

自美國OpenAI公司推出的ChatGPT風靡全球,並引發新一輪人工智慧浪潮,國內外科技巨頭爭相佈局大模型領域。
此次,鈦媒體AGI梳理了2023年至今,阿里、百度、字節、騰訊、華為、小紅書、美圖、科大訊飛、三六零8家互聯網科技公司在AI 領域的最新技術成果,共包含50款AI大模型及AI應用,以幫助讀者快速了解網路大廠在AI領域的最新技術動向。
阿里巴巴 2024年3月
中國版“Sora”,文生視訊框架—— AtomoVideo
產品介紹: AtomoVideo是阿里巴巴推出的一個高保真影像視訊生成框架,該框架利用高品質的資料集和訓練策略,保持了時間性、運動強度、一致性和穩定性,並具有高靈活性,可應用於長序列視訊預測任務。
因與Open AI先前推出的文生視訊模型Sora功能相似,AtomoVideo也被稱為「中國版Sora」。
產品功能:使用者只需上傳一張照片就能產生對應的影片。據悉AtomoVideo的核心在於多粒度影像注入技術,這項技術使得生成的影片對於給定的影像具有更高的保真度,能夠更好地保留原始影像的細節和特徵,從而使得生成的影片更加逼真。

另外,AtomoVideo的架構也具有很高的靈活性,它可以靈活地擴展到視訊幀預測任務,透過迭代生成實現長序列預測,使得AtomoVideo在處理長序列的視訊預測任務時,也能夠保持良好的效能。
目前,阿里只發布了AtomoVideo的論文,程式碼,試玩頁面還未公佈。
適用人群或場景:影片創作者、影視拍攝
論文網址:https://arxiv.org/abs/2403.01800
電商人的AIGC創作平台-繪蛙
產品介紹:繪蛙是阿里AI電商團隊針對淘寶、電商達人推出的一款可以產生文案和圖片的智慧創作平台,旨在提升電商行銷效率。
