
"過去十年,半導體行業靠堆電晶體贏得市場。下一個十年,靠什麼?靠把熱量帶走的能力。"
這句話放在兩年前,會被當作危言聳聽。但在剛剛結束的Computex 2026上,三星、SK海力士、美光同時亮出各自的散熱技術牌,這個行業的答案已經不言而喻。
為什麼現在?為什麼是HBM5?
🔵 聚焦:數字會說話
一個具體的坐標:NVIDIA B200 GPU單顆功耗已達1000W TDP,相比H100的700W增幅43%。而根據行業路線圖預測,到2035年GPU單晶片功耗將突破1200W,若配合32顆HBM堆疊(每顆180W),單模組總功耗可達15,360W。這已經不是散熱問題,這是熱核威脅。
HBM5每顆堆疊的功耗預計將接近100W,這在HBM3E時代根本是無法想像的數字。問題的根源在於物理規律:隨著HBM代際演進,疊層介面(D2D PHY層)的功率密度和溫度呈指數級攀升,而傳統封裝工藝中熱量只能通過DRAM核心晶粒向外傳導,這條路越走越窄。
隨著AI晶片領導者NVIDIA和AMD持續施壓,HBM供應商必須在散熱控制和低功耗設計能力上取得突破。這不是供應商的自主選擇,而是下遊客戶的主動倒逼。當NVIDIA決定下一代產品的供應商資格時,散熱規格已與頻寬、容量同等重要。
隨著HBM從HBM3E邁向HBM4E和HBM5,堆疊層數可能接近20層,熱管理正在成為性能與可擴展性的關鍵約束。層數越多,核心溫度越難逸散,物理規律無法被商業意志繞開。
三家巨頭,三條路徑
🟡 洞察:技術分歧背後是戰略博弈
表面上,三星、SK海力士、美光分別選擇了不同技術路線。但如果你認為這只是工程師的技術偏好,那就錯了。技術路徑的選擇,本質上是供應鏈話語權和客戶繫結策略的體現。誰能讓客戶"無需重新設計就能採用",誰就掌握了遷移成本這張牌。
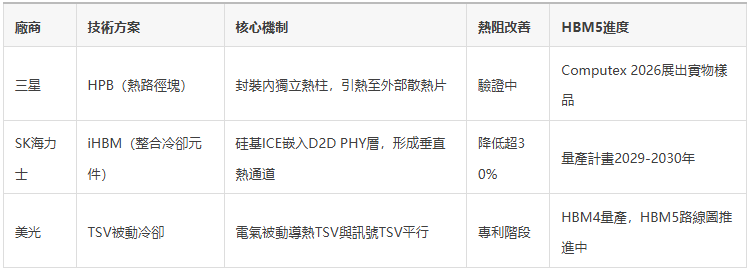
三星:熱路徑塊(HPB)
HPB在HBM封裝內建構獨立的熱柱陣列,將堆疊內部的熱量引出,傳遞至封裝上方或側面的散熱片,而不是被迫讓熱量通過DRAM核心晶粒向外擴散。通俗講,這相當於在晶片內部專門打通"煙囪",讓熱量有專屬通道逃離。
三星已完成HPB技術在第七代HBM4E產品上的實施與驗證,首批樣品於5月29日發貨給客戶,並計畫在HBM5上全面部署。早在今年1月,三星就已在其Exynos 2600處理器上率先部署HPB技術,在應用處理器晶片頂部安裝銅基HPB結構,這說明這不是PPT上的概念,而是經過量產驗證的工程成果。
三星還確認HBM5基礎晶粒將採用自家2nm工藝製造,相比HBM4和HBM4E使用的4nm製程實現跨代升級。製程節點的躍升直接影響功耗,這與HPB散熱技術形成協同,是系統級的降溫策略。
SK海力士:iHBM整合冷卻
SK海力士於5月26日發佈iHBM冷卻技術,將整合冷卻元件(ICE)直接嵌入HBM堆疊,在晶片內部建構專用垂直熱通道。這種基於矽材料的結構使熱量能夠通過疊層晶粒間的物理層散逸,有效充當儲存堆疊內部的熱煙囪。
關鍵資料:與傳統設計相比,該技術將熱阻降低超過30%。這個數字不是實驗室理論值,而是基於已量產封裝工藝測試得出的結果。SK海力士表示該技術基於已在量產中驗證的封裝工藝,允許客戶無需重大設計改動即可採用,這一點對NVIDIA和雲廠商而言至關重要——系統整合成本越低,採購決策越快。
SK海力士當前在全球HBM市場佔據約62%的出貨量份額(截至2025年第二季度),客戶涵蓋NVIDIA、Google、亞馬遜等主要AI基礎設施廠商。在2026年第一季度財報電話會議上,該公司表示未來三年客戶對HBM的需求已超過其產能。市場地位如此,iHBM的戰略意義不僅是技術突破,更是維持壁壘的護城河。
