
AI 算力市場越來越大,真正值得看的不是“誰打敗輝達”,而是預算正在怎樣被不同層級的公司分走。
討論 GPU 公司,不能只看誰的晶片參數更強。
因為今天的輝達,早就不是一家簡單的“顯示卡公司”。它賣的是 GPU,也是 CUDA,是伺服器,是網路,是一整套 AI 資料中心基礎設施。
最新一個季度,輝達 2027 財年第一季度總收入達到 816 億美元,其中資料中心收入有 752 億美元,同比增長 92%。單季度 752 億美元的資料中心收入,已經足夠說明這麼個事兒:AI 算力市場的第一張桌子,還牢牢地被輝達把控著。
所以這篇文章真正要回答的,不是“誰能打敗輝達”。這個問題太簡單,也太容易寫成標題黨。
更值得看的問題是:當 AI 算力市場大到今天這個規模,預算會怎麼分流?那些公司正在從不同層級,切走原本屬於 GPU 的那部分錢?
換句話說,輝達之外,全球 GPU 和 AI 加速晶片市場,正在形成一張新的分層地圖。
真正值得看的問題不是“誰打敗輝達”,而是 AI 算力預算會怎樣分流。
先說清楚:本文裡的 GPU 是廣義口徑
嚴格來說,Cerebras、Groq、Google TPU、AWS Trainium 都不是傳統 GPU。
但如果只按傳統 GPU 來寫,這篇文章會變得很窄,只剩 Nvidia、AMD、Intel 和少數中國 GPU 公司。
問題是,AI 算力市場的競爭早就不只是發生在 GPU vs GPU 之間,好多公司可不只想做另一個輝達 GPU,而是打算在訓練、推理、雲端部署、國產替代、低成本服務這些場景裡,躲開 GPU 的傳統路子。
所以本文中的“GPU 公司”採用廣義口徑,包括四類:資料中心 GPU、GPGPU、AI 加速器、推理專用晶片,以及雲廠商自研 AI 晶片。
這個口徑先放在前面,後面就不會把所有公司都硬塞進“顯示卡公司”的框裡。
本文中的“GPU 公司”採用廣義口徑:資料中心 GPU、GPGPU、AI 加速器、推理專用晶片,以及雲廠商自研 AI 晶片。
一、正面競爭者:最現實的是 AMD,不是“下一個輝達”
要是只看全球市場,目前真正能在資料中心 GPU 上正面跟輝達叫板的公司還挺少的。
AMD 是最現實的第二供應商。Intel 有資料中心基礎,但 AI 加速器敘事沒有完全跑順。Qualcomm 則不是傳統 GPU 玩家,而是試圖從推理端切進去。
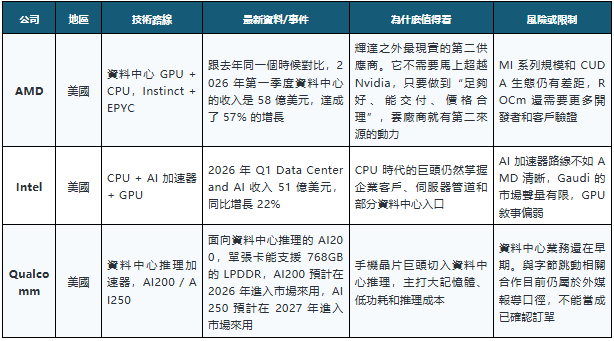
這一組裡面,AMD 最值得重點看。
它並不是要在所有指標上打贏輝達,而是要成為大客戶的“第二選擇”。對於雲廠商來說,只依賴一家供應商風險太高。只要 AMD 的性能、軟體、供貨和價格進入可接受區間,它就有機會分到一部分訓練和推理預算。
這和手機行業有點像:不是每個Android晶片都要正面打敗蘋果 A 系列,但只要市場足夠大,第二供應商就有自己的位置。