產品功能:主要是AI文案產生和AI圖片生成。在AI文案中,商家可以實現單商品種草、小紅書爆文改寫、穿搭分享等。以爆文改寫為例,商家只要輸入參考筆記內容,然後加入種草商品賣點、人設、筆記話題,即可產生小紅書風格文案。
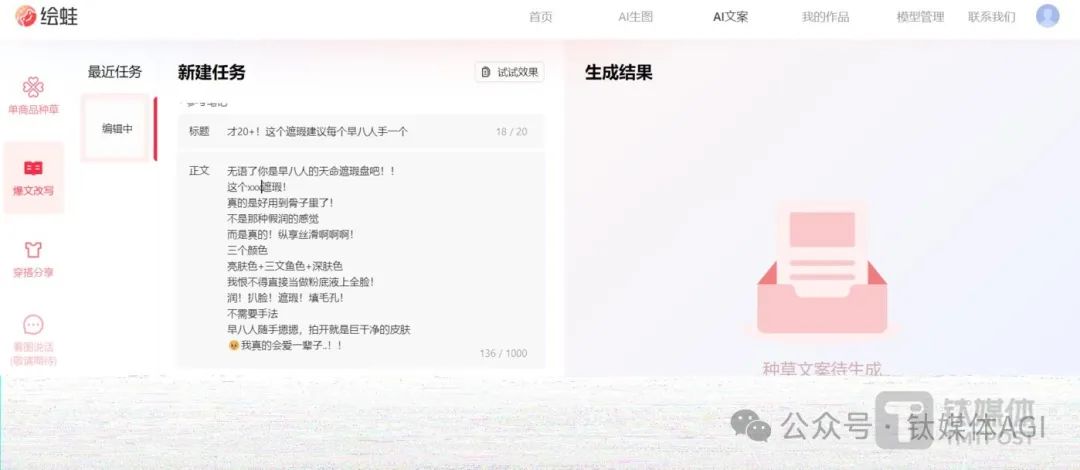
AI生圖中,使用者可以透過選擇商品、選擇模特兒和選擇參考圖來產生自己想要的商品圖片,支持自己上傳模特圖,也有自備的數位模特庫可供使用,可以客製化專屬自己的AI模特,幫助商家節省商品拍攝和模特兒成本。
適用族群:淘寶、天貓店家、帶貨主播、電商達人
上線時間:未知
體驗網址:https://www.ihuiwa.com/(需邀請碼)
AI 圖片-音訊-視訊模型— EMO
產品介紹: EMO是阿里巴巴推出的AI圖片-音訊視訊模型,該模型採用了Stable Diffusion 的生成能力和Audio2Video 擴散模型,能夠產生富有表現力的人像影片。
不同於OpenAI 的文生視頻模型Sora,EMO 主攻的是直接以圖+音頻生成視頻方向,能夠直接從給定的圖像和音頻,剪輯生成一段帶有豐富人物表情的人物頭部視頻。
產品功能:用戶只需要上傳一張照片和一段任意音頻,EMO就可以根據圖片和音頻產生一段會說話唱歌的AI視頻。影片中人物具備豐富流暢的臉部表情,能做到人物開口說話和唱歌時和和音頻保持一致,最長時間可達1分30秒左右。
例如,你可以上傳一張高啟強的照片+一段羅翔老師的音頻,就能得到一段「高啟強普法」影片。或者,你可以上傳一張蒙娜麗莎的照片,讓蒙娜麗莎為你唱現代歌曲,唱rap等。

適用人群:有演講需求人群、電商主播、視訊自媒體及講師等
GitHub:https://github.com/HumanAIGC/EMO
論文網址:https://arxiv.org/abs/2402.17485
