
兩種技術概要總結
英特爾18A+EMIBT與台積電2nm+CoWoS兩大技術組合的系統性分析對比:
技術路線差異化:
英特爾18A+EMIBT採取了"製程跳躍+封裝顛覆"的激進創新策略,通過RibbonFET GAA電晶體和革命性PowerVia背面供電技術,在單晶片性能與能效比上實現25%-36%的顯著提升,同時EMIBT封裝以局部矽橋設計顛覆傳統CoWoS矽中介層模式,實現30-40%的成本節約。
台積電2nm+CoWoS則延續"穩健迭代+生態鞏固"路線,Nanosheet GAA技術確保工藝平滑過渡,依託CoWoS成熟生態在AI訓練市場佔據45-50%份額。
市場格局格局:
AI訓練市場由台積電CoWoS主導,輝達Hopper/Blackwell系列佔據80%以上產能,但2025年產能缺口達20-30%。英特爾EMIBT憑藉成本優勢和120×180mm超大封裝尺寸支援能力,在AI推理和定製ASIC市場快速突破,已獲GoogleTPU v9、Meta MTIA、微軟Maia等 意向客戶採用。
技術成熟度差異:
台積電2nm於2025年啟動風險試產,2026年H1良率已達90%,2026年H1月正式量產;英特爾18A目前良率約55-70%(2026年Q3-Q4),量產時間相近但良率爬坡壓力更大。封裝層面,CoWoS技術積累超過15年,EMIBT於2026年量產,技術成熟度存在代際差距。
台積電體系在極致性能與生態成熟度上領先,英特爾體系在成本效益、封裝尺寸擴展性和供應鏈安全上建構差異化優勢。未來3-5年將形成CoWoS主導訓練、EMIBT主導推理的分層格局。
製程工藝差異
電晶體架構,GAA技術實現路徑差異
英特爾 RibbonFET(18A工藝):RibbonFET是英特爾首次量產化的GAA架構,採用水平堆疊的奈米片(Nanosheet)設計,柵極四面環繞導電通道。相比FinFET架構,實現三大突破:
驅動電流增強20%:通過5-6片5nm厚度的矽奈米片堆疊,有效溝道寬度提升,單位面積驅動電流達1.2mA/μm
漏電流降低50%:四面環繞柵極靜電控制能力增強,亞閾值擺幅(SS)最佳化至65mV/dec
動態寬度可調:支援NMOS和PMOS採用不同數量奈米片,實現PPA精細最佳化,標準單元密度達238 MTr/mm²(HD庫)
台積電 Nanosheet(N2工藝):台積電採用多橋通道場效應電晶體(MBCFET)結構,奈米片寬度控制精度達±0.5nm,通過多年N3工藝最佳化經驗積累,實現:
電晶體密度優勢:HD庫密度預計達313 MTr/mm²,比18A高出31.5%,在相同功能下晶片面積更小
成熟工藝遷移:從FinFET到Nanosheet的DTCO(設計技術協同最佳化)流程完善,客戶遷移風險低
性能功耗平衡:在1.1V電壓下,性能提升15%,漏電控制接近FinFET水平,良率爬坡曲線更陡峭
RibbonFET在驅動能力和能效比上實現"代際跨越",但犧牲部分密度;Nanosheet在密度和良率控制上佔優,體現台積電"穩中求進"策略。
