

儘管GPU需求本身很大,但供給根本跟不上。
自2022年11月Open AI發表ChatGPT以來,生成式AI(人工智慧)需求在全球爆發性成長。這一系列AI應用運行在配備有NVIDIA GPU等AI半導體的AI伺服器上。
不過,根據台灣研究公司TrendForce在2023年12月14日的預測,AI伺服器出貨量增加不會如預期。預計2022年AI伺服器僅佔所有伺服器出貨量的6%,2023年為9%,2024年為13%,2025年為14%,2026年為16%。 (圖1)。
圖1.伺服器出貨數量、AI伺服器佔比、AI晶片晶圓佔比。來源:TrendForce
原因被認為是人工智慧半導體的限速供應。目前,NVIDIA的GPU壟斷了約80%的AI半導體,製造在台積電進行。在後續的流程中,會利用CoWoS進行封裝,但CoWoS的產量目前是一個瓶頸。
另外,在CoWoS中,GPU周圍放置了多個HBM(高頻寬記憶體),這些HBM是堆疊的DRAM,這個HBM也被認為是瓶頸之一。
那麼,為什麼台積電的CoWoS(Chip on Wafer on Substrate)產能持續不足呢?另外,雖然有三星電子、SK海力士、美光科技三大DRAM廠商,但為什麼HBM也不夠呢?
本文討論了這些細節。 NVIDIA GPU 等AI 半導體的短缺預計將持續數年或更長時間。
台積電的製造流程是什麼?
圖2顯示了NVIDIA 的GPU 是如何在台積電製造的。首先,在預處理中,分別創建GPU、CPU、記憶體(DRAM)等。這裡,由於台積電不生產DRAM,因此似乎是從SK海力士等DRAM製造商獲得HBM。

接下來,將GPU、CPU、HBM等黏合到「矽中介層」上(Chip on Wafer,或CoW)。矽中介層具有預先形成的佈線層和矽通孔(TSV)以連接晶片。
這步驟完成後,將中介層貼在基板上(Wafer on Substrate,簡稱WoS),進行各種測試,CoWoS封裝就完成了。
圖3顯示了CoWoS的橫斷面結構。兩個邏輯晶片(例如GPU 和CPU)以及具有堆疊式DRAM 的HBM 被黏合到矽中介層上,矽中介層上形成有佈線層和TSV。中介層透過與銅凸塊連接到封裝基板,並且該基板透過封裝球連接到電路板。
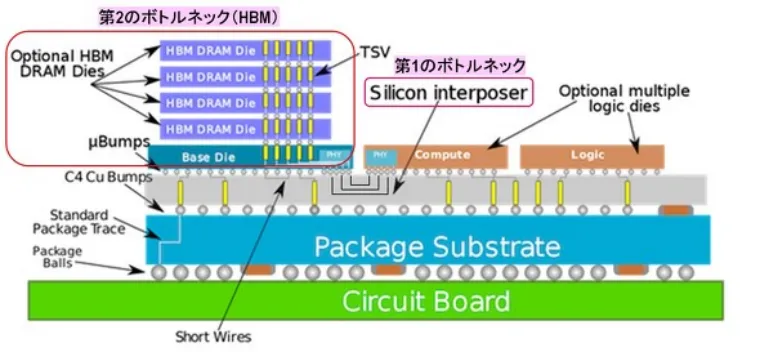
在這裡,我們認為第一個瓶頸是矽中介層,第二個瓶頸是HBM,這是導致NVIDIA GPU短缺的原因。
矽中介層尺寸變得巨大
圖4 顯示了自2011 年以來CoWoS 的換代情況。首先,我們可以看到,每一代的矽中介層都變得巨大。此外,安裝的HBM 數量也在增加。
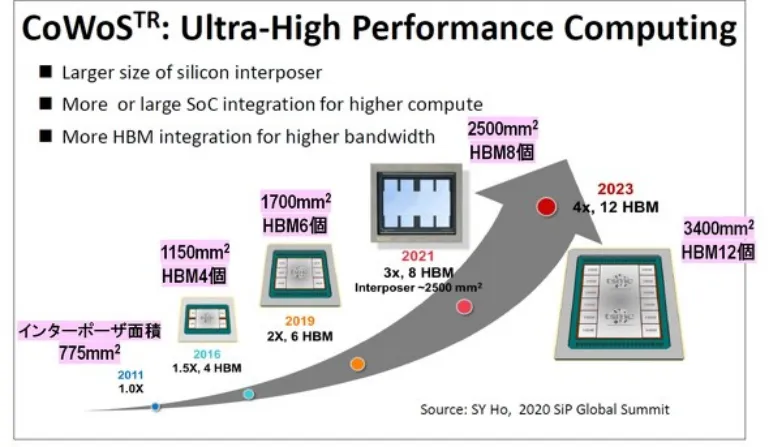
圖5 顯示了從CoWoS Gen 1 到Gen 6 的12 吋晶圓中安裝的Logic 晶片類型、HBM 標準和安裝數量、矽中介層面積以及可獲得的中介層數量。
可以看出,自第三代以來,HBM的安裝數量持續增加了1.5倍。此外,HBM 的標準也發生了變化,性能也提高了。此外,隨著中介層面積的增加,可以從12 吋晶圓獲得的中介層數量減少。
