
五一期間,在使用AI軟體的時候,需要記憶(長期上下文、工具呼叫歷史、使用者偏好),而且對於資料的記憶要求很高,隨時可以呼叫。不止是能存上下文,而且需要存一下檔案和各種複雜模型結構。
所以當看到孫宇晨去年說這個話的時候,反覆在思考,前面兩者敘事都兌現了,接下來可能是儲存了。對儲存類股,做基礎梳理。
第一層:短期缺晶片
為什麼是"短期"?
缺晶片本質是個產能問題,產能問題是可以用錢和時間解決的。
- GPU/AI晶片擴產周期2-3年,台積電CoWoS封裝產能已經在爬坡
- 輝達從H100→H200→B200,供給量每個季度都在增加
- 晶片短缺更多是結構性的:高端AI晶片缺,成熟製程並不缺
為什麼正在緩解?
- 台積電2025年CoWoS月產能已從8千片擴到3萬片+
- 輝達供應逐步放量,部分客戶已不用排6個月隊了
- AMD MI300、國產算力晶片在補位
所以"短期缺晶片"的判斷是對的——這是個可解的瓶頸,只是需要時間。
第二層:長期缺能源
為什麼是"長期"?
能源和晶片不一樣,不是投錢就能快速擴出來的。
算力的盡頭是電力——這不是比喻,是物理事實:
- 一台H100功耗700W,一個萬卡叢集就是7MW
- 一個大型AI資料中心功耗50-200MW,相當於一個中等城市的用電量
- OpenAI的Stargate項目規劃5GW,相當於5座核電站
2025-2026年的現實:
- 美國資料中心用電已佔全國8-10%
- 弗吉尼亞州(全球最巨量資料中心聚集地)已經出現電力供應排隊現象
- 愛爾蘭資料中心用電佔全國20%,政府被迫限制新建
- 中國內蒙古、寧夏等地區靠電力成本低吸引資料中心,但也在逼近電網承載極限
為什麼短期解不了?
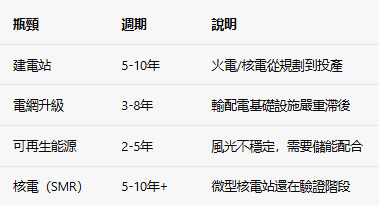
微軟、亞馬遜已經開始直接投資核電站,就是因為等不了電網——科技公司在為能源搶跑,這在歷史上是第一次。
更深一層:能效比的天花板
摩爾定律在減速,但算力需求在指數增長,中間的gap只能靠堆晶片,堆晶片就是堆電力:
算力需求:每年 4-10x 增長
晶片能效:每年 1.5-2x 改善
電力缺口:≈ 每年 2-5x 的gap
→ 唯一出路:要麼突破架構(存算一體、光計算)
要麼突破能源(可控核聚變、SMR)
都是10年+的事
所以"長期缺能源"也是對的——這不是產能問題,是物理限制+基礎設施周期問題。
第三層:永遠缺儲存——這是最深刻的一句
為什麼是"永遠"?
儲存的特殊性在於:資料只增不減,而儲存容量始終有限。
資料的本質特徵——單向膨脹:
文字時代: 一本書 ≈ 1MB
圖片時代: 一張照片 ≈ 5MB
視訊時代: 一部4K電影 ≈ 100GB
AI時代: 一個大模型訓練資料集 ≈ 數十TB
推理產生的中間資料 ≈ 持續增長
資料增長速度:每年 60-80%(IDC)
儲存密度增長:每年 15-20%
→ gap永遠存在
從AI的視角理解"永遠缺儲存"
AI讓儲存需求發生了質變,不是"用得多",而是每次迭代都在重新定義"多":
1. 訓練階段:資料饑荒
- GPT-4訓練資料約13兆token,人類高品質文字快被"吃"完了
- 多模態AI需要海量圖像/視訊資料,網際網路公開資料不夠用了
- 合成資料是方向,但合成資料本身又需要儲存
2. 推理階段:KV Cache是無底洞
- 每次推理都需要快取上下文(KV Cache),上下文越長,儲存需求越大
- 從4K→128K→1M context length,KV Cache儲存需求增長250倍
- 這不是一次性的,是每次推理都在產生
3. 模型本身在變大
- GPT-4參數量約1.8兆,儲存需數TB
- 多模態模型(視訊生成等)參數量更大
- 每個版本迭代,模型體積增加5-10倍
4. AI Agent時代:儲存需求再翻倍
- Agent需要記憶(長期上下文、工具呼叫歷史、使用者偏好)
- 每個Agent都像一個"數字人",需要自己的儲存空間
- 未來可能有數十億個Agent同時運行——儲存需求根本無法預估
為什麼儲存的"缺"和晶片、能源不一樣?

晶片缺的是"產能"——造出來就不缺了
能源缺的是"功率"——建出來就夠用了
儲存缺的是"空間"——資料永遠在增長,空間永遠不夠
這就是為什麼說"永遠"——儲存的短缺不是周期性的、不是結構性的,而是資訊理論意義上的本質特徵。
一個思想實驗
想像你有一塊1TB的硬碟:
- 2020年:夠存20萬張照片,覺得綽綽有餘
- 2023年:一個AI模型就佔了2TB,硬碟直接不夠了
- 2025年:一段4K視訊就200GB,1TB存5個就滿了
- 2027年:你的個人AI Agent運行資料,一年就產生10TB
儲存的增長是追趕遊戲,而資料增長永遠快於儲存密度增長。
三層瓶頸的遞進關係
這三句話不是並列的,而是遞進的因果關係:
晶片(算力)→ 消耗能源 → 產生資料 → 需要儲存
短期:卡在算力不夠(GPU買不到)
↓ 算力解決了
長期:卡在能源不夠(電不夠用)
↓ 能源勉強跟上了
永遠:卡在儲存不夠(資料永遠比容量增長快)
換個角度理解:
- 晶片是入口——沒有算力,什麼都不會發生
- 能源是燃料——有了算力,需要電力驅動
- 儲存是沉澱——算力跑過的每一秒,都在產生需要永久保存的資料
而儲存的特殊性在於:晶片可以復用、能源可以循環,但資料只會累積。
對投資和產業的啟示
- 晶片短缺是買點訊號——可解的瓶頸意味著確定性機會,但窗口有限
- 能源短缺是長線邏輯——資料中心電力、核能、儲能、液冷都是5-10年賽道
- 儲存短缺是終極敘事——HBM、3D NAND、存算一體、光儲存,永遠有增量需求
孫宇晨這句話的精髓在於:大多數人還在討論第一層(晶片)的時候,應該去看第二層(能源);當大家都意識到第二層的時候,真正的終極答案是第三層(儲存)。
儲存是AI時代唯一一個"需求永遠大於供給"的環節——這也就是為什麼前面聊的儲存晶片超級周期,可能不是一個3-5年的周期,而是一個結構性的長期趨勢。 (官山河)