供電技術革新:PowerVia vs 前端供電
英特爾 PowerVia(背面供電網路):作為業界首個量產BSPDN技術,PowerVia將完整供電網路移至晶圓背面:
電壓降降低40%:通過TSV直接連接電晶體源漏極,PDN阻抗從15mΩ降至9mΩ
密度提升8-10%:前端金屬層釋放15%布線資源,標準單元利用率提高至92%
熱機械挑戰:需解決背面研磨、TSV對準(±0.3μm精度)和應力管理問題,採用臨時鍵合與載體晶圓工藝
台積電 N2 前端供電:台積電在N2節點仍採用傳統前端供電,將BSPDN推遲至2026年A16節點:
成熟可靠:沿用N3-Power Delivery架構,風險規避
金屬層最佳化:採用15層金屬堆疊(M0-M14),其中M0-M3為埋入式電源軌,部分緩解IR Drop
性能差距:對比PowerVia,電壓降高約15-20%,限制極限頻率下的穩定性
PowerVia是18A最大技術賭注,成功量產將確立英特爾在供電架構上的領先地位,但工藝複雜度增加3個光罩層,對良率爬坡構成壓力。
工藝性能與能效量化對比

18A的25%-36%改進幅度體現"技術跳躍"策略,但密度劣勢意味著在相同功能晶片上成本競爭力不足;
台積電15%性能提升雖保守,但配合313 MTr/mm²密度,在成本敏感型應用更具優勢。
先進封裝技術深度剖析
英特爾 EMIBT 技術架構
技術演進:EMIBT在第二代EMIB(45μm凸塊間距)基礎上,整合TSV形成"2.5D+3D"混合架構:
核心結構:在有機/玻璃基板局部嵌入矽橋,尺寸約10×10mm,內含6-8層RDL,線寬/線距3μm/3μm
TSV整合:矽橋內整合35μm間距TSV,實現垂直供電(V-PDN),電源傳輸電阻降低30%,支援HBM4的1.2V/1.8V雙電壓域
封裝尺寸:計畫2026-2027年支援6倍→8-12倍光罩尺寸,2028年目標120×180mm(約15倍光罩),容納24顆以上HBM
互連密度:UCIe-A協議支援32Gb/s,實際頻寬2.8TB/s(12顆HBM4),通過矽橋平行度達1024通道
成本結構:矽橋佔封裝面積<20%,相比CoWoS全尺寸中介層,材料成本降低40-50%,良率損失減少60%
熱機械可靠性:基板CTE 15ppm/°C,矽橋CTE 2.6ppm/°C,局部嵌入設計使翹曲量<50μm,遠低於CoWoS的120μm
設計靈活性:支援混合鍵合(Hybrid Bonding)與微凸塊共存,可整合不同工藝節點芯粒(如18A+Intel 3+N6)
台積電 CoWoS 技術架構
技術譜系:已形成CoWoS-S/R/L完整產品矩陣,2025年主推CoWoS-L(Local Silicon Interconnect):
CoWoS-S:矽中介層面積最大3320mm²,12層RDL,線寬/線距0.4μm/0.4μm,支援12顆HBM3E,頻寬5.3TB/s
