
華為技術 | 戰略前沿
半導體演進的新路徑
從幾何縮放到時間縮放
六年、381款晶片——華為如何在物理極限邊緣找到下一條路
邏輯折疊 · 麒麟2026 · Tau縮放 · 華為戰略前沿
"空間和時間是同一枚硬幣的兩面。失去幾何縮放,並不意味著失去時間縮放。"
—— 華為半導體戰略演講
摩爾定律曾是半導體行業最美的預言:每隔兩年,電晶體數量翻倍,性能翻倍,成本減半。這個規律運轉了半個世紀,將人類文明拉進資訊時代。
但在7奈米節點之後,這條路開始縮小。最先進的光刻機越來越稀缺,幾何縮放的成本越來越高,行業開始感受到一堵看不見的牆。那麼,晶片的演進就此停止了嗎?
過去六年,華為給出了自己的答案:從幾何縮放(Spatial Scaling)轉向時間縮放(Tau Scaling),以"時間"作為整個電子系統演進的新坐標軸。今天這篇文章,將帶你完整理解這條新路徑——它是什麼、為什麼有效,以及它將如何重塑從智慧型手機到AI資料中心的整個晶片世界。
一|幾何縮放走到了那裡?
摩爾定律的本質,是幾何縮放:不斷縮小電晶體的物理尺寸,在同樣面積上塞入更多電晶體。FinFET架構的出現,將這條路又向前延伸了十年。
但幾何縮放從未只是"縮小"。它一直在追求的,是時間域的收益——更快的電晶體、更短的響應時間、更高的晶片主頻。換句話說,空間縮放本就是時間縮放的一種實現手段。
🌟 金句
"空間和時間是同一枚硬幣的兩面。失去幾何縮放,並不意味著失去時間縮放。
我們提出將從幾何縮放向時間縮放(Tau縮放)的轉變,作為電子系統演進的新指導原則。"
📌 核心概念 · Tau縮放
Tau(τ)等於RC的乘積——電阻(R)與電容(C)共同決定了電路的響應時間。Tau縮放的核心思路:即便不縮小物理尺寸,也可以通過降低RC寄生效應來提升性能。從裝置到電路,再到晶片和系統,這一原則跨越從皮秒到秒共12個數量級的時間範圍。
在裝置層面,高K金屬柵極(HKMG)、應變矽等技術,早已證明了不依賴幾何縮小也能提升性能。在電路層面,減少互連RC寄生效應和流水線深度,同樣是直接壓縮Tau的有效手段。
二|邏輯折疊:在飽和區內找到突破口
在移動端,麒麟晶片面臨的困境更具體。智慧型手機就是一顆單晶片構成的完整系統,沒有多餘的空間堆砌外設。按照業界普遍預期,經歷幾代迭代之後,晶片性能應該趨於飽和。
🌟 金句
"不是飽和,不是簡單的延續,而是向前的一大步。
在以Tau為中心的指導原則下,我們找到了新的路徑——邏輯折疊。"
多裸片封裝並不新鮮。業界的HBM、3D V-Cache、微凸塊等技術,已經在頻寬和延遲方面取得了顯著進步。但對於麒麟而言,僅靠這些還不夠。華為需要的是一種從電路設計根本層面出發的新方法。
