
2026年過半,全球伺服器記憶體市場的價格曲線幾乎是垂直向上的。DDR5伺服器記憶體合約價在過去兩個季度裡翻倍不止,AI叢集的採購部門天天在跟供應商搶貨。就在這個節骨眼上,Marvell把一個說了很多年、卻一直停留在PPT裡的技術方案,真正做成了量產晶片:在CXL控製器裡塞進硬體壓縮引擎,讓每一顆DRAM顆粒都能"膨脹"出更多有效容量。
這套方案叫Structera,分為X和A兩條產品線。它解決的不是"造更多記憶體"的問題,而是"讓現有記憶體裝下更多資料"的問題。這是兩種完全不同的思路,後者在當下的供給緊張周期裡,反而更現實。
聚焦
Structera不是簡單的記憶體擴展卡,它的核心是一顆叫CDB(Compression-Decompression Block)的專用壓縮解壓硬體模組。資料寫入DRAM時被即時壓縮,讀取時即時解壓,全程不佔用主機CPU一個周期。這意味著記憶體容量的"膨脹"是免費的,不消耗算力預算。
一、為什麼是硬體壓縮,而不是軟體壓縮
軟體壓縮不是新鮮事,作業系統層面的記憶體壓縮(比如zRAM)用了十幾年。但軟體壓縮有個死結:壓縮解壓要佔用CPU周期,資料量越大,CPU開銷越高,最後變成拆東牆補西牆,省下的記憶體換來的是算力的損失。對於本來就在拼算力的AI叢集來說,這筆帳並不划算。
Structera把這個環節整個搬到了CXL控製器的硬體電路里,繞開主機CPU獨立完成壓縮解壓,還相容OCP(開放計算項目)提交的規範,是目前唯一一款把內聯壓縮做成量產在售功能的CXL記憶體控製器。CDB模組採用定製版LZ4演算法,一種無失真壓縮演算法,在壓縮率和延遲之間做了工程上的平衡,還支援一對多的記憶體對應結構。
二、兩款晶片,兩種打法
Structera X:記憶體擴展控製器
Structera X定位是純粹的CXL記憶體擴展控製器,同時相容DDR5和DDR4兩代標準,這個向下相容的設計其實挺聰明,等於給還在用DDR4庫存的資料中心也留了一條升級通路。
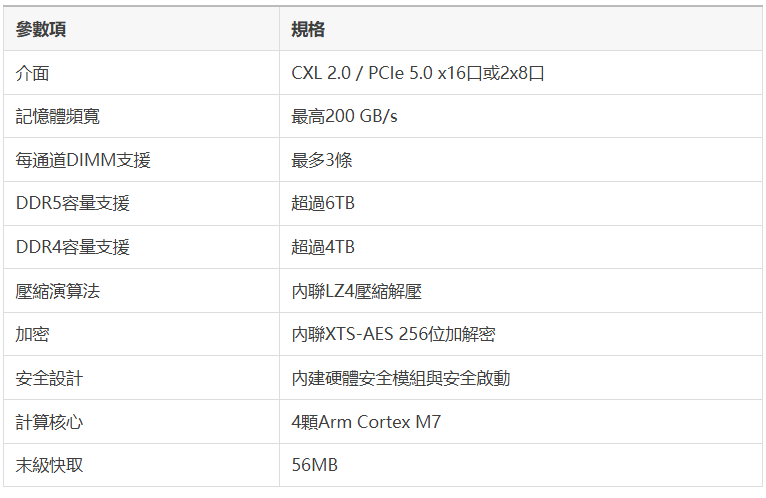
Structera A:近記憶體加速控製器
Structera A的野心更大一些,它不只是擴容,還內建了16顆Arm Neoverse V2(代號Demeter)核心,主頻3.2GHz,等於在記憶體控製器旁邊掛了一顆小型計算叢集,專門做近記憶體計算,減少資料在記憶體和主處理器之間來回搬運的開銷。
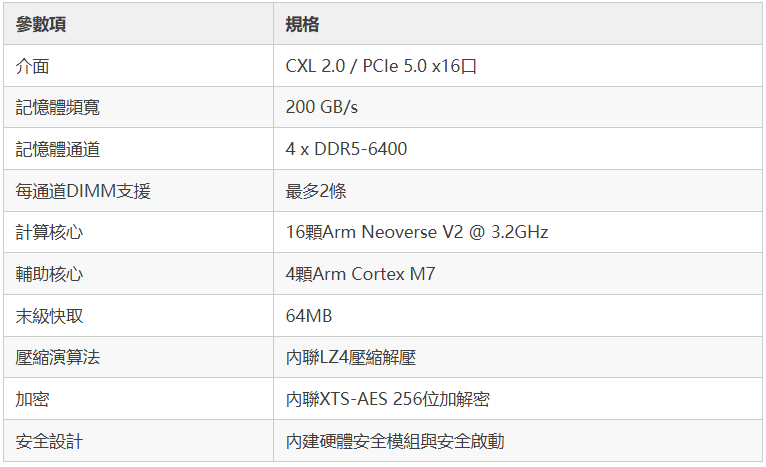
洞察
Structera X和A的差異,本質是"存"和"算"兩條路線的分野。X做的是純粹的容量堆疊,A做的是把計算能力前置到記憶體旁邊。後者其實更值得關注,因為它暗示了一個方向:未來的記憶體控製器不再只是資料的搬運工,而是要順手幹一部分計算活兒,這對傳統馮諾依曼架構裡CPU和記憶體的分工邊界,是一次實質性的鬆動。
三、壓縮比的真實資料,不是紙面參數
Marvell公佈了CDB模組在行業標準混合資料集上的實測壓縮比,並且拿主機端軟體LZ4壓縮做了對照,結果相當接近,這一點比單純宣傳"壓縮率高"更有說服力,因為它證明了硬體壓縮沒有為了速度犧牲壓縮質量。
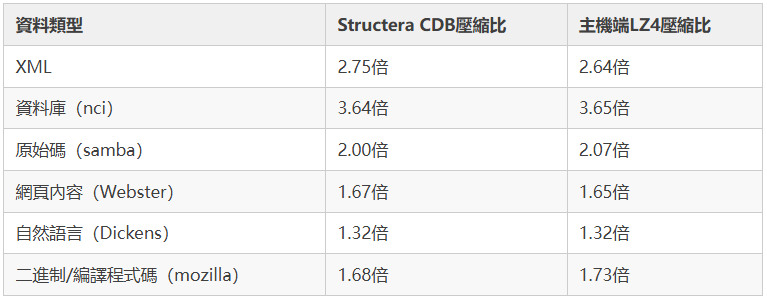
資料庫類型資料能達到3.64倍壓縮比是這次最亮眼的數字,原因不難理解,資料庫裡存在大量重複結構和空值欄位,天然適合LZ4這類基於字典的壓縮演算法。而自然語言文字這類資訊熵較高的資料,壓縮比就老老實實回到1.32倍,這也符合壓縮理論的基本常識,不存在"萬能壓縮"這種東西。