CoWoS-L:在RDL基板嵌入LSI矽橋(尺寸約20×20mm),中介層成本降低30%,支援12顆HBM4,2027年擴展至9倍光罩尺寸
互連工藝:微凸塊間距30-60μm(銅柱高度20μm),TSV直徑10μm,深寬比10:1,絕緣層厚度2μm
散熱方案:矽整合微通道冷卻(IMC-Si),在SoC背面製造蛋形矽微柱陣列,TIM-less設計熱阻<0.01°C/W
生態成熟度:超過20年量產經驗,IP庫完善,客戶驗證流程標準化,NVIDIA/AMD等客戶已建立設計方法論
性能天花板:矽中介層互連密度達1200 IO/mm²,延遲<2ns,訊號損耗@32GHz <0.5dB/mm
產能規模:2025年CoWoS月產能約30萬片,計畫2026年翻倍,但仍有10-20%缺口
封裝技術關鍵參數對比
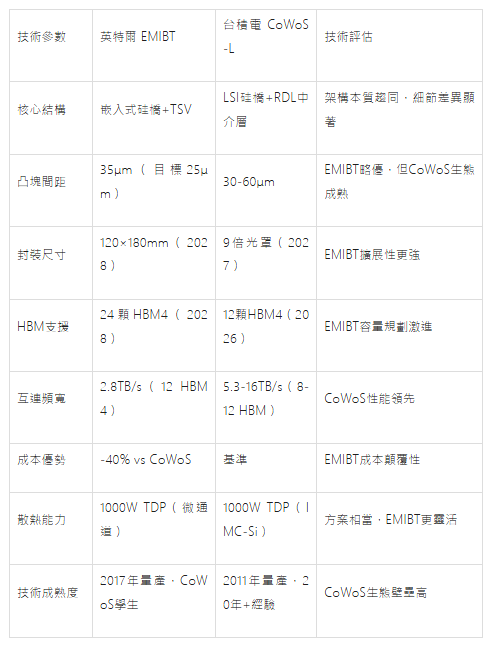
EMIBT本質是"CoWoS-L的英特爾版本",但通過更激進的尺寸擴展和成本最佳化實現差異化。局部矽橋設計使矽面積利用率從CoWoS的60%提升至90%,但犧牲部分互連性能;TSV整合增強供電能力,彌補RDL訊號路徑較長的劣勢。
成本、良率與量產對比
製造成本結構對比
晶圓製造成本
台積電N2晶圓報價約3萬美元/片,良率90%,有效晶片成本約3.33萬美元/片;英特爾18A晶圓成本未公開,但基於PowerVia額外4-5道光罩層和背面工藝,預計成本2.8-3.2萬美元/片,良率70%時有效成本4-4.6萬美元/片,成本競爭力暫不及台積電。
封裝成本結構
- CoWoS-S:矽中介層成本佔封裝總成本50-70%,12層RDL+TSV工藝使封裝成本達800-1200美元(HBM3E版本)
- EMIBT:矽橋成本僅40-60美元,有機基板+RDL成本約200-300美元,總封裝成本350-450美元,相比CoWoS-S降低60-65%
- 系統級成本:對於12-HBM的AI晶片,EMIBT方案總成本(矽+封裝)約低30-40%,這是Google/Meta選擇EMIBT的核心驅動力
良率與產能現狀
良率爬坡曲線
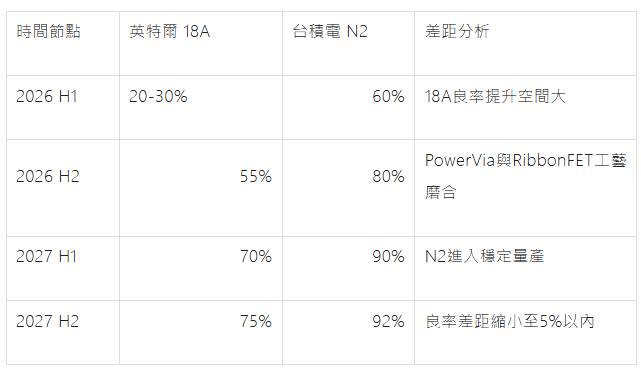
- 台積電:2026年N2月產能5萬片,2026年底達14萬片;CoWoS 2026年月產能30萬片,2027年目標60~80萬片,但仍無法滿足輝達/AMD需求
- 英特爾:18A產能集中於亞利桑那Fab 52/62,2026年H1月產能2-3萬片,2026年目標8萬片;EMIBT產能分散於亞利桑那、新墨西哥及與Amkor合作產線,2027年目標月產50萬等效封裝
應用場景與工程化進度
AI加速器市場:訓練 vs 推理的分化
AI訓練場景(CoWoS主導地位)
- 性能需求:記憶體頻寬>5TB/s,延遲<5ns,支援兆參數模型
- CoWoS優勢:矽中介層訊號完整性支援HBM3E 8.8GHz運行,TB/s級頻寬無瓶頸