然而,這個採集數只是“將12吋晶圓的面積除以中介層的面積所得到的值”,實際的採集次數要小得多。
2023 年發布的第6 代CoWoS 中介層的面積為3400 mm 2 ,但如果我們假設它是一個正方形,它將是58 mm × 58 mm。如果將其放置在12 吋晶圓上,則晶圓邊緣上的所有中介層都將有缺陷。然後,58 mm × 58 mm中介層最多只能從12 吋晶圓上取得9 個。
此外,在中介層上形成佈線層和TSV,但良率約為60~70%,因此從12吋晶圓上可以獲得的良好中介層數量最多為6個。
使用這款轉接板製作的CoWoS 的代表性GPU 是NVIDIA 的“H100”,它在市場上競爭激烈,交易價格高達40,000 美元。
台積電的CoWoS產能不足
那麼,台積電的CoWoS製造產能有多大呢?
在2023 年11 月14 日舉行的DIGITIMES 研討會「生成式AI 浪潮中2024 年全球伺服器市場的機會與挑戰」中顯示,2023 年第二季的產能為每月13K~15K 件。據預測,2024 年第二季月產量將翻倍至30K~34K,進而縮小NVIDIA GPU 的供需缺口。
然而,這種前景還很遙遠。這是因為,截至2024 年4 月,NVIDIA 仍然沒有足夠的GPU。而TrendForce集邦諮詢在4月16日的新聞中表示,到2024年底,台積電的CoWoS產能將達到每月40K左右,到2025年底將翻倍。
此外,TrendForce集邦諮詢報告稱,NVIDIA將發布B100和B200,但這些轉接板可能比58 mm × 58 mm還要大。這意味著從12吋晶圓上可以獲得的優質中介層的數量將進一步減少,因此即使台積電拼命嘗試增加CoWoS產能,也無法生產足夠的GPU來滿足需求。
這款GPU CoWoS中介層的龐大和台積電產能的增加,無論走多遠都沒有止境。
有人建議使用515×510mm棱柱形有機基板取代12吋晶圓作為中介層。此外,美國的英特爾公司也提議使用矩形玻璃基板。當然,如果可以使用大型矩形基板,則可以比圓形12吋晶圓更有效地獲得大量中介層。
然而,為了在矩形基板上形成佈線層和TSV,需要專用的製造設備和傳輸系統。考慮到這些的準備工作,這需要時間和金錢。接下來解釋HBM的情況,這是另一個瓶頸。
HBM 的路線圖
如圖4 和圖5 所示,HBM 的數量隨著CoWoS 的產生而增加,這也導致了中介層的巨大。 DRAM製造商不應繼續製造相同標準的HBM。隨著CoWoS 的發展,HBM 的各種性能需要改進。 HBM 的路線圖如圖7 所示。
首先,HBM 必須提高每秒交換資料的頻寬,以配合GPU 效能的提升。具體來說,2016 年HBM1 的頻寬為128 GB/s,而HBM3E 的頻寬將擴大約10 倍,達到1150 GB/s,將於2024 年發布。
接下來,HBM 的記憶體容量(GB) 必須增加。為此,有必要將堆疊在HBM 中的DRAM 晶片數量從4 個增加到12 個。下一代HBM4 的DRAM 層數預計將達到16 層。