專案首頁: https://humanaigc.github.io/emote-portrait-alive/
2024年1月
性能堪比Gemini Ultra的多模態大模型—Qwen-VL-Max
產品介紹: Qwen-VL是阿里推出的開源多模態視覺模型,2024年1月,繼Plus版本之後,阿里又推出了Qwen-VL-Max版本。
產品功能:基礎能力方面,Qwen-VL-Max能夠準確描述和識別圖片訊息,並根據圖片進行資訊推理和擴展創作。這項特性使得此模型在多個權威評測中表現出色,整體表現堪比GPT-4V和Gemini Ultra。
視覺推理方面,Qwen-VL-Max可以理解並分析複雜的圖片訊息,包括識人、答案、創作和寫程式碼等任務。同時模型也具備視覺定位功能,可依畫面指定區域進行問答。

此外,Qwen-VL-Max在影像文字處理方面也取得了顯著進步,中英文文字辨識能力顯著提高,支援百萬像素以上的高清解析度圖和極端寬高比的影像,不僅能完整復現密集文本,還能從表格和文件中提取資訊。
體驗網址: https://huggingface.co/spaces/Qwen/Qwen-VL-Max
AI 生成3D動畫工具-Motionshop
產品介紹: Motionshop是阿里巴巴智慧計算研究院推出的AI角色動畫框架,該框架利用視訊處理、角色檢測/分割/追蹤、姿態分析、模型提取和動畫渲染等多種技術,使得動態視訊中的主角能夠輕鬆跨越現實與虛擬的界限,一鍵變身為3D角色模型且不改變影片中的其他場景與人物。
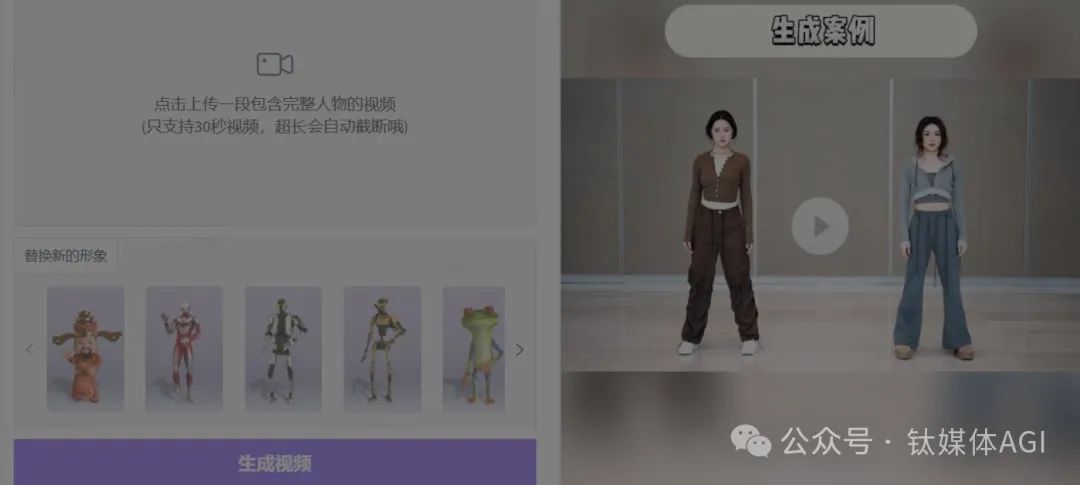
