個侷限——缺少基於搜尋的規劃能力。
2.1 預測行動後果的能力
為什麼預測行動後果如此關鍵?
因為智能的本質不是反應,而是選擇。一個系統如果無法預判"做了這件事之後會發生什麼",它就只能被動響應當前輸入,無法主動權衡和制定策略。沒有這個能力,所謂的"行動"不過是刺激與反應之間的對應,和反射弧沒有本質區別。
那麼,智能的大腦究竟是怎麼做到"預測行動後果"的?神經科學家發表在《自然·神經科學》上的一篇論文,給出了一個顛覆直覺的答案:大腦本質上是一台預測機器,而不是一台反應機器。
我們通常以為大腦的工作流程是"先感知輸入、再分析、最後輸出行動"。但實驗證據顯示,大腦幾乎在任何時刻都在主動建構"如果我這樣做,接下來會發生什麼"的預測,感知的作用並不是觸發行動,而是校正預測——當現實和預測不符時,會觸發更新。
原因很簡單:處理感官訊號需要好幾百毫秒,而世界不會等你。大腦必須提前下注,用預測跑在現實前面。
比如,當你走進一條陌生的街道,看到前方有個模糊的小動物,你不會等大腦"看清楚是什麼"再決定怎麼做——你已經提前建構了"可能遇到威脅"的預測,準備好了應對方案,而"這只是一隻小狗"是在這個預測框架裡被更新進來的。
這就是智能真正運轉的方式:在內部持續模擬"行動→後果"的循環,用預測來指導行動,用感知來校正預測,不斷迭代。
而LLM與此存在一個根本性的差距。LLM並沒有這樣的內部模擬器,更關鍵的是,它也不需要這個模擬器:無論輸出什麼,它都不會承受任何後果,上一個詞造成的"影響"和下一個詞的預測之間,基本沒有明確的反饋回路。它描述行動後果的能力,來自訓練資料裡人類寫下的經驗,而不是自己模擬出來的現實。
那麼,LeCun打算怎麼解決這個問題?他的答案是JEPA,一個帶有內部世界模型的架構。
這個架構以配置器為核心調控中樞,統籌協調感知、世界模型、成本模組、短期記憶和Actor各元件,實現從環境感知、世界狀態建模、成本評估到動作生成的閉環決策過程。
其中,整個過程發生在行動之前,會先在內部的模擬,而不是盲目的試錯。JEPA原理會在第4小節中進行詳細解釋。
2.2 第二個缺口:基於搜尋的多步規劃
預測行動後果解決了"知道會發生什麼"的問題,但只有預測能力還不夠,智能還需要在多種可能的路徑之間進行搜尋,找到最優的那一條。
這兩種能力的關係是:搜尋以預測為前提。沒有世界模型告訴系統"走這條路會到那裡",搜尋就只能盲目試錯;有了預測能力,搜尋才能有方向:推進一步、評估結果、調整方向、再推進下一步——形成"預測 → 評估 → 修正"的閉環,而不是窮舉。
為什麼沒有預測,搜尋就會失效?
以圍棋為例:19×19的棋盤上,合法的局面數大約是 $10^{170}$ 種可能,比宇宙中的原子總數還多得多。沒有任何電腦能窮舉所有可能。AlphaGo Zero之所以能有能力擊敗人類頂尖棋手,正是因為它訓練出了一個價值網路,能夠直接評估"當前局面那些選擇有利"——這就是一個簡化的世界模型,它讓搜尋從漫無目的的窮舉,變成了有方向的剪枝。沒有這個評估能力,搜尋根本無從開展。
LLM的搜尋能力在這裡遇到了它的根本瓶頸。即使引入CoT或Tree of Thoughts,它的搜尋依然發生在語言空間,也就是說模型在比較的是"那條推理鏈讀起來更合理",而不是"執行這個行動之後,現實世界的狀態會變成什麼"。語言空間的搜尋和真實世界的狀態空間之間,始終存在一道沒有被填上的gap。
LeCun的JEPA架構想解決的正是這個問題:它的搜尋不發生在語言空間,而是直接在世界模型建構的狀態空間裡進行。Actor提出候選行動,世界模型預測每個行動之後的狀態,成本模組評估距目標的遠近,再反過來調整行動方案。這個過程可以滾動很多步,形成真正的多步規劃——而不只是"生成一段聽起來合理的推理文字"。
當然,JEPA能否真正在開放世界裡完成可靠的多步規劃,目前仍是開放的研究問題,因為現實任務的狀態空間遠比圍棋的狀態空間複雜,也沒有明確的規則和勝負訊號。但至少在架構設計上,它指向了一條和LLM根本不同的路徑。
2.3 為什麼這兩個缺口不能通過"打補丁"修復
RAG、Tool Use、Tree-of-Thought、反思鏈路等方案,本質上是在LLM外部疊加能力,而不是改善其內部的推理機制。它們共同面臨難以繞開的問題:
①規劃仍然發生在語言空間,而不是行動空間。無論推理鏈有多長、搜尋樹有多深,模型比較的始終是"那段文字聽起來更合理",而不是"那條行動路徑在現實中代價更低"。語言空間的搜尋和真實世界的狀態空間之間,始終存在一道沒有被填上的gap。
②對真實世界的泛化高度依賴大規模示範資料,學習效率極低。一個17歲的孩子花大約20小時就能學會獨立駕駛;而自動駕駛系統採集了數百萬公里的真實駕駛資料,在複雜場景下的表現仍然不穩定。背後的原因是:人類駕駛時有一個關於物理世界的內部模型,能舉一反三;而資料驅動的模型本質上是在記憶模式,遇到訓練分佈之外的場景,泛化能力會明顯下降。
③約束是後訓練"貼上去"的,不是架構層面的內生保證,並且這個辦法本身是有一定的代價。目前主流的做法是通過RLHF等後訓練手段,讓模型學會拒絕某些輸出。但這本質上是在預訓練完成的模型上做二次修正:用偏好資料調整模型的輸出分佈,讓它朝著人類期望的方向偏移。
問題在於,這個對齊過程是可能有損的。預訓練階段模型從海量資料裡習得的泛化能力,可能在後訓練的"偏好塑形"中被部分壓縮,模型變得更聽話,但也可能變得更保守,在偏好資料覆蓋不到的邊緣場景裡更容易失靈。更根本的困難是:即便付出了這個代價,安全邊界依然容易被繞過比如用文言文或罕見語言構造提示詞很容易讓模型繞開安全過濾,原因正是後訓練的偏好資料幾乎不覆蓋這類輸入。這說明後訓練解決的是"讓模型輸出看起來更合規",而不是讓模型真正理解"為什麼某個行動有害"——約束是外部施加的,不是從其內部“生長“出來的。
④常識缺失問題無法通過資料堆砌根本解決。 LLM的常識來自訓練資料裡人類寫下的經驗。訓練資料覆蓋到的場景,模型表現尚可;一旦遇到資料裡沒有明確出現過的情境組合,就容易出錯。比如"冬天氣溫驟降要不要把室外水管的水放掉",這類需要理解物理因果關係的日常判斷,對人來說是常識,對LLM卻是盲區。根本原因不是資料不夠多,而是模型沒有一個真正理解物理世界的內部模型,只是在匹配語言模式。
三、VLA:為什麼這條路走不通
上述問題,是LLM作為語言模型的內在、外部侷限。但還有一類問題,往往在討論中被忽略:LLM缺乏與物理世界的直接互動。事實上,另一種流行的診斷認為,LLM無法邁向AGI,根本原因不在於預測範式本身,而在於"感知-行動"的缺失——只要補上與物理世界的互動,語言模型的智能就能”落地“。於是,VLA(Vision-Language-Action)作為一種將語言模型能力延伸至物理行動的架構,成為了最受期待的解決方案。
2023年GoogleDeepMind發佈RT-2,直接推動二級市場將具身智能的商業化預期提前了三年。然而,當技術從實驗室走向真實場景,VLA的侷限性在學術研究和工業實踐中被反覆驗證——可靠性不足、資料依賴過重、泛化脆弱。一項近期調查指出,VLA領域有一個"核心瓶頸"至今未得到充分審視:支撐具身學習的資料基礎設施本身。而Yann LeCun在訪談中給出了迄今最直接的表態:”VLA現在基本上被視為失敗"。這一判斷並非孤立,而是建立在對VLA架構內在缺陷的清醒認識之上。從頂會論文的實證研究到行業應用的實際反饋,越來越多的證據正在印證這一結論。
3.1 VLA基本上被視為失敗
在訪談中,LeCun對VLA給出了明確的否定性評價:VLA就是視覺-語言-動作模型——用大語言模型技術訓練一個系統,接收視覺和語言輸入,輸出機器人控制動作(也可能有語言輸出)。這條路線現在基本上被視為失敗:不夠可靠,需要太多訓練資料,諸如此類。
在他看來,將大語言模型的成功經驗直接遷移到機器人控制領域,這一思路在實踐中已遭遇根本性障礙——把語言建模的範式強行套用在物理控制上,既缺乏可靠性,又對資料極度依賴。
3.1.1 什麼是VLA
VLA模型,你可以把它看作是給機器人或自動駕駛汽車配備的一個“大腦”。它嘗試將大語言模型(理解文字)和視覺語言模型(看懂圖像)的能力合二為一,直接轉化為物理世界裡的行動。
這個邏輯非常直接:用視覺“看見”環境,用語言“理解”任務,再把理解轉化為動作去執行。其核心思想就是打通從感知到決策的鏈路。
VLA模型就像一個端到端的統一系統,其工作流程可以理解為把視覺(Vision) + 語言(Language) → 動作(Action)。具體來說,系統接收到攝影機畫面和人類指令(如“拿起桌上的杯子”)後,內部會經歷幾個步驟:
- 環境感知:模型中的視覺編碼器會分析圖像,識別其中的物體、位置和狀態。
- 指令理解:模型會拆解使用者的自然語言指令,提取出關鍵意圖。
- 聯合推理:這是最關鍵的一步,模型會將視覺資訊和語言指令在統一的語義空間中進行“融合”,理解指令與場景的關聯。
- 動作生成:最後,動作解碼器會根據推理結果,直接生成機器人的控制指令(如機械臂的移動軌跡),完成整個任務。
VLA的思路在概念上看似合理,將機器人控制對應為類似語言建模的序列預測問題。然而,LeCun認為語言本身具有特殊性質,這使得自回歸預測在語言領域極其有效。但真實世界是和語言世界基本不一樣的,“訓練一個系統去理解真實世界要困難得多”。把適合語言領域的範式直接套用到動作空間,本質上是迴避了物理世界複雜性這個核心問題。