- 客戶鎖定:輝達B300採用CoWoS-L整合8顆HBM3E,頻寬9TB/s,2026年產能已售罄
- EMIBT機會:微軟Maia 100採用EMIBT,推理場景下2.8TB/s頻寬足夠,成本節約30%
AI推理場景(EMIBT黃金期)
- 性能需求:能效比>10 TOPS/W,成本敏感,部署規模百萬級
- EMIBT優勢:1000W TDP散熱能力,支援24顆HBM4,推理batch處理吞吐量高
- 客戶突破:GoogleTPU v9(2027)採用EMIBT,單封裝12個計算芯粒+24 HBM4,推理延遲降低40%
- 經濟模型:Meta MTIA v3使用EMIBT,單卡成本降低35%,資料中心TCO節約顯著
伺服器CPU市場:英特爾的防守反擊
Clearwater Forest(英特爾)
- 架構:基於18A的288核至強CPU,採用EMIBT連接8個計算芯粒+4個I/O芯粒
- 性能:每瓦性能提升23%,8:1整合比,單機櫃性能密度提升3倍
- 競爭力:相容現有平台,無需主機板更換,對雲服務商吸引力大
AMD/ARM陣營(台積電)
- 現狀:AMD Bergamo採用台積電N5+CoWoS,128核;ARM Neoverse N3採用N3+CoWoS
- 挑戰:N2工藝成本高,CoWoS產能緊張,設計周期長
- 機會:CoWoS-L支援多晶片異構,適合CPU+AI加速器融合架構
移動與邊緣市場,台積電的絕對主場
高端手機SoC
- 台積電:蘋果A20/M6採用N2+CoWoS-R,整合5G基帶與AI引擎,2026年獨佔N2產能40%以上
- 英特爾:Panther Lake面向PC領域,TDP 45W,尺寸較大,不適用於手機
邊緣計算
- EMIBT機會:工業ASIC、自動駕駛推理晶片對成本敏感,EMIBT的120×180mm封裝可容納感測器融合單元
- CoWoS-L滲透:汽車ADAS域控製器採用CoWoS-L整合GPU+ISP+NPU,滿足車規可靠性要求
商業生態與客戶戰略分析
客戶佈局對比
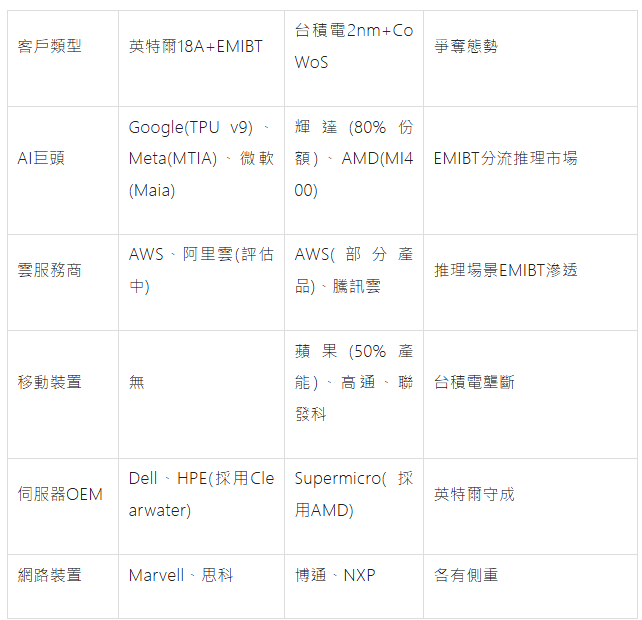
代工服務模式差異
台積電生態:
- 封閉但成熟:CoWoS技術僅對特定客戶開放,輝達/AMD已建立完整設計流程,遷移成本高
- 產能繫結:客戶需簽訂長期協議鎖定產能,新進入者(如Cerebras)難以獲得產能
- CyberShuttle:提供MPW服務降低研發門檻,但量產階段議價能力弱
英特爾IFS策略:
- 開放介面:EMIBT接受非英特爾矽片,與Amkor等OSAT合作,提供美國本土封裝
- 技術授權:向客戶開放UCIe IP和D2D介面標準,降低異構整合門檻
- 地緣政治優勢:美國CHIPS Act補貼下,2026-2028年封裝成本對比台積電低15-20%
技術挑戰與未來演進
當前技術瓶頸
英特爾18A+EMIBT
- 良率瓶頸:0.4 defects/cm²的缺陷密度導致858mm²大晶片良率僅3-22%,Panther Lake(約250mm²)良率60-80%,仍未達量產黃金水平(>85%)