產品功能:用戶只需上傳視頻,AI便能智慧識別視頻中的主要人物,並將其無縫轉換為生動的3D角色模型。同時保持影片中人物動作同步與真實感,能精確復刻原影片中人物的動作細節,確保3D角色的動作流暢自然,提供高度逼真的視覺效果。此外,Motionshop能將現實世界的人物與3D虛擬角色得以完美融合,創造出跨越現實與虛擬界線的全新體驗,為影片內容增添無限可能。
適用人群或場景:影片內容生產者、影視拍攝
專案首頁: https://aigc3d.github.io/motionshop/
能讓圖片開口說話、唱歌的模型框架-DreamTalk
產品介紹: DreamTalk是由清華大學、阿里巴巴和華中科大共同開發的一個可以讓人物照片開口說話、唱歌的模型框架。
產品功能:上傳一張照片和音頻,DreamTalk能夠生成人物臉部動作看起來很真實的高質量視頻,而且嘴唇動作能和音頻都能一一對應。同時DreamTalk也支援多種語言,無論是中文、英文或其他語言都能很好地同步。

據悉,DreamTalk 由三個關鍵組件組成:降噪網路、風格感知唇部專家和風格預測器。透過三種技術結合的方式,DreamTalk 能夠產生具有多種說話風格的逼真說話臉孔,並實現準確的嘴唇動作。
適用人群或場景:演講、產品解說、開會,直播、電商、線上教學等
專案首頁: https://dreamtalk-project.github.io/
論文地址: https://arxiv.org/pdf/2312.09767.pdfGithub
網址: https://github.com/ali-vilab/dreamtalk
2023年12月
可控制影片生成框架-DreamMoving
產品介紹: DreaMoving是一種基於擴散模型打造的可控影片生成框架,透過圖文就能製作高品質人類跳舞影片。