VLA的思路在概念上看似合理:將機器人控制對應為序列預測問題,借用語言建模的成熟範式。然而LeCun指出,自回歸預測之所以在語言領域極其有效,恰恰依賴於語言本身的結構,而物理世界並不具備這些性質。真實世界遠比語言世界複雜,理解和預測物理過程所需的建模能力,與預測下一個詞有著本質差異。因此,將語言建模範式直接套用到動作空間,並不是方法上的延伸,而是範式上的”錯配“。
3.2 VLA失敗的四個層面
VLA的失敗並非單一原因,而是四個相互關聯的層面共同作用的結果。
1.可靠性層面
VLA的不可靠並非抽象判斷,而是被大規模實證研究所證實的現實。2025年發表於軟體工程頂級會議FSE的研究《VLATest》提出了首個面向VLA模型的模糊測試框架,對七個代表性VLA模型在機器人操作任務上的表現進行了系統評估。該研究通過自動生成多樣化的操作場景,考察VLA模型在面對不同相機視角、光照條件、物體遮擋和未見物體時的表現。結論直指要害:當前VLA模型缺乏實際部署所需的魯棒性。研究進一步發現,混淆物體的數量、光照條件、相機姿態和未見物體等因素,均能顯著影響模型性能。
在VLATest之後,另一項系統性魯棒性研究《LIBERO-Plus》於2025年發佈,對多個最先進VLA模型進行了更全面的脆弱性分析。研究者在七個維度上引入可控擾動:物體佈局、相機視角、機器人初始狀態、語言指令、光照條件、背景紋理和感測器噪聲。結果令人警醒:VLA模型對擾動表現出極端敏感性,尤其在相機視角和機器人初始狀態方面,適度擾動即可使成功率從95%驟降至30%以下。更值得注意的是,模型對語言變化的響應卻極其微弱——後續實驗表明,VLA模型在相當程度上忽略了語言指令,更多依賴視覺線索進行決策。這一現象從側面揭示,VLA的泛化能力本質上停留在視覺模式匹配層面,而非真正建立起指令與動作之間的因果關聯。
為什麼會出現"忽略語言"的現象?一個合理的解釋在於訓練資料的結構性偏差:語言指令在演示資料中往往與特定視覺場景高度繫結,模型因此學會了"看圖行事",而非理解指令的語義內容。這也暴露了當前VLA更深層的問題——它本質上是在做”模式匹配“,而非物理世界建模。它能識別訓練分佈內的視覺場景並復現對應動作,但一旦場景或指令稍有偏移,便難以推斷應有的行為。而在真實物理世界中,這種脆弱性的代價與語言模型完全不同:LLM的輸出錯了可以重試、可以修正,代價可逆;機器人的動作直接作用於物理環境,錯誤往往不可撤回。
當前形式的大語言模型“無法變得可靠,因為無法阻止它們幻覺”。當這個不可靠性被嫁接到動作輸出上時,問題被急劇放大。一個編碼智能體如果出錯,可能“抹掉你的硬碟”;一個機器人如果出錯,可能損壞裝置、傷害人員。VLA繼承了LLM的所有不可靠性,卻要承擔遠為嚴重的後果。
2.資料成本層面
VLA的資料效率問題是LeCun批評的核心之一:它們是用海量資料訓練的……你需要大量資料來訓練這些系統進行模仿,這變得很昂貴,而且有點脆弱——換句話說,你想讓機器人解決的每個任務,你都需要收集大量資料。
這與LLM形成了鮮明對比。LLM的預訓練資料具有普遍的遷移性,在網際網路文字上學到的語言能力,可以被微調到無數下游任務。但VLA的模仿學習資料沒有這種遷移性。每個新任務、每個新環境、每個新操作對象,往往都需要重新收集演示資料。擴展到新任務時,成本不是次線性的,而是線性甚至超線性增長。
3.泛化層面
VLA的泛化能力瓶頸已被多項研究系統性地揭示。2026年發表於ICLR的論文《From Seeing to Doing》指出,當前VLA模型雖然建立在通用視覺-語言模型之上,但由於具身資料集的稀缺性和異質性,“仍然無法實現魯棒的零樣本性能”。這一判斷與LeCun對模仿學習泛化能力的質疑完全吻合。FSD方法雖然提出了通過空間關係推理生成中間表徵來改進VLA的方案,但其最佳模型的零樣本泛化——72%的成功率,距離工業部署的可靠性要求仍有巨大差距。
如果“模仿學習 + 大規模資料”足以產生真正的泛化智能,那麼數百萬小時的駕駛資料早該產出L5級自動駕駛了。事實是它沒有。問題不在資料量,差距在於學習範式本身。
VLA學到的本質上是“條件反射式”的行為對應:給定當前視覺場景和語言指令,輸出最可能的動作序列。這不是資料量能解決的問題,這是架構的泛化天花板。
4.規劃層面
VLA沿襲了LLM的核心推理範式:自回歸的、逐詞元的預測。在動作空間中,這意味著系統只能問“下一個動作應該是什麼”,而無法問“如果我這樣做會怎樣”。
LeCun在訪談中清晰地區分了這兩種範式——大語言模型沒有預測其行動後果的能力,也沒有任何規劃能力,因為推理是通過預測下一個詞元來完成的,而不是通過尋找。
VLA繼承了這一缺陷。它無法進行顯式的多步規劃,無法在行動之前模擬不同選擇的結果,無法進行反事實評估。但是這些能力恰恰是智能體在真實世界中可靠運作所必需的。
上述四個層面的分析,在工業實踐中同樣得到了印證。理想汽車基座模型負責人在2026年GTC大會上明確指出,當前業界VLA方案存在三個關鍵痛點:
- 3D空間理解與語義推理之間的對齊效率不足;
- 視覺-語言-行動傳遞鏈路過長導致的決策延遲;
- 長尾場景覆蓋不足,僅靠真實資料規模擴展難以突破。
北京大學王勇濤團隊的研究則從機制層面進一步揭示了三大缺陷:隱式規則學習導致罕見場景泛化差且可解釋性低;模態推理割裂,VLA模型僅限語言推理,無法深度融合視覺感知與語言規則;價值對齊缺失,只最佳化軌跡誤差,忽略交通法規與防禦性駕駛等人類偏好。
3.3 為什麼還有大量機構繼續押注VLA?
如果VLA真的如LeCun所說已經暴露出可靠性、泛化性和規劃能力等根本缺陷,那麼一個自然的問題是:
為什麼Google、NVIDIA、Figure、Physical Intelligence等機構仍在持續投入VLA路線?
事實上,這恰恰是當前具身智能領域最重要的爭議之一。
需要指出的是,LeCun對VLA的批評主要針對的是“VLA是否能夠成為通向通用智能(AGI)的核心路徑”,而產業界在押注VLA時,考慮的問題往往更加務實:它是否能夠在未來三到五年內解決真實商業場景中的問題。
從這個角度看,即便承認VLA存在明顯侷限,它仍然具有幾個世界模型路線暫時難以替代的現實優勢。
第一,VLA是目前工程成熟度最高的具身智能方案
世界模型、JEPA和目標驅動AI仍然處於相對早期階段。
相比之下,VLA直接繼承了過去幾年大模型領域最成功的一整套技術堆疊:
- Transformer架構
- 大規模預訓練
- 多模態對齊
- 指令微調
- 強大的基礎視覺語言模型(VLM)
這意味著研究團隊不需要等待新的理論突破,而是可以直接利用現有基礎模型快速建構機器人系統。
換句話說——世界模型更像是在探索下一代智能架構,而VLA更像是在利用當前最成熟的架構解決現實問題。
對於工業界而言,後者往往具有更高的投資確定性。
第二,許多機器人任務本身並不需要“完整世界模型”
LeCun的批評隱含著一個前提:機器人最終需要具備類似人類的長期規劃能力。
但在許多商業場景中,這一要求其實並不是必要的,例如:
- 倉庫分揀
- 工廠裝配
- 餐廳送餐
- 超市補貨
- 簡單家庭整理
這些任務往往具有幾個特點——環境相對固定、目標明確、動作空間有限、容錯要求可控。
對於這類任務而言,一個能夠覆蓋95%以上場景的模仿學習系統,可能已經具備商業價值。從商業視角看,機器人不一定需要成為“通用智能體”,只需要足夠有用。
因此,即使VLA無法通向AGI,也未必妨礙它在特定領域獲得成功。
第三,VLA正在不斷吸收世界模型思想
一個容易被忽略的事實是:當前的VLA與兩年前的VLA已經不是同一種東西。
越來越多研究開始嘗試將世界模型能力融入VLA框架之中,例如:
- 引入顯式狀態預測
- 未來軌跡推演
- 引入層級規劃模組
- 引入視訊生成或視訊預測能力
- 引入強化學習與搜尋機制
產業界並沒有嚴格站在“VLA陣營”或“世界模型陣營”。 相反,越來越多團隊正在嘗試融合兩條路線。 從這個角度看,未來的主流系統未必是一方取代另一方。而更可能是:VLA負責感知與動作表達,世界模型負責預測與規劃,兩者共同構成完整的智能體架構。
3.4 VLA的適用邊界
VLA有結構性缺陷,但這並不意味著它在所有場景下都毫無價值。LeCun的評價需要放在正確的語境中理解:他說VLA"走不通",指的是通往通用機器智能的路徑走不通,而不是說它在任何工程場景中都無用。
在受控條件、有限任務集、充足演示資料的情況下,VLA可以有效工作。固定工位的分揀與裝配、特定生產線的重複操作、約束明確的實驗室環境——這些場景中,VLA可以部署並產生實際的商業價值。LeCun本人對此並不否認:"如果它有效,那就很好。把它們擅長的事情用在它們擅長的地方,這沒有問題。"
但VLA的"擅長之處"邊界非常清晰。它的泛化上限決定了它只能在分佈內場景中穩定運行,一旦任務、環境或指令稍有偏移,性能便急劇下降。這使它可以勝任特定工程任務,但無法成為通用機器人的底座。而LeCun與其創業公司AMI(Advanced Machine Intelligence)所追求的,恰恰是後者——一種能夠在開放世界中自主推理、規劃和行動的通用具身智能。
正是這個差距,驅動了對VLA之外的新範式的探索。下一節將討論LeCun提出的另外一種路徑,以及他認為真正可行的具身智能架構應當具備那些要素?