- 供電完整性:PowerVia TSV在1.2V@1000A場景下,IR Drop需控制在<30mV,對TSV阻抗一致性要求極高
- 熱管理:超大封裝(120×180mm)的翹曲控制,需最佳化玻璃基板與矽橋CTE匹配
台積電2nm+CoWoS
- 產能瓶頸:2025年CoWoS產能約30萬片/月,僅能滿足輝達50%需求,導致客戶轉單意願增強
- 成本失控:矽中介層佔封裝成本50-70%,HBM4引入後,部分晶片出現"封裝成本>矽成本"現象
- 整合複雜度:12顆HBM4(2048位介面,8Gb/s速率)的訊號完整性挑戰,需引入3nm重驅動晶片
2026-2028技術演進路線
HBM4/5整合競賽
- HBM4:2026年量產,2048位介面,頻寬2TB/s,功耗<15pJ/bit。EMIBT通過TSV間距縮小至25μm直接連接;CoWoS-L採用0.4μm LSI橋接
- HBM5:2028年引入,支援近記憶體計算(NMC),在DRAM層內整合計算單元。EMIBT將升級為EMIBT-T,整合計算矽橋;台積電開發CoWoS-R+邏輯層堆疊
3D堆疊與混合鍵合
- 英特爾Foveros Direct 3D:2027年結合EMIBT,實現晶片間<10μm間距混合鍵合,頻寬密度>10TB/s/mm²
- 台積電SoIC+CoWoS:SoIC用於芯粒垂直堆疊(凸點間距<1μm),CoWoS用於HBM連接。預計2028年實現SoIC-L(邏輯+邏輯)與CoWoS-L(邏輯+HBM)混合封裝
標準化與生態
- UCIe 2.0:2026年支援CXL 3.0協議,速率達64GT/s,英特爾主導開放生態
- 台積電3DFabric:保持封閉但最佳化設計工具鏈,2025年推出3D IC參考設計平台,降低客戶學習曲線
技術總結
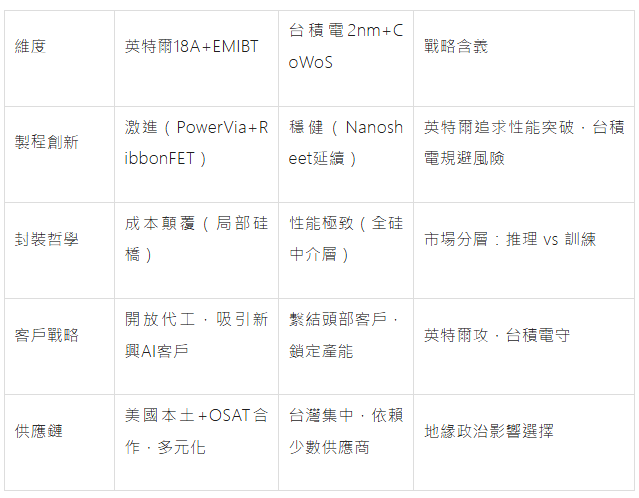
技術術語表
GAA(Gate-All-Around):全環繞柵極電晶體,溝道被柵極四面包裹,解決短溝道效應
PowerVia/BSPDN:背面供電網路,將PDN移至晶圓背面,提升布線效率和供電完整性
EMIB/EMIBT(Embedded Multi-die Interconnect Bridge):嵌入式多晶片互連橋,局部矽橋實現芯粒間高速互連
CoWoS(Chip-on-Wafer-on-Substrate):台積電2.5D封裝技術,通過矽中介層整合多晶片
HBM(High Bandwidth Memory):高頻寬記憶體,通過TSV堆疊實現超高記憶體頻寬
UCIe(Universal Chiplet Interconnect Express):開放芯粒互連標準,支援CXL協議
DTCO(Design-Technology Co-Optimization):設計技術協同最佳化,提升PPA和良率 (semiboss)