
大腦皮層表面那層複雜的溝回褶皺,想要在電腦裡即時重建,過去需要昂貴的大型計算裝置離線運算良久。如今,這一局面被一顆拇指大小的晶片改寫。
新基石研究員、北京大學積體電路學院教授楊玉超團隊聯合中國科學院上海微系統與資訊技術研究所宋志棠研究員團隊,成功研製出全球首款基於相變憶阻器的神經動力學系統晶片,首次將這類複雜運算的單步時延壓縮至2.12毫秒,在腦皮層重建等任務中較目前先進圖形處理器(GPU)提速達50至478倍,一舉突破了制約神經動力學長達半個世紀的即時計算瓶頸。相關成果3日凌晨發表於《科學》。
楊玉超介紹,要讓機器像大腦那樣即時建模和理解物理世界,需要一種將神經網路與微分方程相結合的“神經動力學系統”。它能在不完整、帶噪聲的資料中重建出平滑精確的三維腦結構,應用潛力巨大。
然而,傳統計算架構存在一個核心瓶頸:儲存與計算分離,求解過程中海量的中間變數在記憶體和處理器之間反覆奔波,如同一個龐大的資料工廠,大量時間被浪費在搬運路途中,不僅延遲巨大,功耗也居高不下。
面對這一難題,研究團隊從憶阻器本身的物理特性裡找到了破局答案。他們利用相變儲存器獨特的“電導漂移”現象——在一定時間窗口內,其電導變化是可預測、可精準調控的。
基於此,團隊提出“可控存內計算”新範式,將動力學系統求解中最耗時的自適應步長搜尋,直接編碼為器件的物理電導演化過程,在儲存單元內部原地完成計算。通俗地講,原本需要複雜數位電路反覆執行的運算、快取訪問、資料搬運等工作,現在交給了器件自身的物理規律去“跑”。
更值得關注的是,團隊還將神經網路權重對應到相變儲存器的多級電導態上,在同一個陣列內同步完成矩陣乘加運算。兩大核心計算任務由此被統一整合在總面積僅0.28平方毫米的存算陣列中。這顆採用40奈米工藝的晶片運行頻率為50兆赫茲,單步積分僅需9級流水線,最終實現2.12毫秒的單次迭代時延,首次將神經動力學硬體推入毫秒時代。
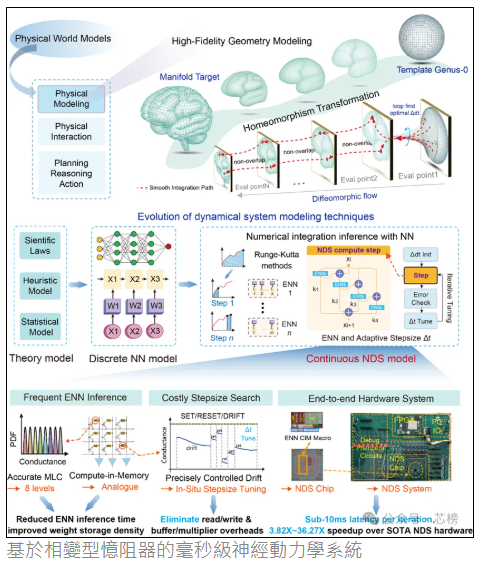
“性能表現令人振奮。”楊玉超表示,在同等運算下,該晶片較當前最先進的專用加速器速度提升3.82至36.27倍,功耗降低11.75至24.73倍;在腦皮層表面高保真重建任務中,甚至比NVIDIA A100 GPU提速高達50.38至478.18倍。重建出的腦皮層網格平滑、拓撲一致,能精準刻畫複雜的褶皺結構,並有效抑制傳統方法中的偽影和自相交缺陷。
楊玉超說,這一突破為腦機介面和腦疾病診療開啟了全新想像空間。未來,個體化、動態化的腦數字孿生成為可能,術中神經導航、阿爾茨海默症早篩及個性化干預等,將獲得可即時運行的硬體底座。
來源:微信公眾號“共青團中央”綜合整理自微信公眾號“光明日報”(記者:晉浩天),“北京大學積體電路學院”、“北京大學深圳研究生院” (芯榜)