3.5 世界模型並不是一個新概念
世界模型並非近年來才出現的新概念。從控制論到強化學習再到認知科學,研究者長期以來一直在探索智能體如何在內部建立對環境的表徵,並在行動之前模擬未來。 一些具有代表性的工作包括:
從理論到實踐探索了“世界模型”這一核心思想。從卡爾曼濾波奠定狀態估計理論和Dyna架構整合學習、規劃與反應-開始,經Ha & Schmidhuber用深度神經網路讓智能體學習世界模型和PlaNet從像素中學習潛在動力學,再到Dreamer系列通過潛在想像學習行為以及MuZero在未知環境中學習規劃實現超人類水平,後經LeCun提出基於內在動機和層次化聯合嵌入預測的自主智能架構-和I-JEPA從圖像中學習語義表徵、V-JEPA從視訊中學習視覺表徵,最終由LeWorldModel實現了穩定端到端訓練的聯合嵌入預測架構。
這些工作的共同點是:讓智能體在行動之前,先在內部模擬未來。它們在不同歷史時期、用不同技術路徑,反覆驗證了同一個核心假設——智能的關鍵不在於對外界做出即時反應,而在於擁有一個足夠好的內部模型來預判行動的後果。
LeCun近年來推動的JEPA路線,並不是"發明世界模型",而是試圖回答一個更具體的問題:如何通過自監督學習訓練出可擴展的、在抽象表徵空間中直接預測的世界模型? 前面的工作大多依賴像素重建或獎勵訊號作為訓練目標,而JEPA的突破性在於——它試圖完全拋棄重建目標,在潛在空間中學習"可預測的表徵",從而避免將模型容量浪費在不可預測的表面細節上。這正是接下來第4章要深入討論的內容。
四、世界模型:核心概念與JEPA架構
4.1 什麼是世界模型——LeCun的定義
LeCun給出了一個極為精練的定義:從非常寬泛的層面來講,世界模型是一種能讓智能體系統預測自身行動後果的事物。
注意這個定義的重心不在"生成",而在"預測後果"。換句話說,世界模型的存在意義是服務於規劃與決策,而非重建人類視網膜或攝影機捕獲的原始觀測。
LeCun也談到了對於Agent的看法,無法想像你怎麼會考慮建構一個沒有預測自身行為後果能力的能動系統。這意味著,在他的理論框架中,無法預判自身擬執行動作序列所產生後果的系統,尚不能被視作真正意義上的智能體。
4.2 水瓶類比為什麼不能用像素級預測
一個非常有說服力的直覺例子:以一個沒有瓶蓋的水瓶(裝滿水)為例,當你推它的底部時,它會在桌面上滑動;而當你推靠近頂部的位置時,它往往會翻倒。然而,你無法精確預測它倒下的方向是什麼,甚至不可能在像素等級的角度上預判這一點。這說明,我們對世界的建模與預測,是在抽象表徵的層面上進行的,而非微觀細節的層面。
這個例子背後有兩層深層邏輯:
第一,不可約的不確定性。真實世界的動力學充滿混沌與微觀細節,比如瓶子的倒向取決於桌面微觀摩擦、空氣擾動、液體晃動的湍流等。這些不是"噪聲",而是認知上不可壓縮的複雜性。試圖在像素空間建模 $P(pixel_{t+1}, action_{t})$ ,等於要求模型掌握從分子動力學到流體力學的全部物理知識。
第二,維度的詛咒。一張256×256的RGB圖像有196,608個維度,而壓縮後的語義表徵可能只有幾百維(如LeWorldModel中為192維)。在像素空間做預測,模型會把算力浪費在重建紋理、光照、陰影、水面折射等對決策毫無意義的細節上。更根本的問題在於,像素空間的資料分佈極度稀疏且多模態、不連續——同一個語義狀態("瓶子即將倒下")對應著海量在像素層面截然不同的具體實現,並且它們散佈在高維空間中一個極薄的流形上,模型極難從中學到穩定的預測結構。
在資訊理論的語言下,像素空間的條件熵H(pixel∣context)極高——即便給定充分的上下文,像素的取值仍高度不確定;而語義空間的H(state∣context)相對低且結構化,為可靠預測提供了穩定的著力點。認知科學也提供了佐證:人類心智並不進行"像素級心理渲染"。當你想像推瓶子時,你的直覺物理工作在一個抽象的、去噪的、物體為中心的表徵層——你知道"瓶子會倒",但你的大腦不會生成瓶身每個反光點的精確RGB值。JEPA的設計哲學正是對這一生物直覺的模擬:預測應該發生在語義表徵空間,而非像素空間。
4.3 生成式世界模型 vs JEPA:一個關鍵分叉
這是理解當前世界模型研究的核心分歧。
支援生成式世界模型(如Google的Genie,Sora類模型、Diffusion模型等)的研究者認為, 高保真視訊預測本身可能就是學習世界動力學的重要途徑。 Dreamer、Genie、Sora等工作也展示了生成式路線在環境建模方面的潛力。
生成式世界模型的路線:重建或生成觀測細節,訓練目標包含大量不可預測的噪聲(水的流向、光的折射等)。
這些模型的訓練目標本質上是最大似然重建:給定歷史幀或文字條件,建模 $P(observation_{t+1}, history)$ 的完整分佈。它們必須"畫"出每一幀的每一個像素——包括水的流向、煙霧的渦旋、衣物的褶皺等。
而LeCun則認為這條路線的根本缺陷在於:
- 浪費容量:模型參數被大量不可預測、與決策無關的噪聲佔據;
- 因果混淆:生成模型學到的是"什麼樣的畫面序列看起來合理"(統計相關性),而非"世界如何因果運行"(物理機制);
- 規劃無能:即使能生成漂亮的未來視訊,也無法在潛在空間裡做動作序列的最佳化與搜尋。
他特別提到MAE作為失敗案例:拿一張圖像,以某種方式對它進行損壞處理,然後訓練這個大型神經網路來恢復原始圖像,也就是最初的那張圖像。在臉書人工智慧研究院(FAIR)有一個關於此的大型項目,叫做掩碼自編碼器(MAE),但結果非常令人失望。競爭很激烈,卻沒有得到真正令人滿意的結果。
對於提到的問題,LeCun的解決辦法是什麼?