產品功能:使用者只需上傳一張人像,以及一段提示詞,就能生成對應的視頻,而且改變提示詞,生成的人物的背景和身上的衣服也會跟著變化。簡單來說就是,一張圖、一句話就能讓任何人或角色在任何場景裡跳舞。

適用人群或場景:娛樂主播、影片製作
論文連結:https://arxiv.org/pdf/2311.17117.pdf
專案地址:https://humanaigc.github.io/animate-anyone/
體驗網址:https://huggingface.co/spaces/xunsong/Moore-AnimateAnyone
2023年11月
文生視訊模型—— I2VGen-XL
產品介紹: I2VGen-XL是阿里雲推出的一款高清影像生成視訊模型,這款模型的核心組件由兩個部分構成,用於解決語義一致性和清晰度問題。
產品功能:使用者只需上傳一張圖片,即可產生一段解析度為1280*720的高畫質影片。由於在大規模混合視訊和影像資料上進行了預訓練,並在少量高品質資料集上進行了微調,這些資料集具有廣泛的分佈和多樣的類別,這使得I2VGen-XL展示了良好的泛化能力,適用於不同類型的資料。

此外,為了提高視訊質量,該研究訓練了一個單獨的VLDM,專門處理高品質、高解析度數據,並對第一階段生成的視訊採用SDEdit 引入的雜訊去噪過程。
在影片產生效果方面,與Gen2、Pika 生成效果相比, I2VGen-XL 產生的影片動作更加豐富,主要表現在更真實、更多樣的動作,而Gen-2 和Pika 產生的影片似乎更接近靜態。
使用人群及場景:影片內容創作者、影視製作
專案網址:https://i2vgen-xl.github.io/
論文網址:https://arxiv.org/abs/2311.04145
Github:https://arxiv.org/abs/2311.04145