美光:TSV被動冷卻
美光2025年美國專利描述了一種基於電氣被動冷卻TSV的垂直熱管理結構:導熱層嵌入基礎介面晶粒中,TSV從中延伸穿過整個儲存堆疊至頂部熱移除層,這些TSV僅作為導熱通道,與訊號TSV在同一封裝佔地內平行排列,形成低阻抗的垂直熱通路。
美光的路徑不同於前兩者的"加結構"思路,而是從低功耗架構出發,通過改進TSV電氣設計來從根源降低熱生成,再輔以被動散熱路徑帶走餘熱。
市場格局:需求早已超過供給
🟢 資料支撐:這不是未來故事,是當下現實
2026年全球生產的記憶體晶片中,高達70%將被AI資料中心消耗。HBM目前佔總DRAM晶圓產能的23%,而兩年前這一數字還處於個位數。一個垂直細分市場,在兩年內完成了從邊緣產品到主流產能核心的蛻變。
美光2026年HBM產能已全部售罄,並將HBM市場規模預測上調至2028年達到1000億美元。這不是分析師的樂觀估計,而是已簽合同的採購承諾所支撐的數字。
就HBM5量產時間節點而言,三星的計畫約在2028年,SK海力士則定在2029至2030年,晚於三星約一年。這一差距或將成為下一輪市場份額重新洗牌的契機:三星HBM市場份額目前約為17%至22%,而SK海力士保持57%至62%,但誰能率先通過NVIDIA的熱管理驗證,誰就能率先拿到下一代AI加速器的供貨訂單。
被忽視的真正戰場:封裝熱密度的系統級代價
🔴 警示:多數人只看到晶片,忽視了機房
當單顆GPU功耗突破1000W,當每顆HBM堆疊逼近100W,問題不再侷限於封裝層面。它會以資料中心建設成本的形式反彈到決策者的財務報表上。
一個量化的視角:將PUE從1.45降低至1.15,在一個擁有1000顆H100 GPU的叢集中(電價0.12美元/度),每月可節省約32,700美元的電力成本,36個月累計節省約118萬美元,而這還是在H100時代的功耗水平下計算的。B200時代這個數字只會更大。
2026年,隨著晶片功率密度持續攀升,液冷已從專業化解決方案轉變為AI資料中心的主流需求。這意味著每一座新建的AI資料中心,都必須在設計階段就將液冷基礎設施納入預算,而不是在上架後臨時打補丁。
HBM5的封裝級散熱創新,本質上是將這部分壓力從資料中心建設端前移至晶片設計端。如果三星或SK海力士的方案能讓系統熱阻降低30%以上,那麼整個機櫃的液冷系統可以降一個規格,資料中心開發商的TCO(總擁有成本)會在10億美元量級的項目中產生數千萬美元的差異。
這才是雲廠商真正在乎的事。
一個多數人沒想過的角度
🔵 洞見:散熱能力將成為AI供應鏈的隱性壁壘
我們通常把算力說成是AI競爭的核心變數。但如果散熱技術的差異最終決定了誰能進入NVIDIA的供貨名單,那麼掌握熱管理專利和量產能力的記憶體廠商,實際上擁有了一種極少被討論的"AI基礎設施定價權"。當散熱成為稀缺能力,它就不再只是工程問題,而是商業槓桿。
從更長的時間軸看,路線圖預測HBM8將於2038年面世,每顆堆疊記憶體高達240GB、功耗180W,若配合未來GPU的32顆堆疊方案,單模組總功耗可達15,360W。到那時,誰能在包裝層面優先解決熱通道問題,誰就能在Computex 2038上重複今天三星和SK海力士的故事。
歷史總是在重演,只是功耗的小數點向右移了一位。
2026年,科技巨頭在AI資料中心的投入預計達到6500億美元。在這個量級的資本浪潮中,那些能夠提供"更涼快的算力"的供應商,不需要擔心需求。他們只需要確保自己的工藝跑得比熱量快。 (芯在說)