JEPA的核心訓練原理:有一個編碼器進行一種觀測,還有另一個編碼器進行不同的觀測,然後嘗試用一個預測器根據第二個編碼器的表示來預測第一個編碼器的表示。
這個過程是在語義表徵空間中進行的,其訓練目標是語義層的可預測性,而不是像素重建誤差。這讓模型學到的表徵是"可規劃的",而不僅僅是"可辨認的"。
具體而言這個過程的核心組成是:
- 聯合編碼器:將輸入 $x$ 和 $y$ (一個資料樣本的兩個不同視角,通常為視訊的前幾幀與後幾幀,或圖像的可見patch與掩碼patch)使用同一個編碼器,分別對應到同一個潛在空間中的 $s_x$ 和 $s_y$ ;
- 預測器:在潛在空間中,基於編碼結果 $s_x$ 和可選動作條件,預測 $\widehat{s}_y$ ;
- 訓練目標: ${\parallel \widehat{s}{y}-sg(s$ ,}) \parallel^{2}即預測表徵與目標表徵的誤差,而非像素重建誤差。其中 $sg( \cdot )$ 表示stop-gradient,防止梯度通過 $s_y$ 回傳,這是關鍵技巧——它強制預測器不能"偷懶"依賴解碼捷徑,必須真正學會從 $s_x$ 推斷 $s_y$ 。請注意JEPA有多種目標函數,這裡展示的只是最基礎的一種。
這讓模型學到的表徵是"可規劃的",也就是預測器在潛在空間裡推演動作後果,控製器可以在這個低維、結構化、去噪的空間裡直接做軌跡最佳化;相比之下,生成式模型的潛空間通常與下游決策脫節。
兩種路線對比
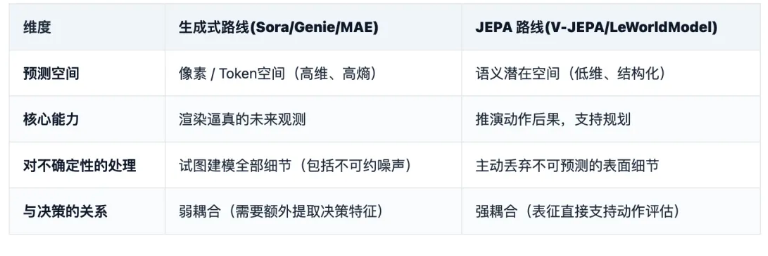
LeCun的觀點非常明確:
- 當前LLM(預測下一個token)和擴散模型(預測像素分佈)的成功是"感知層面的統計奇蹟",但它們缺乏真正的因果推演與規劃能力;
- JEPA路線不是要"生成"未來,而是要"理解"未來在抽象的潛在空間裡,掌握世界運行的動力學規律。
這決定了它能否從"視覺預訓練"走向"端到端自主智能體"。
4.4 從JEPA到世界模型:讓預測服務於規劃
JEPA的數學框架非常簡潔:考慮一個資料樣本的兩個不同視角,通常為視訊的前幾幀與後幾幀,或圖像的可見patch與掩碼patch。下面為便於理解,我們考慮視訊的當前幀和後一幀,分別記為 $O_t$ 和 $O_{t+1}$ ,則:$$Z_t=Enc( O_t ), Z_{t+1}=Enc(O_{t+1})$$
這裡 $Enc(\cdot )$ 是編碼器,通常是一個ViT或Transformer,將原始輸入對應到潛在向量。注意 $O_t$ 和 $O_{t+1}$ 共享同一個編碼器,因此稱為聯合嵌入。
接下來,預測器 $Pred(\cdot )$ 接收 $O_t$ 以及額外的動作條件資訊 $a_t$(例如動作指令、空間位置、掩碼token),嘗試預測 $O_{t+1}$ 的表徵:
$$\widehat{Z}_{t+1} = Pred( Z_t, a_t ) $$
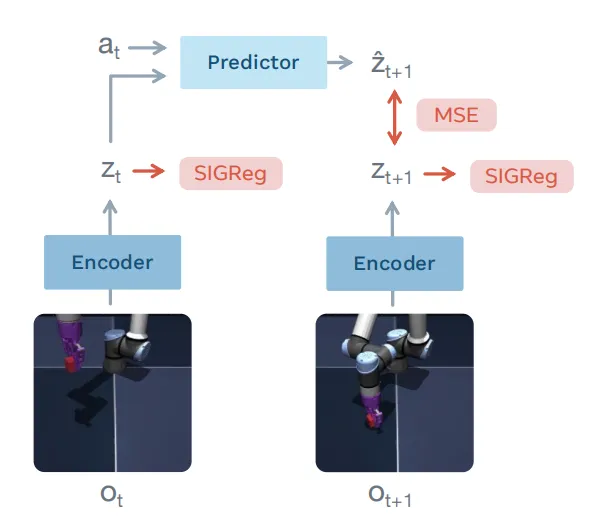
LeWorldModel發表於2026年3月,是LeCun在訪談結尾唯一推薦的具體世界模型論文,可見這篇論文的份量不低。在LeWorldModel中,編碼器和預測器採用了如下結構:
LeWorldModel編碼器
編碼器採用Vision Transformer(ViT)架構,具體配置為ViT-Tiny(約500萬參數):
- Patch size: 14×14
- 12層Transformer
- 3個注意力頭
- 隱藏層維度: 192
輸入是一張RGB圖像,輸出是一個低維的潛在表示向量。具體流程:
- 圖像被切分為14×14的patches
- 每個patch通過線性投影轉換為token
- Transformer處理所有token
- 提取最後一層的[CLS] token作為全域表示
- 通過一個1層MLP + Batch Normalization的投影頭得到
- 最終的潛在表示
注意:投影步驟中使用了Batch Normalization而非Layer Normalization,這是因為LayerNorm會限製表示分佈的方差,使得SIGReg正則化難以有效最佳化。
LeWorldModel預測器
預測器是一個Transformer(約1000萬參數):
- 6層Transformer
- 16個注意力頭
- 10% dropout
動作條件通過自適應層歸一化(AdaLN)注入到預測器的每一層中。AdaLN的參數初始化為零,確保在訓練初期動作條件的影響是漸進式的,而不是劇烈改變預測器的行為。
預測器接收歷史N幀的潛在表示,通過時間因果掩碼(temporal causal masking)自回歸地預測下一幀的表示。
LeWorldModel雙損失訓練:預測損失 + SIGReg
WorldModel的訓練目標是讓預測表徵逼近真實表徵,在淺層特徵上學習因果結構,而不是在像素層面(如Diffusion Model)或token層面(場景的LLM)去做預測。LeWorldModel和WorldModel的訓練目標是基本一致的。
$$ \begin{aligned} L&= \underbrace{\parallel Pred(Enc(O_{t}), a_{t} )-Enc(y) \parallel^{2}}{預測損失}+ \underbrace{ \lambda·SIGReg(Z)}\ \ &= \underbrace{\parallel \widehat{Z}{t+1}-Z} \parallel^{2}{預測損失}+ \underbrace{ \lambda·SIGReg(Z)}\ \end{aligned} $$
上面的目標函數除了預測損失項用來反向傳播最佳化編碼器和預測器,另外還使用了SIGReg(草圖各向同性高斯正則化) 來防止表徵坍塌。
表徵坍塌會在第5節進行介紹,簡單來說表徵坍塌是指:編碼器將不同輸入對應到高度相似、低多樣性的表徵,這些表徵聚集在特徵空間的一個狹窄低維區域,表徵的有效維度(可用PCA檢驗)遠低於其名義維度(向量維度),喪失了區分不同輸入所需的資訊量。
當JEPA擴展到動作條件 $a_t$ 時,就從表徵學習工具變成了世界模型:
給定當前狀態表徵 + 候選動作 → 預測未來狀態表徵有了這個,智能體就可以通過搜尋來規劃:在想像的行動空間中迭代,找到能將系統帶到目標狀態的行動序列。這正是LeCun強調的"objective-driven AI"架構。
LeWorldModel性能分析
在LeWorldModel的實驗裡,選擇四個任務進行驗證。覆蓋了從簡單到複雜、從2D到3D、從導航到操作的多樣場景,用來驗證世界模型在不同環境下的泛化與規劃能力。
下面介紹LeWorldModel取得的成果與存在的不足:
1.訓練穩定性
將損失函數從PLDM的7項、6個可調超參,壓縮到僅2項損失、1個有效超參 $λ$ ,LeWorldModel訓練曲線單調收斂,不再像PLDM那樣各損失項互相拉扯,如下圖。
2.控制性能
LeWorldModel的Push-T成功率96%, PLDM提升18%;在Reacher、TwoRoom等任務上與SOTA持平或更優。但在OGBench-Cube上略遜於SOTA模型,這是因為OGBench-Cube為視覺更豐富的3D環境,這使得端到端訓練編碼器比2D任務更具挑戰性;DINO-WM借助DINOv2的大規模預訓練知識(在約1.24億張圖像上訓練),對動態屬性和旋轉量等物理量具有明顯優勢;而LeWorldModel是從原始像素完全從頭訓練的 15M 參數小模型,缺乏這種先驗。
3.規劃速度
同等算力條件下,相較於DINO-WM,LeWorldModel編碼觀測資訊所用token數量減少約 200 倍,因此規劃速度可與PLDM持平,同時相比DINO-WM最高提速近 50 倍。
4.短視界規劃受限
當前latent world models的規劃能力仍侷限於短視界。自回歸逐步推演誤差會隨規劃長度增長而累積,難以支撐長程推理。層級化世界模型被視為解決長視界規劃問題的有前景方向。
5.對離線資料集的依賴與SIGReg的侷限性
方法仍依賴具備足夠互動覆蓋度的離線資料集,這類資料的收整合本高昂且困難。更具體地說:在資料多樣性有限、且環境內在維度很低的簡單場景(如TwoRoom)中,SIGReg強制要求隱空間匹配高維各向同性高斯先驗,會導致表徵學習困難、效果下降。
解決思路:在大規模、多樣化的自然視訊資料集上進行預訓練,以提供更強的表徵先驗,從而減少對領域特定資料的依賴。
6.對動作標籤的依賴
當前的端到端隱世界模型需要顯式動作標籤 才能預測未來狀態,而動作標註的獲取同樣成本很高。
解決思路:通過逆動力學建模來學習未來的動作表徵,有望減少對顯式動作標註的需求。