開源的圖像到影片動畫合成框架—AnimateAnyone
產品介紹: Animate Anyone是一款能將靜態影像轉換為角色影片的模型框架。該框架在擴散模型的基礎之上,引入了ReferenceNet、Pose Guider姿態引導器和時序生成模組等技術,以實現照片動起來時保持一致性、可控性和穩定性,輸出高質量的動態化視頻。
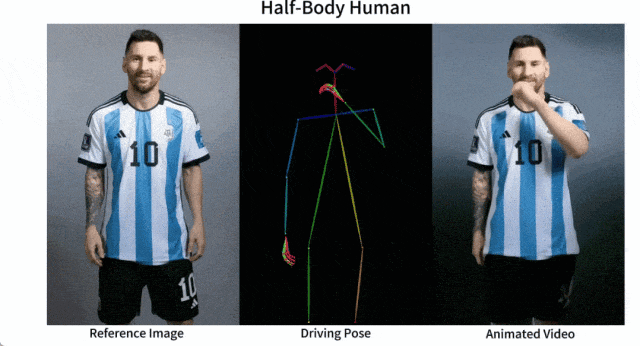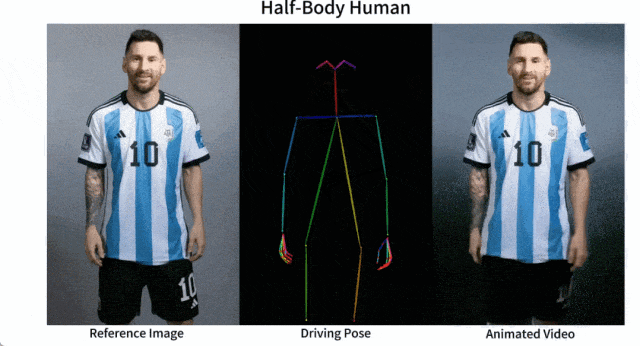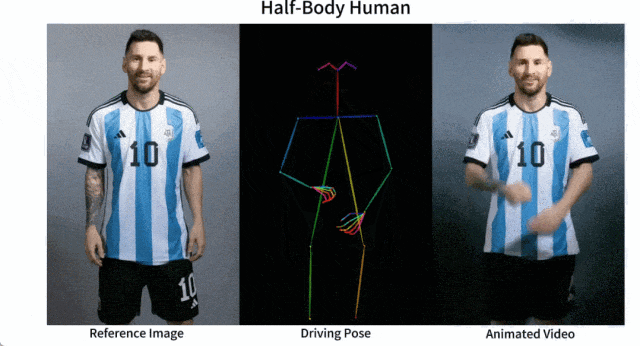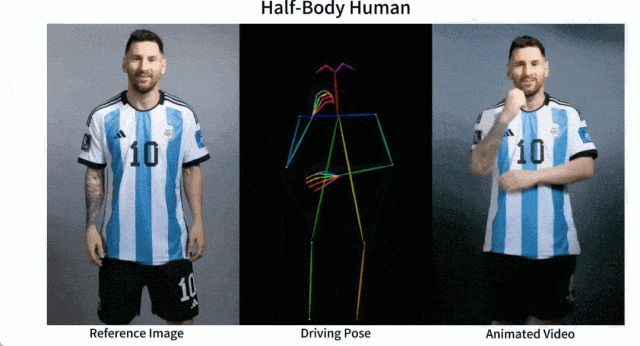
產品功能:角色視訊生成,利用驅動訊號從靜態影像生成逼真的角色視訊;擴散模型支持,借助擴散模型的力量,提供高品質的動畫效果;ReferenceNet設計,透過空間注意力合併詳細特徵,保持外觀特徵的一致性;姿勢指導器,引入高效的姿勢指導器,確保角色動作的可控性和連續性;平滑過渡:採用有效的時間建模方法,保證視訊幀之間的平滑過渡。
目前,Animate Anyone已在GitHub上斬獲了近1.3萬個星標,並在國內外引起了熱烈討論。
適用人群或場景:時尚產業,展示服裝、造型;影片內容創作者、電商、舞者
論文連結:https://arxiv.org/pdf/2311.17117.pdf
專案連結: https://humanaigc.github.io/animate-anyone/
2023年4-7月
通義系列大模型-通義千問、通義萬相和通義聽悟