📌 產品技術亮點 · 邏輯折疊(Logical Folding)
定義:遵循時間縮放原則,邏輯折疊是一種全新且具有普適性的數位電路與系統設計方法論。它跨越垂直堆疊的有源層來綜合數字系統,聯合且持續地最佳化功耗、性能、密度和成本。
核心機制:將關鍵路徑門電路分佈在不同平面上,縮簡訊號連線,降低寄生RC效應,使時鐘變異急劇下降,關鍵路徑縮短,晶片運行更快。
混合鍵合間距:邏輯折疊的物理基礎
要實現有效的邏輯折疊,需要極激進的混合鍵合(Hybrid Bonding)間距。經過大量試驗,華為團隊確定了一個關鍵比例:混合鍵合間距與頂部金屬間距之比須小於3。
當今頂部金屬間距約為720奈米,這意味著混合鍵合間距須小於2微米。就在跨過這道門檻的那一刻,邏輯折疊的奇蹟才真正成為可能。
📌 產品技術亮點 · 混合鍵合工藝指標
混合鍵合間距:已實現 1.5微米(明年將達到1微米)
對準覆蓋誤差:小於0.5微米
良率:借助智能冗餘技術達到 100%
TSV關鍵尺寸與禁區:縮小至1.5微米以下
TSV間距:小於6微米,故障率低於百萬分之一百,修復率 99.9%
三|麒麟2026:資料說話
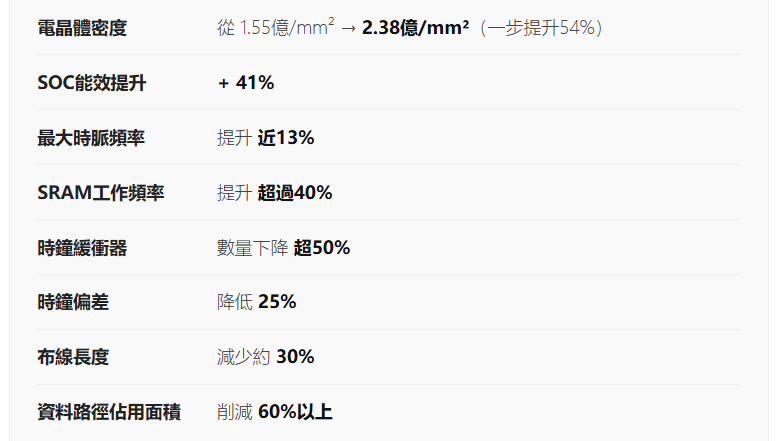
麒麟2026,計畫於2026年秋冬推向市場。這是華為首次成功實現邏輯折疊的量產晶片,從單層架構擴展到雙層架構。它不是一個漸進式的小步,而是在密度、能效、頻率三個維度上同步躍升。
🌟 金句
"在邏輯折疊之前,我們需要3年時間才能將電晶體密度從1.26億提升到1.55億。
而在2026年,邏輯折疊技術只需一步,就將其直接提升到了每平方毫米2.38億個電晶體。"
SRAM:一個電路折疊的具體案例
SRAM的性能不僅取決於電晶體本身。對於一個1兆位元的SRAM,互連延遲和通訊延遲佔總延遲的70%以上——而這正是Tau縮放可以直接作用的地方。
通過邏輯折疊:縮減位元陣列與外圍電路之間的距離(縮短關鍵路徑)、最佳化每個元件的RC。結果:訪問延遲降低、每位元能耗下降、工作頻率提升超40%。這在先進節點中是一個極難實現的數字。
📌 產品技術亮點 · CPU性能核心頻率展望
基於Tau縮放路徑,CPU性能核心頻率將於 2031年突破5 GHz。
麒麟SOC能效將在 3到5年內實現翻番(相同功耗下)。
🌟 金句
"我曾經以為這可能需要10年,但僅用了6年,我們做到了。
麒麟2026僅僅是個開始。"
四|AI系統:Tau縮放的千兆瓦級應用
有人會問:在毫瓦級的智慧型手機裡奏效的Tau縮放,能在千兆瓦級的AI資料中心裡同樣有效嗎?