需要指出的是,LeWorldModel的意義更多在於驗證了JEPA世界模型路線的工程可行性,而非已經實現了通用世界模型。論文中的實驗主要集中於Push-T、Reacher、TwoRoom和OGBench-Cube等低維、受控、短時程任務,這些結果說明JEPA能夠穩定學習環境動力學並支援規劃,但尚未證明其具備開放世界中的長期推理、複雜因果建模和跨場景泛化能力。因此,更合理的定位是:LeWorldModel是JEPA路線的重要里程碑,而非世界模型問題的最終答案。
LeCun對未來12到18個月的規劃是:將進行演示,展示我們能夠訓練世界模型,或許是基於動作條件的世界模型,這能讓我們針對多種不同用例進行規劃。其中一些用例將涉及機器人技術,另一些則涉及各類工業過程控制。
4.5 工業應用:世界模型的近期價值
LeCun特別強調了世界模型在工業領域的短期價值,這往往被討論忽視:在工業領域有大量的應用場景,在這些場景中,你需要一個系統具備預測能力,即當我在這個複雜系統中改變某個控制變數時會發生什麼——這個複雜系統可以是噴氣發動機、化工廠、發電廠、某條生產線、病人或者人體細胞。
這些系統太複雜,無法用方程建模,但可以從資料中訓練神經網路來學習其動態。這是比機器人更近、更實際的落地場景,也是AMI Labs的短期優先方向之一。
五、表徵坍縮:JEPA最難的技術問題
神經網路在訓練時有一個天然的"偷懶"傾向:有些任務是相似的輸入輸出相似的結果,那索性讓所有輸入都輸出一樣的結果不就完了嗎?網路確實會這麼幹,這就是表徵坍縮。它是自監督學習裡最棘手的問題之一,也是JEPA架構必須正面應對的核心挑戰。
5.1 什麼是表徵坍縮
LeCun在訪談中專門舉了一個例子來說明這個問題:假設你把一段視訊的開頭片段和後續片段分別輸入同一個編碼器,再訓練一個預測器,讓它根據開頭的表徵去預測後續的表徵。
聽起來很合理,但系統會找到一條“捷徑”:乾脆把所有輸入都對應成同一個向量。這樣無論輸入什麼,預測器永遠"猜對了",損失函數一路下降,訓練看起來非常成功。
這就是表徵坍縮的本質:模型找到了一個”作弊解“。它不是真的學會了理解視訊內容之間的關係,而是靠"所有答案都一樣"矇混過關。表面上預測得很準,實際上沒有學到任何有效資訊。
5.2 三條解決路線:成熟度與侷限
關於如何解決表徵坍縮問題,LeCun提到了三種解決路線:對比學習、蒸餾方法和顯式正則化路線。
5.2.1 對比學習
對比學習(Contrastive Learning)的思路很直覺:與其讓模型"別坍縮",不如直接在表徵空間裡製造”排斥力”——
- 正樣本對(同一張圖的不同增強版本):在表徵空間裡被拉近;
- 負樣本對(不同圖片):被強行推開。
相當於給每個樣本劃定"領地",靠互相排斥防止表徵疊在一起。邏輯直觀,也確實有效。
但LeCun指出,對比學習在高維大規模場景下存在明顯的擴展瓶頸。
在高維潛在空間(比如768維、1024維)裡,空間本身極度稀疏。隨機採樣到的負樣本,大多數天然就離得足夠遠——它們早就被"推開"了,對訓練幾乎沒有任何貢獻。真正有價值的,是那些在表徵空間中和正樣本靠得很近、模型容易混淆的困難負樣本,但這類樣本極度稀缺,隨機採樣幾乎碰不到。
這就導致兩難困境:
- 欠採樣:大量負樣本都是"easy negative",提供不了有效梯度,正負表徵推不開,仍然容易坍縮;
- 過度採樣:為了找到困難負樣本而大量採樣,又容易把語義本來就相近的樣本暴力推開,反而破壞了表徵結構。
換句話說,”排斥力“在高維空間裡變得稀薄而失準——不是採樣不到到東西,而是採樣到的大多是無效目標,真正該找的卻找不到。
這是LeCun認為對比學習難以支撐大規模世界模型的根本原因。
5.2.2 蒸餾方法
蒸餾方法的核心思路是:不用負樣本,而是用兩個編碼器互相配合——一個扮演學生,一個扮演老師。
代表性方法是BYOL和DINO,它們的結構是:
- 線上網路(Online):扮演學生,正常做反向傳播,帶一個額外的predictor;
- 目標網路(Target):扮演老師,不參與梯度回傳,它的權重不靠損失函數更新,而是通過EMA(指數移動平均)緩慢跟隨線上網路變化:

其中,訓練過程中的損失函數就是讓線上網路的輸出去逼近目標網路的輸出,做MSE或交叉熵。
為什麼LeCun說這種蒸餾方法中存在"你以為在最小化的代價函數,實際上並不是"這一現象?
標準最佳化理論的前提是:有一個固定的目標函數 $L(\theta)$ ,梯度下降讓它穩定地越來越小,損失曲線就是訓練健康的監測表。
但BYOL裡這個前提不成立:
1. 目標在移動:線上網路每更新一步,目標網路就通過EMA跟著悄悄挪動一點。追的目標不是一個固定的靶,而是一個一直在慢慢走的靶。換句話說,評判線上網路(目標網路)好不好的標準本身一直在變。;
2. 損失函數不等於真實最佳化目標:監控的損失 $L = ||\text{Pred}(s_\text{online}) - s_\text{target}||^2$ 反映的只是"當前這一步追得準不準",但系統整體在往那裡收斂、收斂到什麼,損失曲線完全看不出來;
3.缺乏可靠的監控訊號:損失曲線下降,不代表表徵質量在提升;損失曲線抖動,不代表訓練要崩。你根本無法從損失值判斷訓練狀態是否健康。
所以LeCun的評價很直白:"We don't like this method, but it works." 工程上能跑通,但訓練過程像個黑箱——它在做什麼,為什麼沒坍縮,理論上至今沒有完整的解釋。
5.2.3顯式正則化路線
顯式正則化路線是LeCun目前最看好的方向,核心思想是不再靠間接機制防坍塌,而是直接在數學上規定"表徵必須攜帶資訊量"。
VICReg是PLDM等端到端JEPA模型採用的防坍塌方案。它不依賴負樣本,而是直接在表徵的統計特性上施加約束。損失函數由三項組成:
$$L_{VICReg}= \underbrace{\lambda L_{inv}}{不變性}+ \underbrace{\mu L}{方差}+ \underbrace{vL$$}}_{協方差
1. Invariance(不變性):
相似的輸入,標準要相近。對同一個樣本做兩種不同增強(比如圖像的不同裁切、視訊的不同幀採樣),編碼器輸出應該相似:
$$L_{inv}= \frac 1 { n } \sum _ { i = 1 } ^ { n } {\parallel s_i -s^{'} _i \parallel^{2}}$$
這保證了表徵對無關變換(光照、裁剪、視角等)具有魯棒性,提取的是核心語義。
2. Variance(方差): 強迫表徵向量的每個維度上分散
對批次中所有樣本的表徵,逐維度計算方差(原論文字命名導致的遺留問題,實際為標準差),強制其大於一個閾值 $γ$ :
$$L_{var}= \frac 1 { d } \sum _ { j = 1 } ^ { d } max(0, γ - \sqrt{Var(s_j)+ \epsilon} )$$
如果某個維度在所有樣本上都輸出0.5,那這個維度的方差就是0,損失就會懲罰它。它強迫編碼器利用表徵向量的每一個維度去攜帶資訊,不能所有樣本擠在同一個數值上,使最終約束的是標準差 $\sqrt{Var(s_j)+ \epsilon} $ 必須 $\geq γ $ 。VICReg用它來衡量"這一維有沒有在batch內充分展開"——如果太扁(標準差 $< γ $ ),就施加懲罰。
3. Covariance(協方差):維度之間不能"串供"
計算批次表徵的協方差矩陣 $C(s)$ ,所有非對角元素的平方和:
$$L_{cov}= \sum _ { j \neq k } C(S)^2_{jk}$$
這能防止維度坍塌:即使向量整體有變化,所有資訊可能只壓縮在2-3個維度上,其他維度是冗餘的。同時,協方差懲罰強迫各維度之間儘可能"不相關"(協方差為0),每個維度獨立地攜帶不同的資訊,提高有效容量。理想情況下,最佳化完成後協方差矩陣接近對角陣:各維度獨立攜帶資訊,沒有冗餘。
VICReg在對抗表徵坍塌方面取得了不錯的效果,VICReg雖然只需要少量超參數,但在擴展到世界模型場景時(如PLDM),需要組合多個損失項,導致超參數數量增加。
SIGReg的思路是強制編碼器輸出的變數分佈成為聯合高斯分佈,從而直接約束資訊量的下界。前身VICReg已有成熟工作,但它有多個超參數,而SIGReg則是在它基礎上做了進一步精化。
而LeWorldModel使用的是 SIGReg來防止表徵坍塌。SIGReg於2025年11月首次發表在論文《LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics》,而2026年3月發表的LeWorldModel將其成功應用於端到端世界模型的訓練,核心思想非常簡潔:強迫潛在嵌入的分佈匹配一個各向同性高斯分佈 $N(0,I)$ 。
這裡為什麼選擇高斯分佈?