Intel 的問題比較複雜。它有資料中心的根基,還有製造和企業客戶的優勢,但是在 AI GPU 這條線上,市場對它的想像明顯比 AMD 弱,它更像是在守住資料中心的入口,而不是主動去改寫 AI 算力的格局。
Qualcomm 則是另一種變數。它不是來做訓練 GPU 的,而是想切推理成本。AI 推理和訓練不同,訓練要追求大規模平行和通用能力,推理更關心延遲、吞吐、功耗和單位 token 成本。如果未來大模型進入高頻呼叫階段,Qualcomm 這種低功耗推理路線就值得單獨看。
這一組怎麼看:AMD 爭的是第二供應商,Intel 爭的是資料中心入口,Qualcomm 爭的是推理成本。
二、中國 GPU / AI 晶片公司:窗口打開了,但不等於全面追平
中國這條線,是全文最特殊的一組。
它不是單純的技術路線競爭,而是技術、政策、供應鏈安全和本土客戶需求共同推動的結果。
根據 Reuters 引用 IDC 資料的報導,2025 年中國 AI 加速卡總出貨約 400 萬張,其中 Nvidia 約 220 萬張,份額約 55%;中國廠商合計約 165 萬張,份額約 41%。其中,華為約 81.2 萬張,阿里平頭哥約 26.5 萬張,百度崑崙芯和寒武紀各約 11.6 萬張。
這個資料的含義很明確:國產 AI 晶片已經不只是概念,而是開始進入真實出貨和真實訂單階段。
但也要把話說完整。份額提升,不等於性能全面追平。國產替代的背後,有出口管制帶來的供給缺口,也有本土政企客戶對供應鏈安全的需求,還有國內智算中心建設帶來的訂單窗口。
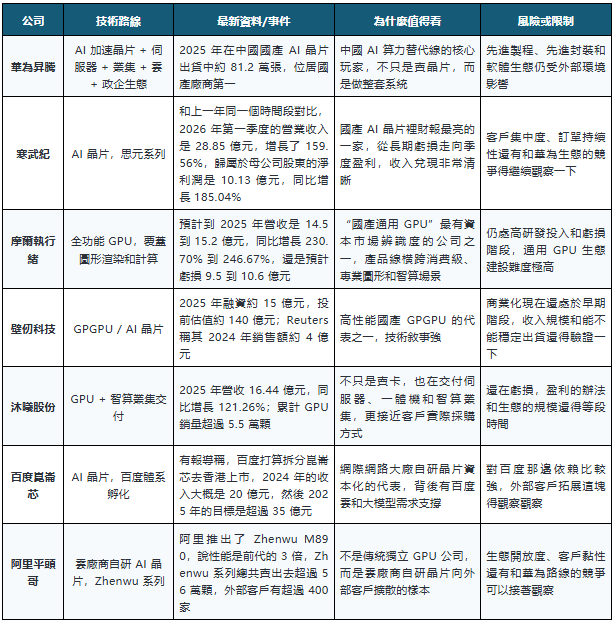
這一組最值得重點寫的是三家公司:華為、寒武紀、摩爾線程。
華為是個系統級的玩家。它的優勢可不只在晶片這一塊,而是在“晶片加上伺服器加上叢集加上雲還有政企管道”的一整套能力。對於政企客戶還有智算中心來講,他們買的通常可不只是一顆晶片,而是一套能交付、能部署、能維運的方案。
寒武紀的亮點在財報。很多國產晶片公司過去的問題是“技術故事很強,收入兌現很慢”。寒武紀最新季度營收和利潤同時上來,說明它至少已經跨過了“有沒有真實訂單”這一關。
摩爾線程更像是國產通用 GPU 的代表。它的敘事可不只是 AI 加速器,而是更接近輝達早期那種圖形、計算、生態一塊兒做的路子,不過這條路也最難,因為通用 GPU 比拚的不只是晶片性能,還有驅動、編譯器、開發者生態、遊戲和專業軟體適配。
這一組怎麼看:國產替代已經進入真實出貨階段,但它首先是窗口期和供應鏈安全邏輯,不應簡單理解為性能全面追平。
三、繞開 GPU 的公司:推理晶片正在另起一條路
這一組最有資訊差。
普通讀者聽到 AI 晶片,第一反應通常是 Nvidia、AMD、Intel。但真正有意思的變化,是很多公司壓根不想做傳統 GPU。
它們盯上的不是訓練,而是推理。
訓練階段,晶片得處理大規模平行計算,得追求通用性、穩定性還有生態成熟度,到了推理階段,情況就不一樣:每次回答得有多快,每生成一個 token 得花多少錢,能耗能不能降下來,記憶體頻寬夠不夠?