此外,HBM 的I/O 速度(GB/s) 也必須提高。為了同時實現所有這些目標,我們必須不惜一切代價實現DRAM的小型化。圖8顯示了按技術節點劃分的DRAM銷售比例的變化。 2024 年將是從1z (15.6 nm) 切換到1α (13.8 nm) 的一年。之後,小型化將以1 nm 的增量進行,例如1β (12.3 nm)、1γ (11.2 nm) 和1δ (10 nm)。
請注意,括號中的數字是該代DRAM晶片中實際存在的最小加工尺寸。
EUV也開始應用於DRAM
DRAM製造商必須以1nm的增量進行小型化,以實現高整合度和速度。因此,EUV(極紫外線)微影技術已開始應用於精細圖案的形成(圖9)。

最早在DRAM 中使用EUV 的公司是三星,在1z 世代中僅應用了一層。不過,這只是藉用了三星邏輯代工廠的一條每月最大產量為10,000 片晶圓的巨大DRAM 生產線來實踐EUV 應用。因此,從真正意義上講,三星只是從1α 年開始在DRAM 中使用EUV,當時它在五層DRAM 中使用了EUV。
其次是在HBM 領域市佔率第一的SK hynix,它在1α 生產時應用了EUV。該公司計劃在2024 年轉向1β,並有可能在三到四層應用EUV。因此,迄今只有幾個EUV 單元的SK hynix 將在2024 年之前推出10 個EUV 單元。同樣擁有邏輯代工廠的三星公司被認為將擁有超過30 個EUV 單元。
最後,美光公司一直奉行盡可能少使用EUV 的策略,以便比其他地方更快地推進其技術節點。事實上,美光在1 β 之前都不使用EUV。在開發過程中,它還計劃在1 γ 時不使用EUV,而是使用ArF 沉浸+ 多圖案技術,但由於它發現很難提高產量,因為沒有更多的匹配空間,因此預計將從1 γ 開始引入EUV。
這三家DRAM 製造商目前正在嘗試使用鏡頭孔徑為NA = 0.33 的EUV,但據認為,它們正在考慮從2027-2028 年起改用高NA。因此,DRAM 製造商的微型化進程仍將越走越遠。
現在,有多少HBM 將採用這些最先進的製程生產?
DRAM 出貨量與HBM 出貨量
圖10 顯示了DRAM 出貨量、HBM 出貨量以及HBM 佔DRAM 出貨量的百分比。如本節開頭所述,ChatGPT 於2022 年11 月發布,從而使輝達公司的GPU 在2023 年取得重大突破。

同時,HBM 的出貨量也迅速成長:HBM 的出貨量從2022 年的27.5 億美元(3.4%)成長到2023 年的54.5 億美元(10.7%),幾乎翻了一番,到2024年更是翻了一番,達到140.6 億美元(19.4%)。
從DRAM 的出貨量來看,2021 年由於對Corona 的特殊需求而達到高峰,但2023 年這種特殊需求結束後,出貨量急劇下降。此後,出貨量預計將恢復,並在2025 年超過2021 年的高峰。此外,從2026 年起,出貨量預計將繼續增長,儘管會有一些起伏,到2029 年將超過1500 億美元。
另一方面,HBM 的出貨量預計將在2025 年後繼續成長,但HBM 在DRAM 出貨量中所佔的份額將在2027 年後達到24-25% 的飽和狀態。這是為什麼呢?
