
Cerebras這顆晶片,
不需要HBM。
一顆都不要。
一片晶圓,不切割,不封裝,整片做成一顆晶片。這條路一旦走通,整條儲存產業鏈的蛋糕切法,就要重新算了。
4兆 電晶體 | 90萬 計算核心 | 44GB 片上SRAM | 0 HBM
5月14日,這家叫Cerebras的公司在納斯達克上市,首日漲了109%,市值衝到千億美元。市場在押注一件事:AI晶片,不一定非要走輝達那條路。
一片46,225平方毫米的矽晶圓。不切割,不封裝,整片做成一顆晶片。
4兆個電晶體。90萬個計算核心。44GB片上記憶體。
沒有1GB的HBM。一顆都沒有。
真正值得關注的不是股價。是這條路一旦走通,整條儲存產業鏈的蛋糕切法,就要重新算了。
為什麼?先講個比喻。
你開了一家餐館。後廚到食材倉庫有50米,每天廚師有一半時間在走路。你想了個辦法:在灶台旁邊裝了個冰櫃,食材伸手就能夠到。雖然冰櫃不大,只能放當天的料,但廚師不用走路了,出菜速度翻了三倍。
傳統GPU配HBM,等於把倉庫搬到離廚房10米遠,還是得走。Cerebras不走了,直接把食材放灶台上。
但這個冰櫃只有44升。隔壁輝達的冷庫有192升。
這就是晶圓級晶片和GPU之間最根本的差異。不是改良,是換了一條完全不同的路。
三種蓋樓方式,三種材料供應商
AI晶片要解決的核心矛盾叫"儲存牆":計算核心跑得飛快,但資料從記憶體搬過來太慢了。打個比方,你有一百個工人蓋樓,但磚頭堆在街對面,工人大部分時間在搬磚而不是砌牆。
行業走出了三條路。
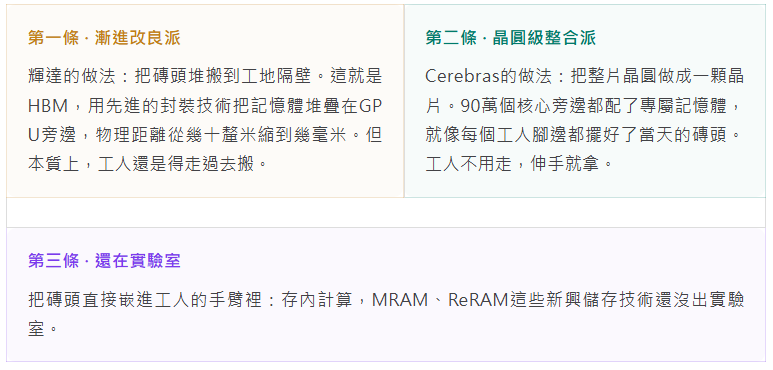
輝達的方案養活了SK海力士、三星、美光這一整條HBM產業鏈。SK海力士靠HBM做到了79%的毛利率,比輝達自己還高。因為HBM不是普通記憶體,製造難度極高,全球只有三家能做,是AI晶片供應鏈裡最肥的一塊肉。
Cerebras的方案呢?它根本不需要HBM。一顆都不要。它的44GB記憶體是直接刻在晶片上的SRAM,由台積電在製造晶片的時候一起做進去。錢不是付給海力士,是付給台積電的晶圓廠。整條HBM產業鏈跟它沒關係。
這才是需要認真看的地方。不是說Cerebras現在就能挑戰輝達,它一年營收才51億美元,輝達資料中心業務1300億。但如果晶圓級整合這條技術路線在AI推理市場站穩了腳跟,每多一塊晶圓級晶片,就少一份HBM的需求。
就像電動車不需要變速箱。不是一夜之間取代燃油車,而是每多賣一輛電動車,變速箱供應鏈就少一個客戶。
44GB夠不夠用?再講個比喻
你有一萬本書要查。輝達的方案是:在你辦公室隔壁建了個圖書館,192排書架,走路10秒就到,隨時查閱。
Cerebras的方案是:你桌上只有一個小書架,只能放10本書。但配了一個跑得飛快的圖書管理員,他一看到你需要那本書,就從遠處的大倉庫裡跑著給你送過來,快到你感覺不到等待。
這就是Cerebras的"權重流"技術。模型參數存在晶片外面的MemoryX伺服器裡,需要那一層就流式載入進來。晶片上那44GB不是用來裝整本書的,是用來裝正在翻閱的那幾頁。
但這有個硬傷。你桌上只有10本書的空間,如果你想同時對照翻閱20本書的不同章節(這就是大模型的"長上下文"),就放不下了。所以Cerebras目前最大隻能支援128K的上下文長度。而輝達的B200可以支援百萬token等級。

短上下文場景,比如ChatGPT回答一個問題、寫一段程式碼、翻譯一篇文章,Cerebras的速度確實快得離譜,比GPU方案快15倍。但長上下文場景,比如分析一份幾百頁的招股書、處理一整天的會議記錄,目前還是得靠HBM。
只要大模型需要長上下文,HBM就有護城河。這句話反過來也成立:如果未來的AI應用大部分是短上下文的高頻推理,那Cerebras的優勢就會持續放大。