另外一個關鍵參數是頁大小支援4KB和1KB兩種粒度,壓縮效果強度可在0到3級之間配置,對全零頁面(比如剛分配尚未寫入的記憶體)的最大壓縮比可以達到64:1,這個數字看著誇張,但其實是所有壓縮記憶體方案的標配彩蛋,全零資料本來就是壓縮演算法最容易吃下的"送分題"。
警示
壓縮比不是免費午餐,它只是把"缺記憶體"的痛苦轉移成了"資料類型不確定性"的風險。對AI訓練這種以浮點權重、KV快取為主的負載來說,資料熵值往往偏高,實際能拿到的壓縮收益大機率達不到資料庫場景的3.64倍,更接近1.3到1.7倍區間。採購決策如果照搬廠商公佈的最高壓縮比去做容量規劃,大機率會踩坑。
四、跳出參數表看這件事
這裡說一個大部分討論都沒提到的角度:Structera這類方案真正的價值,或許不在於它能省多少記憶體,而在於它悄悄改寫了記憶體採購的經濟學模型。
過去記憶體容量規劃是一道簡單的算術題,要多少GB就買多少條DIMM,價格隨行就市。現在多了一個變數叫"有效壓縮比",同樣一條64GB的DIMM,跑資料庫負載可能頂三條用,跑AI推理負載可能只頂一條半用。這意味著採購和維運部門必須先摸清楚自己業務的資料類型畫像,才能算出真實的性價比,這對企業IT團隊的技術門檻提出了新的要求,不再是簡單地"看GB算錢"。
再往深一層想,如果壓縮比真的可以做到接近軟體LZ4的水準且幾乎零算力開銷,那麼記憶體廠商和CXL控製器廠商之間的博弈關係也會變化。DRAM顆粒廠商賣的是物理容量,而CXL控製器廠商賣的是"有效容量放大器",後者如果做得足夠好,理論上是在替代一部分DRAM本身的採購需求。這在當前DRAM供給緊張、議價權完全在顆粒廠商手裡的格局下,給了下游整機廠和雲廠商一個新的談判籌碼:與其死磕漲價的DRAM合約,不如把預算投向能放大現有記憶體效用的控製器方案。
還有一點容易被忽略,這類硬體壓縮方案天然是為CXL池化記憶體架構鋪路的。當記憶體脫離單台伺服器、變成跨節點共享的資源池時,壓縮帶來的容量增益會被池化架構進一步放大,因為壓縮省下來的空間可以被整個資源池裡的多個計算節點動態共享,而不是鎖死在某一台機器裡。這也是為什麼Marvell把CDB模組的規範提交給OCP,硬體壓縮要真正發揮價值,必須成為整個開放記憶體生態的公共標準,而不是某一家的專屬功能。
五、加密不是附加題
兩款晶片都內建了XTS-AES 256位記憶體加解密和硬體安全模組,這一點值得單獨點出來。CXL記憶體池化天然帶來一個安全隱患:記憶體資源在多個計算節點之間共享,資料在物理鏈路上暴露的窗口比傳統直連記憶體架構更大。把加解密做進控製器硬體而不是依賴軟體層,是在把"記憶體池化"和"資料安全"這兩個原本有點衝突的目標,用硬體的方式強行調和到了一起。
一句話總結
記憶體漲價周期裡,真正稀缺的從來不是矽片本身,而是讓每一顆矽片發揮出更大價值的工程能力。Structera證明了一件事:在儲存介質供給受限的窗口期,壓縮演算法從"軟體裡的一個功能選項",正在被重新定義成"硬體裡必須內建的基礎設施"。
當前AI算力和記憶體的供需矛盾短期內很難緩解,類似Structera這樣在控製器層面做文章的方案,大機率會在未來一到兩年裡成為伺服器和資料中心採購清單上的常規選項,而不再是小眾的技術嘗鮮。詞元產出的成本最終要攤到每一顆記憶體顆粒上,誰能把顆粒的利用效率往上抬一截,誰就在這輪供給緊張裡多了一分主動權。 (芯在說)