各種HBM 的出貨數量和HBM 出貨總量
如圖11 所示,透過觀察各種HBM 的出貨量和HBM 的總出貨量,可以揭開謎底。
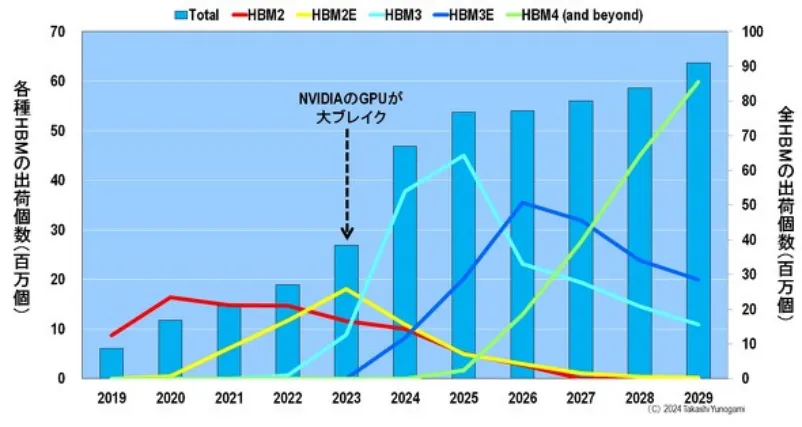
首先,在2022 年之前,HBM2 是主要的出貨量。其次,2023 年,輝達的GPU 取得重大突破,HBM2E 取代HBM2 成為主流。此外,HBM3 將在今年2024 至2025 年間成為主流。 2026-2027 年,HBM3E 將成為出貨量最大的產品,而從2028 年開始,HBM4 將扮演主角。
換句話說,HBM 將以大約兩年的間隔經歷世代更迭。這意味著DRAM 製造商必須繼續以1 奈米為單位進行微型化,同時每兩年更新一次HBM 標準。
因此,如圖11 所示,2025 年後所有HBM 的出貨量幾乎不會增加。這並不是因為DRAM 製造商懈怠,而是因為他們必須盡最大努力生產最先進的DRAM 和最先進的HBM。
此外,2025 年後HBM 出貨量不會大幅成長的原因之一是堆疊在HBM 中的DRAM 晶片數量將增加(圖12):隨著GPU 效能的提高,HBM 的記憶體容量(GB)也必須增加,因此堆疊在HBM 2 和HBM2E 中的DRAM 數量將增加。 HBM2 和HBM2E 中堆疊的DRAM 數量將增加到4-8 個DRAM,HBM3 和HBM3E 中堆疊的DRAM 數量將增加到8-12 個,HBM4 中堆疊的DRAM 數量將增加到16 個。
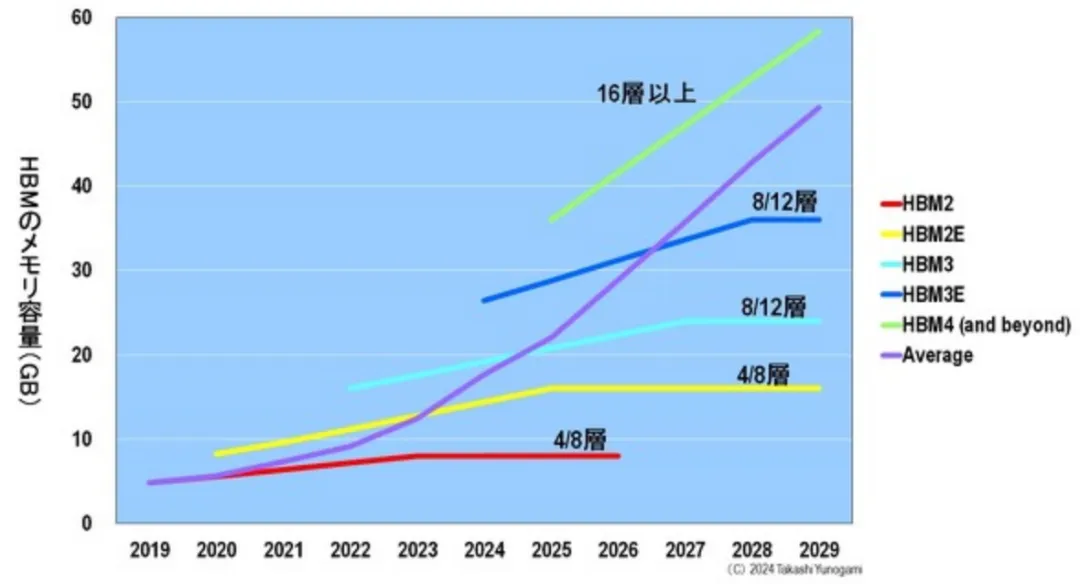
這意味著HBM2 只需要4 到8 個DRAM,而HBM4 將需要2 到4 倍的DRAM,即16 個DRAM。這意味著,在HBM4 時代,DRAM 製造商可以生產比HBM2 多2-4 倍的DRAM,但出貨量仍與HBM 相同。
因此,隨著DRAM 繼續以1nm 的增量縮小,HBM 兩年換一代,HBM 中堆疊的DRAM 數量每一代都在增加,預計從2025 年起,HBM 的總出貨量將達到飽和。
那麼,HBM 的短缺會持續下去嗎? DRAM 製造商是否無法進一步增加HBM 的出貨量?
DRAM 製造商急於大規模生產HBM
我們已經解釋了DRAM 製造商無法大幅增加HBM 出貨量的原因,但DRAM 製造商仍然能夠達到他們的極限,倘若超過這個極限,他們就會嘗試大量生產HBM。這是因為HBM 的價格非常高。