當 AI 應用從“訓練大模型”走向“每天被幾億次呼叫”,推理成本會變成一門很大的生意。
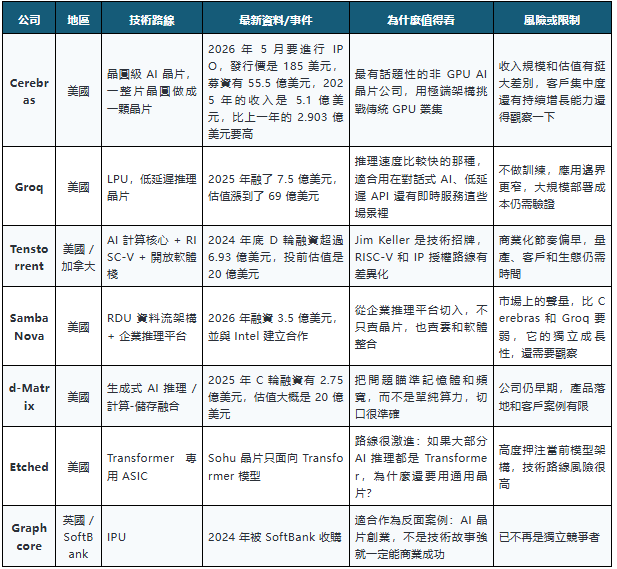
這一組的關鍵詞是:不做 GPU,但搶 GPU 的錢。
Cerebras 用特別大的晶片架構,試著減少傳統叢集裡的通訊瓶頸;Groq 把低延遲推理當作賣點,讓開發者在體驗上直接感覺到“快”。
這類公司不一定會成為下一個輝達,不過,它們將會一直製造壓力,特別是在推理方面。如果某個場景對於延遲、成本或者能耗比較在意,這樣客戶就會有動力去嘗試不是輝達的方案。
這一組怎麼看:訓練市場仍然高度依賴 Nvidia,推理市場則更可能出現專用晶片窗口。
四、雲廠商自研晶片:最大的客戶也在下場
這部分不需要寫太長,但必須出現。
因為從長期看,輝達最大的壓力不一定來自另一個 GPU 公司,而可能來自客戶自己。
Google、Amazon、Microsoft、Meta 都在做自研 AI 晶片。它們的目的不是公開賣卡賺錢,而是降低自己的 AI 服務成本。
對於雲廠商來說,AI 基礎設施投入已經是百億美元甚至千億美元等級的支出。只要自研晶片能把單位推理成本、訓練成本或能耗降下來,省下來的錢就非常可觀。
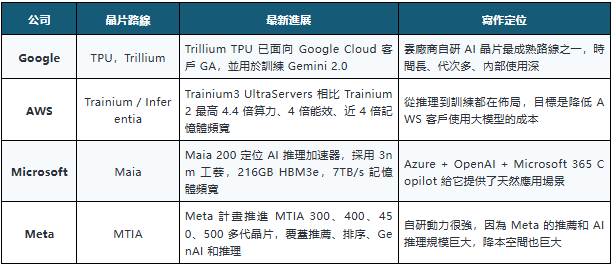
雲廠商自研晶片的邏輯很直接:不是為了替代所有輝達 GPU,而是為了把一部分可預測、規模化、重複運行的任務遷移到自己的晶片上。
比如說像推薦系統、廣告排序、內容分發還有固定模型推理這類任務,一旦處理規模到了一定程度,自己研發的晶片比較有可能達到成本效益。
它們不會立刻取代輝達。訓練最前沿模型,輝達仍然有很強的生態和性能優勢。但雲廠商自研晶片會改變輝達的議價環境。
以前客戶只能排隊去買 GPU。以後大客戶可能會說,最關鍵的訓練我接著買,不過有一部分推理和內部負載,我能自己弄。
這一組怎麼看:雲廠商自研晶片不是為了賣給別人,而是為了降低自己的 AI 成本。它們短期不顛覆 Nvidia,長期會削弱 Nvidia 的定價權。
結論:輝達不是被替代,而是被分層競爭包圍
把這幾組公司放在一起看,就能發現一個很清楚的變化:
輝達面對的不是某一個“挑戰者”,而是一張從不同方向收緊的網。
AMD 爭的是第二供應商。它最現實,也最直接。只要雲廠商不想完全依賴 Nvidia,AMD 就有機會。
中國廠商爭的是國產替代。這條線是由出口管制、本土客戶、政企採購還有智算中心建設一起推動的。華為是系統級的玩家,寒武紀開始實現收入了,摩爾線程和沐曦則在通用 GPU 和智算方面。
輝達仍然是第一張桌子的主人,但越來越多公司正在從第二供應商、國產替代、推理晶片和雲廠商自研四個方向分走預算。 (硅基代謝)