對儲存產業鏈的三層衝擊
把上面這些技術差異翻譯成產業鏈語言,會產生三層傳導。
1 HBM製造商:增量市場被切走一塊
現在AI晶片的增長主要靠推理,訓練的比例在逐步下降。推理市場又分兩塊:即時互動(短上下文,比如聊天機器人)和深度分析(長上下文,比如研報解讀)。
Cerebras拿手的是第一塊。這塊市場越大,晶圓級晶片滲透率越高,相應的HBM需求量就越少。這不是存量替代的邏輯,是增量分流的邏輯。
推理需求增長→短上下文流向晶圓級→不需要HBM→HBM增速低於AI晶片出貨
對SK海力士來說,短期感受不到,因為它現在的訂單積壓超過三年。但兩三年後,如果推理市場出現明顯的技術路線分化,新增產能的投向就需要重新算了。
2 SRAM設計工具和IP:蛋糕換了一張桌子
HBM的產業鏈分工很清晰:海力士造記憶體,台積電做封裝,輝達做整合。三家分錢,各賺各的。
晶圓級晶片把儲存和計算刻在同一片矽上,這個分工就不存在了。受益方從"獨立儲存器製造商"變成了"晶圓廠+設計工具商"。晶片設計公司需要更先進的SRAM IP(比如每個核心旁邊的48KB分佈式SRAM怎麼設計、怎麼互聯),也需要更強大的EDA工具來模擬整片晶圓的訊號完整性。
受益的變成了ARM、Synopsys、Cadence這些IP和工具廠商。不是同一撥人。
3 新興儲存技術:可能等到第一個規模場景
Cerebras的權重流架構,要求有一個外部儲存器(MemoryX)來存放那些裝不進44GB SRAM的模型參數。這個外部儲存器需要三個條件:頻寬極高、容量極大、功耗低。
目前能選的方案都不理想。DRAM頻寬不夠,SSD延遲太高,HBM太貴。
MRAM和ReRAM正好卡在中間。比DRAM快,比SRAM容量大,非易失(斷電不丟資料)。它們在實驗室裡躺了很多年,一直沒找到大規模商業化場景。晶圓級晶片的MemoryX需求,可能是它們第一個真實的應用落點。

當然,這個傳導要落地,前提是晶圓級晶片本身先放量。這是後話,但方向值得關注。
晶圓級路線在中國意味著什麼
Cerebras的技術路線,理論上給中國AI晶片行業提供了一個思路:如果HBM供應鏈受限,能不能走一條不需要HBM的架構路徑?
但這個思路要落地,目前還隔著一道檻:先進製程。WSE-3用的是台積電N5工藝,整片晶圓的良率挑戰極大。一片12英吋晶圓上只要有幾個缺陷點,整顆晶片就廢了。Cerebras靠的是1.5%核心做冗餘備份、再加上軟體層面的容錯機制,才把良率拉到可用水平。
中國目前還沒有這個製程節點的產能。晶圓級路線對中國來說,是一個值得跟蹤的技術方向,但離落地還有距離。
兩張桌子
HBM這樁生意,全球有三家公司在做,毛利率比輝達還高,因為AI晶片現在離不了它。
Cerebras的出現,等於有人在問一個很根本的問題:能不能做一種AI晶片,完全不用HBM?
技術上說,可以。44GB的片上SRAM加權重流架構,跑短上下文推理確實比GPU方案更快。但從"技術上可以"到"商業上大規模替代",中間還隔著良率、生態、上下文天花板這幾道檻。
對儲存產業鏈來說,最值得關注的不是Cerebras這家公司本身。而是它打開了一個新的技術方向。這個方向上,蛋糕的切法和原來完全不一樣了。
原來只有一張桌子:HBM + GPU。SK海力士、三星、台積電、輝達,四家分錢。
現在可能要多出一張桌子:晶圓級晶片 + MemoryX。台積電一家吃掉儲存和製造兩塊,再加新興儲存器(MRAM/ReRAM)分MemoryX的蛋糕,HBM供應商暫時安全,但增量空間被切走一塊。
兩張桌子並排擺著。那張將來坐的人多,現在還沒定。但產業鏈上的錢,已經開始往第二張桌子移動了。 (觀瀾Horizon)