圖13 顯示了各種HBM 和普通DRAM 的每GB 平均價格。普通DRAM 和HBM 在發佈時的每GB 價格都是最高的。雖然趨勢相同,但普通DRAM 和HBM 的每GB 價格相差20 倍以上。為了比較普通DRAM 和HBM 的每GB 平均價格,圖13 的圖表顯示了普通DRAM 的10 倍價格。
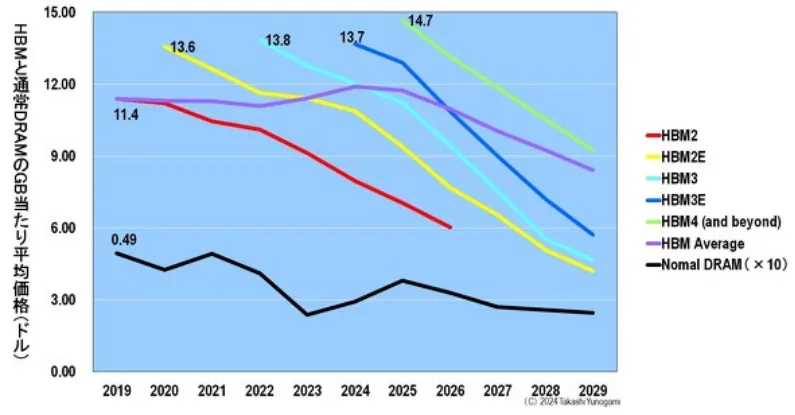
與普通DRAM 的0.49 美元相比,比較每GB 的價格,在剛發布後的最高價格時,HBM2 的每GB 價格大約是普通DRAM 的23 倍(11.4 美元),HBM2E 的每GB 價格大約是普通DRAM的28 倍(13.6 美元),HBM4 的每GB 價格約為普通DRAM 的30 倍(14.7 美元)。
此外,圖14 顯示了各種HBM 的平均價格。價格最高的HBM2 為73 美元,HBM2E 為157 美元,HBM3 為233 美元,HBM3E 為372 美元,HBM4 則高達560 美元。
圖15顯示了HBM 的價格有多昂貴。例如,DRAM廠商在1z製程生產的16GB DDR5 DRAM最多為3~4美元。不過,今年,SK海力士發布的HBM3E售價將比361美元高出90~120倍。
DDR(雙倍資料速率)是一種記憶體標準。資料傳輸速度越來越快,DDR5 的速度是DDR4 的兩倍,DDR6 的速度是DDR5 的兩倍。 2024 年將是DDR4 轉型為DDR5 的一年,DRAM 製造商也必須不斷更新其DDR 標準。
回到HBM,HBM3E 的晶片尺寸與最新iPhone 17 的A15 仿生AP(應用處理器)大致相同,後者採用台積電最先進的3nm 製程生產,但價格高出3.6 倍。 DRAM的HBM高於高階邏輯。這是令人震驚的。而由於價格如此高,DRAM廠商將竭盡全力增加出貨量,以主導HBM的霸主地位。
讓我們來看看三家DRAM製造商的路線圖。
DRAM 製造商爭奪HBM
圖16顯示了2015~2024 年三家DRAM 製造商如何生產HBM。
HBM1 首次成功量產的是SK 海力士。然而,就HBM2而言,三星比SK海力士率先實現量產。當NVIDIA 的GPU 在2023 年取得重大突破時,SK海力士率先成功量產HBM3。這為SK海力士帶來了巨大的利益。