答案是肯定的——但挑戰的量級截然不同。AI訓練和推理高度平行,動輒數千顆晶片協同運轉,超過80%的能源消耗在移動資料上,超過70%的成本用於儲存資料。因此,勝負不在於算得有多快,而在於資料移動得有多快。
統一匯流排(UB):讓萬卡叢集像單晶片一樣通訊
📌 產品技術亮點 · 統一匯流排(Unified Bus)
核心理念:統一整個電腦系統的互連,在盒子內部和外部使用相同的協議和硬體。
記憶體語義(Memory Semantics):跨層資料傳輸無需經過複雜協議轉換,實現免轉換的點對點傳輸。
效果:通過完全的點對點UB架構,打造"系統即單晶片"的極低延遲Tau系統。
High One:突破電纜瓶頸的光學引擎
當AI晶片頻寬擴展到每秒數太位元(Terabit)時,傳統電纜變得笨重、高能耗、傳輸距離極短。華為開發的High One光學引擎解決了這一瓶頸:
📌 產品技術亮點 · High One光學引擎
單個 High One 提供 8 Terabit 頻寬,與一顆AI晶片的統一匯流排頻寬精確匹配。
覆蓋範圍從不到1米擴展至 100米,讓千兆瓦級分佈式資料中心的高密度互連成為物理現實。
消除笨重電纜,對功耗和散熱極為友好。
系統折疊:破解扇出困境
在物理層面存在一個"扇出困境":晶片的計算能力按 N² 縮放,但沿邊緣排布的記憶體頻寬、互連和供電只能按 N 線性縮放。這條二次曲線與線性曲線之間不斷擴大的鴻溝,是制約2.5D縮放的根本障礙。
系統折疊打破了這一困境:將供電、高速記憶體和光學IO移動到晶片垂直方向,使這三者也能呈 N² 縮放,與計算能力同步增長。
📌 產品技術亮點 · 昇騰AI系統路線圖
昇騰910C:已上市,開啟超級節點時代
昇騰950:2026年,將博弈帶到新高度
全面邏輯折疊版昇騰:2030年前後推出,帶來另一次性能巨大飛躍
2035年硬體整合度:預計較當前提升 100倍以上
五|未來十年:路線圖與挑戰
華為的團隊深知,前路並不平坦。兩大核心挑戰擺在眼前:
挑戰一:工具鏈傳統EDA工具尚不支援全尺寸的自由邏輯設計。華為已完成初步開發,並公開邀請行業合作夥伴和專家加入,共同推動未來改進。
挑戰二:熱管理熱壓力橫跨從毫瓦到千兆瓦的12個數量級。需要控制和最佳化熱阻與熱傳導,期待與行業同仁共同應對。
2026—2035 電晶體密度演進路徑
沿著Tau縮放路徑,過去六年的實踐交付了清晰的資料:基於製造標準的電晶體密度從 1.5億/mm² 攀升至 2.4億,甚至 3億/mm²,並正在迅速逼近 4億/mm²。SOC有效電晶體密度已達到每平方毫米超過2.5億。
邏輯折疊的演進路徑同樣清晰:從今天的局部關鍵路徑折疊,邁向全尺寸及多層折疊,最終實現從裝置到系統的全端最佳化。
🌟 金句
“通過實踐,我們已經證明了Tau縮放路徑是可行、普適且可持續的。
持久的成功將屬於那些能夠融合邏輯和記憶體的人。”
📌 技術路線圖 · 2026—2035 關鍵里程碑
2026年 → 麒麟2026上市,首款邏輯折疊量產晶片
2027年 → 混合鍵合間距縮小至 1微米
2030年前後 → 全面邏輯折疊版昇騰發佈
2031年 → CPU性能核心頻率 突破5 GHz
2035年 → AI硬體整合度較2025年提升 100倍以上
尾聲|六年、381款晶片
在這篇演講的最後,有一組樸素的數字:六年,381款晶片,服務於不同的行業部門、市場和客戶。
這背後是無數工程師在幾何極限的邊緣,一條一條驗證著新的路徑。Tau縮放不是一句口號,而是一套被產品逐一檢驗過的方法論。
華為的願景——“把數字世界帶入每個人、每個家庭、每個組織,建構萬物互聯的智能世界”——這句話的實現,需要晶片持續進化作為底座。而邏輯折疊,正是這條進化曲線上一個新的拐點。 (The AI Frontier)