2026年5月,由David Klindt, Yann LeCun等人發表的一項理論工作《When Does LeJEPA Learn a World Model?》證明:在潛在變數服從平穩、加性噪聲轉移的一類世界中,LeJEPA(alignment + 各向同性高斯正則化)能且僅能在潛在分佈為高斯時,從非線性觀測中線性恢復(up to rotation)世界的真實潛在變數——這一性質稱為線性可識別性。該結論具有'if and only if'的嚴格性:正向通過譜分解證明非線性成分被嚴格懲罰,逆向則排除所有非高斯分佈。正是這種線性可識別性,保證了隱空間規劃與真實空間規劃的最優等價性。
SIGReg的具體做法利用了Cramér-Wold定理:一個多元分佈是高斯分佈,當且僅當它在所有一維隨機投影下都是高斯分佈。換句話說:如果你有一個 $M$ 維分佈,你把它往所有可能方向上投影,如果每一個投影都是一維高斯,那麼這個 $M$ 維分佈本身就是多元高斯。具體實現分三步:
1. 隨機投影:將一個批次內的表徵向量 $Z\in R^{N \times B \times d}$ ,隨機採樣個方向向量 $u^m$ ,計算一維投影$h^m=Z \cdot u^m$ ;可以把 $Z\in R^{N \times B \times d}$ 理解成"從當前訓練批次裡撈出來的所有潛在向量,其中 $N$ 表示歷史長度, $B$ 表示batch size,代表每個表徵向量的維度。把高維表徵 $Z\in R^{N \times B \times d}$ 投影到方向 $u^m$ 上,就得到一個一維序列 $h^m$ 。現在問題回到了經典統計的舒適區:檢驗這一串一維數字是不是服從高斯分佈。
2.正態性檢驗:對每個投影 $h^m$ ,計算Epps-Pulley統計量——衡量該一維分佈偏離高斯分佈的程度;Epps-Pulley檢驗是一種基於特徵函數的正態性檢驗,對偏離正態(尤其是厚尾、多峰)很敏感。SIGReg把它當成損失函數:如果投影后的分佈不像高斯,就產生懲罰。
3.聚合懲罰:對所有投影的檢驗統計量取平均,作為正則化損失加到總目標裡。
$$L_{total}= \underbrace{\parallel \widehat{Z}{t+1}-Z} \parallel^{2}{預測損失}+ \underbrace{ \lambda·SIGReg(Z)} $$
LeWorldModel之前,端到端JEPA世界模型(如PLDM)需要六個可調損失超參數的組合(VICReg的多項正則化 + EMA + 各種技巧)。而LeWorldModel把這一切壓縮成了兩個損失項、一個超參數$λ$ ,並且能在單張GPU上幾小時內從原始像素穩定訓練。
一句話總結:LeWorldModel用SIGReg把"防坍塌"從工程啟髮式(EMA、stop-gradient、多loss調參)轉化成了一個數學上更乾淨的分佈匹配問題。
5.3 表徵坍縮的更大意義
表徵坍縮不僅僅是一個技術細節,它暴露了自監督學習的一個深層困境:當監督訊號僅內生於資料本身,模型天然傾向於選擇最省力的路徑——將所有輸入壓縮為無資訊的常數或近乎相似的分佈,因為這在局部損失層面往往已是最優解。
對比學習、蒸餾方法與顯式正則化,本質上是三種阻止表徵失去區分度(表徵資訊量趨近於零)的約束範式:它們分別借助樣本間的排斥力、非對稱架構的隱式動力學,以及直接對分佈幾何的硬約束,來強製表征空間保持豐富的幾何結構。
三者殊途同歸,背後共享同一個元問題:如何讓神經網路習得資訊豐富、幾何分明且支援因果推演的潛在狀態,而非退化為毫無區分度的表徵?
這一問題的回答質量,將直接決定JEPA路線能否從視覺預訓練穩定擴展到端到端世界模型的建構,並具備真正的工程可擴展性與理論穩定性。
六、LLM的不安全性與目標驅動AI的出路
前五節的分析,基本回答了一個問題:LLM為什麼無法通向通用智能。從下一token預測的侷限,到VLA在物理世界的失敗,再到JEPA試圖在抽象表徵空間重建世界模型——這條線索的終點,引出了一個更根本的追問:即便我們造出了一個真正能理解世界的智能體,我們能保證它做正確的事嗎?
這正是LeCun在訪談中反覆強調安全問題的起點。他的論斷並非孤立的個人判斷——近年來從ICLR、ICML到NeurIPS,大量頂會研究從不同角度印證了同一結論:LLM的不安全性不是工程細節缺陷,而是架構層面缺乏硬約束的必然結果,無法在當前範式內根本修復。 而他提出的目標驅動AI範式,正是試圖在架構層面給出答案——把安全約束從事後對齊變成系統的內生目標。
目標驅動AI範式與前文討論的JEPA之間存在內在關聯:JEPA的代價函數(功能等同於損失函數)已經體現了目標驅動的雛形——以期望表徵狀態而非像素重建作為學習目標,將"目標"內嵌入表徵學習本身,但這只是表徵層面的目標驅動;目標驅動AI範式的完整含義,是將這種約束進一步延伸內嵌到行動規劃層——系統不僅要預測世界,還要在明確的目標與安全約束下選擇行動。兩者的共同點在於:都以最小化明確目標函數來驅動系統行為,而非依賴外部監督訊號的事後糾正。
6.1 LLM本質上不安全
Yann LeCun對大語言模型的安全性問題做出了極其明確的判斷——“我要說一些可能再次引起爭議的話。但我認為大語言模型本質上是不安全的。我認為它們無法變得可靠和安全。”
這個論斷是基於兩個相互關聯的原因:不可靠性和不可預測性。
第一,無法阻止幻覺。
LLM會“無法變得可靠,因為你無法阻止它們幻覺”。
這並非偶發的工程缺陷,而是自回歸生成架構的內在屬性:模型在每一時刻都只是在預測“可能的下一個詞元”,不存在任何內建的驗證機制來檢查生成內容是否與事實一致。北京通用人工智慧研究院在分析VLA模型當前痛點時,明確指出VLA“模型缺乏真實物理世界常識,生成與決策不符合物理規律”,這正是LLM架構將物理世界的連續高維問題降維為離散符號預測問題的必然代價。
第二,智能體行動時無法預測後果。如果LLM被賦予智能體能力(即能夠呼叫工具、執行程式碼、控制物理裝置),那麼:“你無法保證它們不會採取一個它們沒有預測到後果的行動”。這個風險在LLM的架構層面無法消除,因為LLM本身不具備模擬和評估行動後果的機制,它只是預測下一個token,而不是模擬物理世界中的因果鏈條。
而訓練誤差和測試誤差之間存在差距,總會有某個提示讓系統做出非常離譜的事。換句話說,無論你在訓練資料上做多少對齊、多少過濾,總存在分佈外的提示(Prompt)能夠觸發系統的危險行為。這不是“再訓練一次”就能解決的,這是分佈外泛化能力的數學極限。
LeCun舉了一個具體而令人警醒的例子,發生在LLM相對最可靠的領域,比如code:code是你可以實際驗證生成程式碼是否滿足規範的東西。但不是所有事情都是code,而且有code智能體抹掉你硬碟的例子,對吧?或者做些奇怪的操作,讓你損失很多資料等等。
編碼領域的LLM之所以相對可靠,是因為存在外部的驗證機制,我們可以運行程式碼、檢查輸出、進行單元測試。但這種驗證是外掛的、後驗的,不是模型內生的一部分。一旦模型被賦予自動執行程式碼的權限,就沒有人在中間檢查。抹掉硬碟的例子不是理論推演,而是已經發生的真實案例。
LLM的不安全性在語言領域已難以根治,而當它被遷移到VLA這類具身架構時,問題被進一步激化。VLA繼承了LLM的所有缺陷,卻要在物理世界中承擔後果——語言模型輸出錯誤,使用者可以重試;機器人輸出錯誤動作,代價可能不可撤回。
模型天然偏向”捷徑學習“——依賴訓練分佈內的視覺模式做決策,而非真正理解指令語義與動作因果。這意味著對齊與安全約束在物理執行層面存在結構性漏洞:約束是在語言空間施加的,但失效是在物理空間發生的。
為什麼RLHF和安全微調無法解決這個問題?
LeCun說得很清楚:訓練誤差和測試誤差之間存在差距。總會有某個提示讓系統做出非常離譜的事。
換言之,所有的RLHF、憲法AI、紅隊測試,本質上都是在訓練資料上壓低危險輸出出現的機率。它們是機率性的安全措施,而非確定性的安全保證。由於LLM在推理時不存在任何從架構層面保證安全的機制,在分佈外輸入面前,已訓練的機率分佈無法覆蓋所有可能場景,系統總有辦法”逃逸“。
已有風險案例:從編碼智能體到倫理對齊的侷限
其實編碼智能體抹掉硬碟的案例並非孤例。在具身智能領域,VLA模型面臨的倫理對齊挑戰更加棘手。中國科學技術大學等團隊的研究發現,當指令中存在“無關的上下文資訊”時(比如“把桌上那個紅色的咖啡杯拿過來,雖然今天是周三,天氣很好”),VLA模型會同時受到主指令和無關資訊的干擾,暴露出在安全性和效率方面的嚴重缺陷。
因果理解層面的研究進一步揭示了問題的根源:VLA模型的注意力機制往往過度啟動在任務無關的區域(如背景),而非真正影響決策的物體和互動區域;更有甚者,即使將視覺輸入完全遮蓋,模型的輸出行為依然遵循類似的趨勢。這說明VLA模型“可能依賴於記憶任務與動作之間的統計對應,而非學習底層的因果機制”,它不知道自己在做什麼,只是機械地復現訓練資料中的關聯模式。
LeCun用一句話總結——當前形式的大語言模型本質上是不安全的,因為它們無法預測其行動後果,而且它們完成任務的方式取決於它們的訓練。你給它們一個提示,然後它們會完成一個與該提示對應的任務,但僅限其訓練所允許的範圍內。但沒有硬連線約束會迫使它們完成這個任務,然後預測任務會被正確完成。
這句話點出了LLM安全困境的核心:沒有硬性約束。所有對齊手段(RLHF、憲法AI、紅隊測試)都是事後施加的軟約束,可以在訓練中被覆蓋、在推理中被”越獄”。而真正的安全需要一個從架構層面就無法違反的硬約束。
6.2 目標驅動AI:從內生安全到可控智能體
針對LLM的不安全性,LeCun提出了一個替代架構,他稱之為目標驅動AI。這個架構的核心思想是:系統的行為不是通過“預測下一個詞元”來驅動的,而是通過“尋找能夠滿足目標的行動序列”來驅動的。
LeCun的角度,基本上你給AI系統一個目標:完成這個任務。系統怎麼知道它會完成這個任務?有一個世界模型,它預測一系列它想像要採取的行動的結果。如果這個結果滿足一個代價函數——該函數描述了任務在多大程度上被完成或未被完成,那麼如果該系統的工作方式是通過最佳化,找到一系列能完成該任務、根據其模型最小化該代價的行動,那麼它就只能做這些,別無選擇。
“別無選擇”意味著架構層面的行為約束,而不是後驗的過濾或對齊。系統的輸出不是從機率分佈中採樣出來的“可能合理的下一個token”,而是通過最佳化過程找到的“能夠最小化代價函數的行動序列”。如果最佳化是精確的,那麼系統的行為就被硬性地鎖定在滿足目標的軌跡上。
更重要的是,安全約束可以內嵌為目標函數的一部分,與任務目標並列。LeCun指出——現在你可以加入到該系統中的,不僅僅是保證任務完成的代價函數,你還可以加入一堆其他目標函數、其他代價函數,甚至是安全約束——比如‘不要傷害任何人’。你無法在抽象層面指定這個,但你可以有一些低層目標函數,組合在一起能保證系統不會危險。而且系統從構造上就無法違反這些東西。它必須滿足那些條件。
這個設計的精髓在於“從構造上就無法違反” 。安全不是靠“訓練之後祈禱它不要做壞事”來實現的,而是靠“在行動之前,規劃過程就已經排除了所有違反安全約束的行動”來實現的。系統在生成任何輸出之前,就已經用世界模型模擬了每個可能行動序列的後果,並丟棄了那些會違反安全約束的選項。
與現有對齊方案的本質區別:事前規劃 vs. 事後約束
RLHF、憲法AI等現有對齊方案屬於“事後約束”:
- 訓練階段已有行為被調整機率分佈,危險輸出的機率降低,但從未歸零
- 推理階段可被紅隊攻擊利用,未知提示觸發“訓練-測試”間隙中的危險模式
- 無內生驗證,模型無法在行動前自問“我這樣做會違反安全約束嗎?”