另一方面,另一家DRAM 製造商美光最初開發了與HBM 標準不同的混合記憶體立方體(HMC)。然而,聯合電子裝置工程委員會(JEDEC) 是一個促進美國半導體標準化的行業組織,已正式認證了HBM 標準而不是HMC。因此,美光從2018年開始放棄HMC的開發,進入HBM的開發,遠遠落後於兩家韓國製造商。
因此,在HBM 的市佔率中, SK 海力士為54%,三星為41%,美光為5%。
擁有最大HBM份額的SK海力士將於2023年開始在其NAND工廠M15生產HBM。此外,HBM3E 將於2024 年上半年發布。此外,在2025 年,目前正在建造中的M15X 工廠將專門為HBM 重新設計,以生產HBM3E 和HBM4。
另一方面,想要趕上SK海力士的三星計劃於2023年在三星顯示器的工廠開始生產HBM,2024年將HBM的產能翻倍,並在SK海力士之前於2025年量產HBM4。
一直落後的美光的目標是在2024~2025年跳過HBM3,與HBM3E競爭,並在2025年獲得20%的市佔率。此外,到2027~2028年,該公司也設定了在HBM4和HBM4E量產方面趕上韓國兩大製造商的目標。
如此一來,三家DRAM廠商之間的激烈競爭可能會突破HBM出貨量的飽和,從而消除HBM的短缺。
NVIDIA的GPU短缺會持續多久?
在本文中,我們解釋了NVIDIA GPU 等AI 半導體全球短缺的原因。
1、NVIDIA 的GPU 採用台積電的CoWoS 封裝製造。這個CoWoS的容量是完全不夠的。原因是配備GPU、CPU 和HBM 等晶片的矽中介層每一代都變得越來越大。台積電正試圖增加這個中間製程的容量,但隨著GPU世代的推進,中介層也會變得巨大。
2、CoWoS 的HBM 短缺。造成這種情況的原因是DRAM製造商必須繼續以1nm的增量進行小型化,HBM標準被迫每兩年更換一次,並且HBM中堆疊的DRAM晶片數量隨著每一代的增加而增加。 DRAM製造商正在盡最大努力生產HBM,但預計出貨量將在2025年後飽和。然而,由於HBM的價格非常高,DRAM廠商之間競爭激烈,這可能導致HBM的短缺。
如上所述,有兩個瓶頸導致NVIDIA 的GPU 短缺:台積電的製造產能短缺和HBM 短缺,但這些問題不太可能在大約一年內解決。因此,預計未來幾年NVIDIA 的GPU 短缺將持續下去。(半導體產業縱橫)