目標驅動AI則是“事前規劃”:
- 行動前用世界模型模擬所有可能行動序列的結果
- 最佳化過程直接篩除違反安全約束的行動
- 如果不存在滿足目標和約束的行動,系統不行動或請求人類介入
CVPR 2026的最佳論文提名工作《See, Plan, Rewind》恰好演示了這一理念:研究者將任務分解為細粒度空間子任務規劃,在執行過程中持續監控進度,一旦檢測到偏離預期就自動回溯——“進度驅動的異常檢測與回溯”本質上就是LeCun所說的“用世界模型預測後果”的工程化實現:系統不再盲目預測下一個動作,而是持續問“我現在離目標還有多遠?如果這樣繼續做下去會出問題嗎?”。
目標驅動AI的失敗模式
當然,LeCun也坦誠地承認,這個架構並非萬無一失。失敗模式仍然存在。特別是,代價函數可能不精準。你以為代價函數在衡量任務完成程度,但也許它並不精準。世界模型可能不精準。所以系統做出的預測實際上並不正確。
如果代價函數設計錯了,系統會“高效地”完成錯誤的目標;如果世界模型不精準,系統對行動後果的預測就會出錯,仍然可能造成危害。
但關鍵在於,這些失敗模式是可偵錯、可驗證的——你可以檢查代價函數是否精準,你可以測試世界模型的預測誤差。相比之下,LLM的幻覺和不可預測性是一個“黑箱”,你無法定位錯誤來源,也無法保證修復後不會在其他地方出現新的問題。
兩種範式的根本差異
LeCun最後將LLM與目標驅動AI做了一個對比:
“大語言模型則不然。大語言模型總能逃逸。訓練誤差和測試誤差之間存在差距。總會有某個提示讓系統做出非常愚蠢的事。”
這個對比點出了兩條技術路線的根本分歧:
目標驅動AI的路還很長,我們需要解決世界模型的精度、代價函數的設計、最佳化的效率等問題,但它提供了一個LLM完全缺失的東西:一個可驗證的安全性框架。這個框架的核心承諾是:如果世界模型足夠精確,代價函數設計正確,那麼系統就不可能做出違反約束的行為。這不是機率上的“不太可能”,而是架構上的“不可能”。
七、Tapestry與主權AI:開源生態的反擊
前面我們討論了LLM自身架構帶來的安全隱患,但還有一類更容易被忽視的風險——它不來自技術本身,而來自誰在控制這項技術。這正是近來討論熱度持續上升的"主權AI"問題。LeCun在比較開源與閉源模型時,將這一問題推向了一個具體的切口:當全球使用者的資訊獲取都經由少數幾個AI系統過濾,資訊背後的價值觀與立場便不再中立。接下來我們將從這裡展開,看"主權AI"的問題究竟根植於何處。
7.1 資訊攝入的政治問題
LeCun提出了一個少有人關注的隱憂:未來人們獲取資訊將越來越依賴AI助手,而這些助手幾乎都誕生於美國或中國——對於其他地方的使用者來說,這意味著自己看世界的"窗口",從一開始就是按別人的眼光裁出來的。
這個判斷基於一個顯而易見的趨勢:AI助手正在替代傳統搜尋引擎,成為人們獲取資訊的主要入口。LeCun進一步描述了這一前景——如果Meta等公司推動的智能眼鏡等裝置普及,"基本上你就會通過智能眼鏡或某種智能裝置,用語音與你的AI助手交談。所以你所有的資訊攝入都將由AI助手來間接處理,這些資料會成為'資訊食譜'。"
這裡的"資訊食譜"(information diet)一詞值得留意。它暗示了一個比"搜尋偏見"更根本的問題:不是AI助手偶爾給你推送帶有偏見的內容,而是你觸達世界的所有資訊都先經它過濾一遍。如果這個過濾器是在矽谷或中國訓練出來的,那麼全球使用者的認知底色,都會悄悄染上訓練者的價值觀。LeCun列出了三個具體層面的不匹配:
- 語言層面:低資源語言在公開網際網路訓練資料中天然不足,模型對這些語言的處理能力遠弱於英語和中文。
- 文化層面:可能有一種文化,不被矽谷和中國的人所理解,在公開可用的網際網路訓練資料中也沒有得到很好的代表。
- 價值與政治層面:你幾乎肯定會有政治觀點,完全不被你能從美國西海岸科技公司或中國公司獲得的少數AI助手所代表。
這本質上是一個認知主權問題。LeCun用了一個很直白的表述,世界上有許多國家都渴望在人工智慧領域擁有一定程度的主權。這不僅關乎其產業發展,更關乎本國公民。它們不希望本國公民被中國或美國開發的模型所“洗腦”。
"洗腦"這個詞很重,但LeCun用它來描述一個結構性的資訊不對稱:當所有資訊都經同一個AI助手過濾時,這個助手的訓練資料和價值取向就在實質上塑造了使用者的世界觀。
值得一提的是,這個話題並非LeCun首次提出,印度、法國、韓國、日本等多個國家已在推動"主權AI"議程,由政府或本土機構投資建設自有基礎模型,確保關鍵基礎設施不受外部控制。但LeCun的獨特之處在於,他給出了一個具體的工程方案來回應這個政治訴求。
7.2 Tapestry的技術方案:聯邦式全球訓練
LeCun認為,Tapestry可能提供一種兼顧資料主權與全球協作訓練的方案,它是一種聯邦學習架構,但比傳統聯邦學習更精妙:你將擁有來自全球的貢獻者共同參與訓練一個全球性模型,該模型本質上將成為匯聚世界所有知識與文化的寶庫。這些貢獻者將提供資料和計算資源,但會保留對其資料的控制權,無需與其他貢獻者共享原始資料。
關鍵點在於貢獻者共享的是參數向量,而不是資料本身。
具體的機制是各參與方的資料中心從"全域共識模型"獲取當前參數向量,在本地資料上訓練後更新參數,然後通過一個中央伺服器(或點對點協議)與其他貢獻者交換參數向量。每次更新時,本地模型既要擬合本地資料,也要保持與全域共識向量的接近,從而使所有參數向量在訓練過程中收斂到一個"好像在世界所有資料上訓練出來"的共識模型。
可以把它理解為所有貢獻者參數向量的平均值。各方定期通過某個中央伺服器互相通告:"這是我的參數向量,你的是什麼?"
不過該方案目前仍處於概念驗證階段, 其通訊效率、激勵機制以及跨機構協同成本仍有待驗證。
背景補充:傳統聯邦學習(Federated Learning)由Google在2016年提出,主要用於在手機等邊緣裝置上訓練模型而不上傳使用者資料。Tapestry把這一思路提升到了國家/機構層面——不是保護個人隱私,而是保護資料主權。這一想法的突破性在於:它將"不共享資料"從一種妥協("我的資料不給你")變成了一種優勢("我們各自的私域資料合起來,能訓出比任何單一方更強的模型")。
7.3 平台開源化的歷史規律
LeCun用Sun Microsystems的類比來論證這件事為什麼會發生。想想1996年網際網路基礎設施的大玩家是誰。Sun Microsystems、HP、Dell。所有這一切都被Linux徹底淘汰了。整個網際網路都運行在Linux上。就連Azure也運行Linux。所以,今天的OpenAI、Anthropic等等,就是昨天的Sun Microsystems和HP-UX。
這個類比的邏輯鏈條是這樣的:
- 1990年代中後期,Sun Microsystems靠Solaris+專有硬體賣伺服器,HP靠HP-UX,Dell靠Windows NT。它們都聲稱自己的閉源Unix比Windows更可靠、更適合Web伺服器。
- 但Linux以開源、免費、可自由定製的優勢,從邊緣場景逐步滲透,最終吃掉了整個網際網路基礎設施層。今天,即使是微軟的Azure,底層跑的大多數也是Linux。
LeCun的推論是:當AI(特別是基礎模型層)走向基礎設施時,同樣的規律會重演。閉源模型的護城河(先發優勢、資料規模、工程積累)在平台級競爭中可能並不如看起來那麼堅固。
這個判斷有幾個隱含前提:第一,基礎模型本身正在成為類似作業系統的基礎設施層,不是誰都自己訓練,但誰都需要用;第二,基礎設施層天然需要可定製性、可審計性和低成本擴散能力,這三點開源生態有結構性優勢;第三,閉源模型的縮放收益並非無限。LeCun明確指出當閉源方不得不依賴合成資料或版權資料來繼續推進時,開源方只要解決資料接入的機制問題(這正是Tapestry要做的),就能在資料規模和質量上實現反超。
7.4 開放原始碼的結構性優勢
還有一個容易被忽略的判斷,直接關係到開源生態能否後來居上。如前所述,公開文字資料已近枯竭,閉源公司的應對方式是轉向版權授權和合成資料——但這兩條路對開源生態並不平等:
- 版權資料需要高額授權費用,中小開放原始碼專案難以負擔;
- 合成資料則有隱患,用模型生成的內容反覆訓練,輸出質量會一代代衰減。
這意味著資料瓶頸對閉源和開放原始碼的衝擊並不對稱,反而可能進一步拉大兩者之間的差距。
相比之下,Tapestry設計的優勢在於:它將大量目前未被納入任何模型的私域資料(印度的地方語言文字、日本的學術文獻、歐洲的政務文件、東南亞的文化內容),通過不共享原始資料的聯邦機制納入了模型訓練。這些資料在當前的集中式訓練範式下根本不可用(因為資料持有方不願意交出),但在Tapestry架構下,它們可以參與訓練而不離開本地。
這是一個微妙但重要的工程判斷:開源社區如果在資料接入機制上創新,可能比閉源方擁有更大的資料探勘空間,因為開源社區能訪問的資料池,是閉源方用錢買不到的那部分。
八、多層分工的系統:未來更可能的系統圖景
到這裡,前面所有的分析其實都在收斂向同一個結論:LLM不會消失,但它註定不是終點。真正的問題從來不是"LLM夠不夠強",而是它被放在了一個錯誤的位置上——人們試圖用一個語言預測器來承擔感知、規劃、決策的全部工作。LeCun的答案是分工:讓LLM做它真正擅長的事,把理解物理世界和規劃行動的任務交給世界模型。這不是對LLM的否定,而是一次“降職”與“解放“。
8.1 LLM不會消失,但會退回到它的天然位置
LeCun對LLM的定位,既不是"終結者",也不是"過渡品"——大語言模型仍會有一席之地,基本上就是作為"語言介面"。
這句話容易引起誤解。它不是說LLM不重要("語言介面"的價值並不小),而是說LLM在智能系統整體架構中的功能範圍是有邊界的。LeCun的完整判斷可以這樣理解:LLM會長期作為"語言皮層"存在,負責輸入輸出、知識檢索和語言操作,但不再承擔核心決策任務。
那麼LLM真正擅長的邊界在那裡?
LeCun給出了一個精準的界定:大語言模型在語言本身就是推理基底的領域表現特別出色——除了數學、程式碼還有寫作、翻譯等。換句話說,只要任務可以在語言空間內被完整描述和解決,LLM就是強大的工具。
但這也正是邊界所在。LeCun用了一個直接的比喻:大語言模型是好的程式設計師,卻不是軟體架構師;是解題者,不是設計者。這個區分不只是精度問題,而是能力類型的問題——軟體架構需要理解系統在現實中的約束、權衡和演化路徑,這些都不是語言模式匹配能覆蓋的。
8.2 為什麼LLM會被”降職“?
LeCun的另一個核心判斷是:智能系統的核心是"思考"能力(預測、規劃、推理),而"說話"(語言互動)是第二位的。 這一判斷的依據在第2小節中已有詳細分析,這裡不再重複,只聚焦於它最直接的推論:LLM為什麼無法承擔規劃任務。
為什麼不能在詞元空間裡完成規劃?
LeCun在訪談中給出了一個清晰的解釋——"我在JEPA中談的是,你不是在詞元空間裡做這件事,而是在抽象思維空間裡做。"
當前LLM在數學和程式碼上展現的"規劃"——用搜尋、驗證和回溯找到正確的token序列——確實是有效的。但LeCun指出,這不是一種高效的規劃方式,而且只在能於token空間執行搜尋的領域才成立。
一旦進入物理世界,問題就變了:行動空間是連續、高維且不可列舉的,token搜尋徹底失效。這就好比用字典查一個從未被記錄過的聲音——工具本身的結構決定了它覆蓋不到這裡。抽象表徵空間的搜尋不依賴離散符號的可列舉性,這是兩種規劃方式的本質差異。
8.3 三層架構:一個可能的系統藍圖
既然LLM有其邊界,世界模型尚未成熟,那麼一個現實的問題就浮出水面:兩者能否協作,而不是互相取代?綜合LeCun在訪談中的論述,未來AI系統最可能的形態不是"LLM或世界模型"的二選一,而是一個三層分工架構:
第一層:LLM層(語言與知識層)
這是系統與外界的介面。負責自然語言理解與生成、知識檢索與呼叫、任務分解與指令解析,以及在"語言即推理基底"的特定領域(程式碼、數學、法律文書)中直接完成形式化推理。這層不做規劃,但它是人與系統之間摩擦最低的互動介面。
第二層:世界模型層(理解與規劃層)
這是系統的"思考引擎"。基於 JEPA 架構,在抽象表徵空間(而非像素空間或詞元空間)中對物理世界建模。它的核心能力是 LeCun 定義的兩個"LLM 缺失的能力":預測行動後果,以及基於搜尋的多步規劃。
第三層:統一決策層(目標驅動層)
接收 LLM 層解析出的使用者目標,將其翻譯為世界模型層可執行的規劃任務(代價函數+約束條件),在世界模型層完成搜尋最佳化後,將執行結果回流給 LLM 層進行自然語言溝通。同時維護全域的代價函數和安全約束,也就是LeCun所說的"目標驅動AI"(Objective-Driven AI)。安全不是靠外部約束過濾,而是"從構造上就無法違反"的內生約束。
這三層的關係類似於:語言皮層 → 前額葉 → 運動系統。LLM負責"聽懂"和"說清",世界模型負責"想清楚"和"預測後果",決策層負責"保證不越界"。
8.4 兩者如何分工?
三層架構說清楚了"誰做什麼",但還有一個更深的問題:LLM和世界模型為什麼天然適合不同的任務? 這背後有一個認知科學上的對應關係。
兩類系統的分工可以對應到兩種不同的智能模式:
- 系統一:(快速、本能、模式匹配) → LLM的優勢區間:給定上下文,快速輸出最合理的響應,不涉及行動後果預測,純模式補全。
- 系統二(緩慢、深思、後果模擬) → 世界模型的優勢區間:在行動前模擬多種可能的後果,通過搜尋和最佳化找到最優路徑。
在LeCun的框架中,兩種模式各有其位置:系統一負責效率,大部分日常語言互動不需要深度規劃;系統二負責可靠性和泛化,當系統需要在從未見過的場景中做出穩定決策時,必須走這條路。
至此,我們從三層架構分工走回到了最初的問題:LLM究竟是什麼?它不是終點,也不是過渡品,而是一個在正確位置上不可或缺的元件。LeCun的整個論述,其實是在給LLM重新定位,而不是判它出局——這個區別,正是理解他所有觀點的”鑰匙“。而人類智能的關鍵特徵之一,也是能在兩種模式之間按需切換,而當前的LLM只有系統一,沒有系統二。
8.5 何時會發生範式轉變?
理想架構的方向或許清晰了,但有一個更現實的問題:這一切什麼時候會真正發生?LeCun在訪談中給出了一個罕見的具體判斷——對"需要範式轉變"的認識,正在當下悄然形成,而到2027年初,這一點將對所有人變得不言而喻。
但他也補充了關鍵的限定:"這不意味著到那時我們就會有解決方案。"認知的轉變和技術方案的成熟是兩件事。前者可能在2027年前後完成,後者需要更長時間。
這裡有兩個可以觀測的訊號指標:第一,LLM 在非語言域(機器人、工業控制、醫療動態)的規模化嘗試是否持續遭遇泛化瓶頸。如果VLA路線確實如LeCun所判斷的那樣"走不通",這將是推動範式轉變認知的最大動力。第二,JEPA/世界模型在小規模但複雜場景中的規劃演示能否被覆現和規模化。LeCun在訪談中透露的時間表是"一年到一年半內"有初步的工業場景演示。
值得留意的是,這個雙系統圖景並不意味著到時會出現一個"完美的通用世界模型"。更可能的路徑是:先在受限域(如特定工業過程控制、特定醫療場景、特定機器人操作)中訓練域內世界模型並驗證規劃的可靠性,然後逐步擴展域的覆蓋範圍。這是一個漸進的技術演化,而不是一次性的"GPT時刻"。
結語
如果用一句話總結LeCun的核心論點:智能不是關於預測下一個token,而是關於預測行動的後果。
LLM之所以強大,是因為語言這個特殊介質恰好讓"下一token預測"成為了通往知識和推理的捷徑。但語言之外的真實世界——機器人、工業系統、醫療動態——是連續的、高維的、不確定的,在那裡這條捷徑不再通行。
我們更傾向於認為,未來不會是“LLM取代世界模型”或“世界模型取代LLM”,而是語言模型負責知識表達與互動,世界模型負責預測與規劃,強化學習與搜尋負責決策最佳化。真正的智能系統,可能來自這些技術路線的融合,而非某一路線的單獨勝出。
範式轉變的認知,已經在路上了。 (Datawhale)