產品介紹:通義千問是阿里自研的AI 大語言模型,可以幫助使用者解決生活和工作上的問題,提供智慧問答服務。2023年10月31日,通義千問2.0正式發布,阿里也隨之推出通義千問App。相較於1.0版本,通義千問2.0在複雜指令理解、文學創作、通用數學、知識記憶、幻覺抵禦等能力上均有顯著提升。
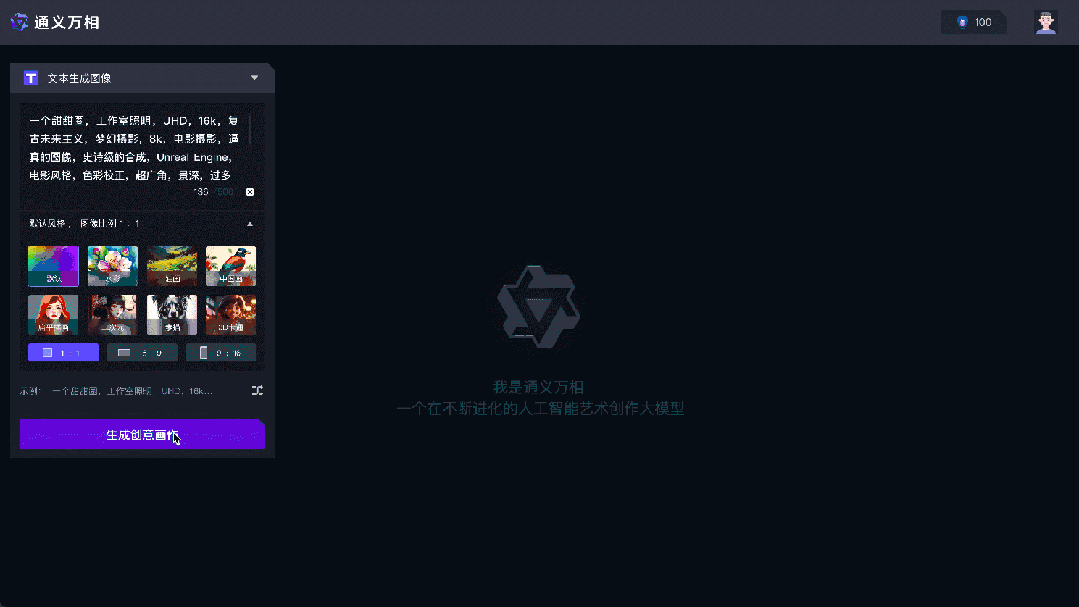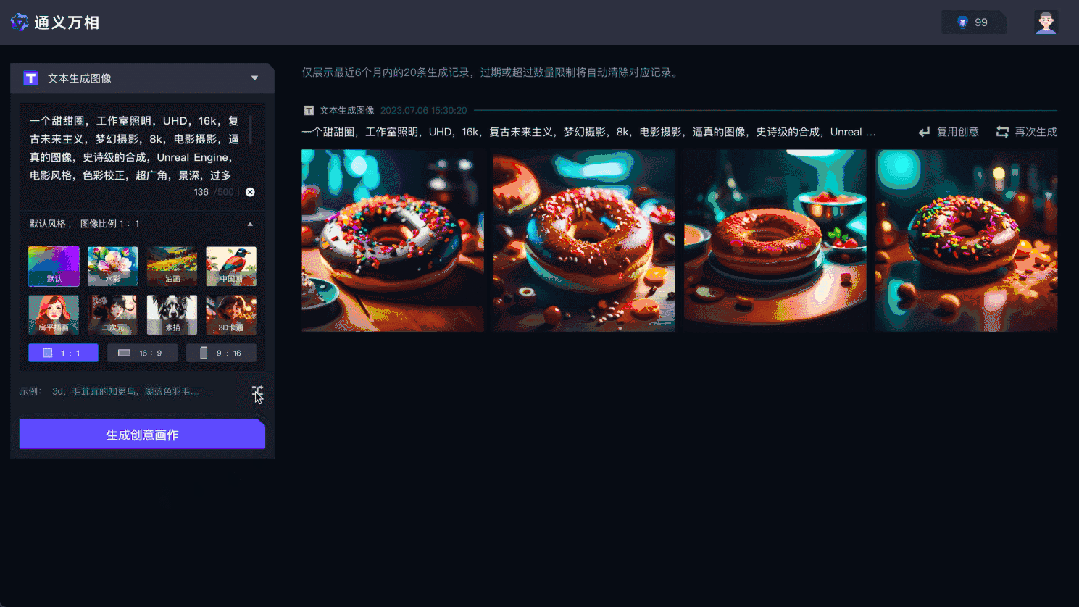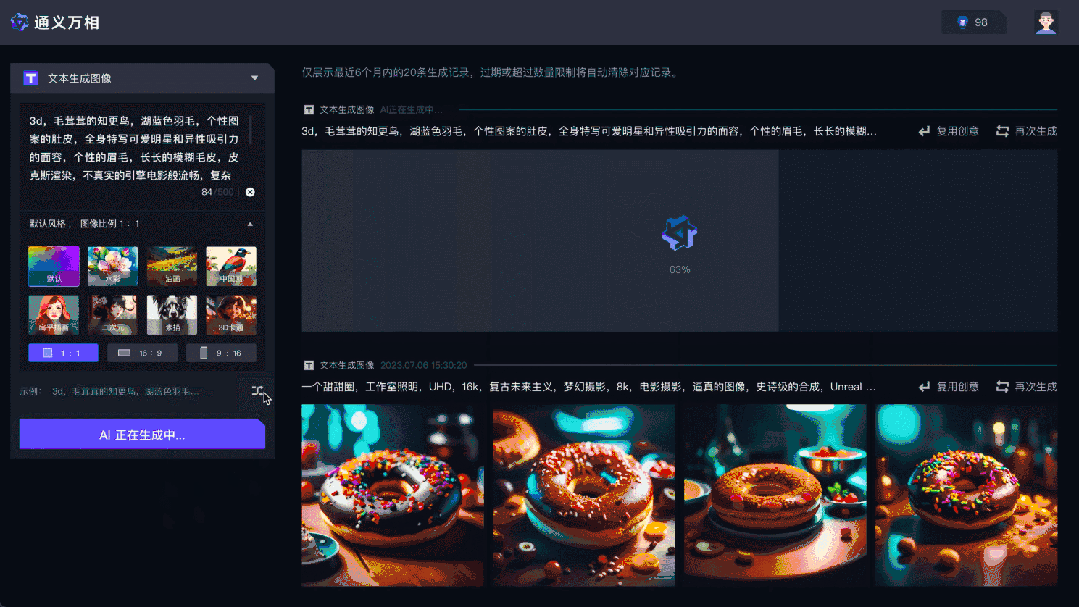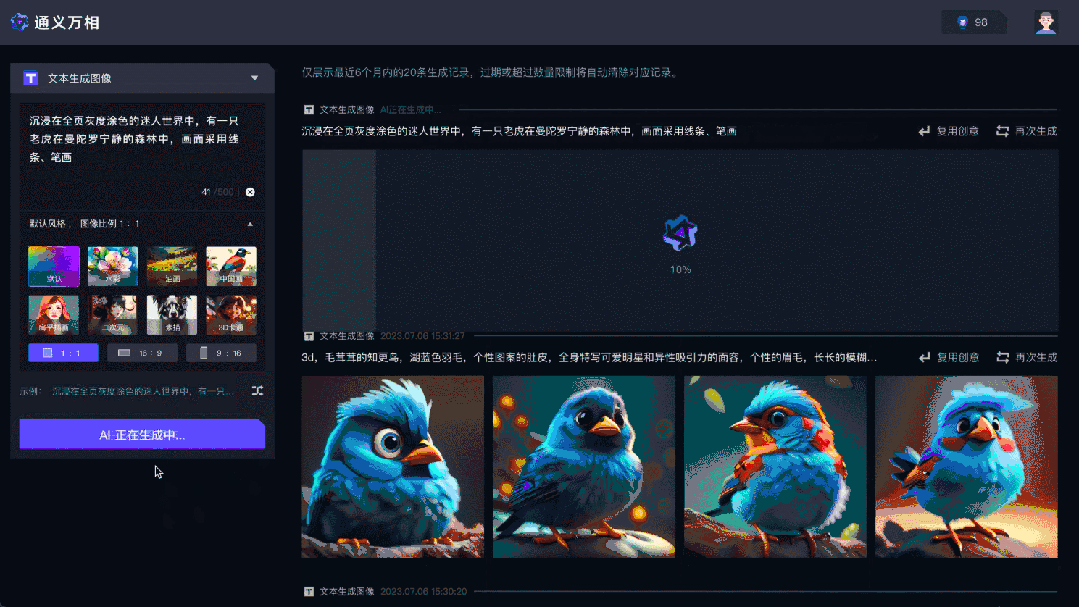
通義萬相是阿里通義大模型家族中的一種AI繪畫大模型,可輔助人類進行圖片創作。基於阿里研發的組合式生成模型Composer,通義萬相提出了基於擴散模型的「組合式生成」框架,透過對配色、佈局、風格等影像設計元素進行拆解和組合,提供了高度可控性和極大自由度的影像生成效果。
通義聽悟是是依托通義千問大模型和音視頻AI模型的AI助手,旨在幫助用戶及客戶在泛音視頻內容場景下提升信息生產、整理、挖掘、洞察效率。
產品功能:通義千問具備多輪對話、文案創作、邏輯推理、多模態理解及多語言支援等功能。使用者可以就任何問題與其對話互動,例如可以問他生活類常識、說故事、寫作文或文案、解答數學題等,但通義千問不具備多模態能力,不具備圖像生成功能。
通義萬相主要功能有三個,分別是文生圖、相似圖生成和風格遷移。在基礎文生圖功能中,可依使用者提示詞生成水彩、扁平插畫、二次元、油畫、3D卡通畫等風格圖像;相似圖片產生功能中,使用者上傳任意圖片後,即可進行創意發散,產生內容、風格相似的AI畫作。此外模型也支援影像風格遷移,使用者上傳原圖和風格圖,可自動把原圖處理為指定的風格圖。
通義聽悟融合了十多項AI 功能,面向線上線下各種泛音視訊場景,通義聽悟可以提供音視頻內容的即時字幕/ 轉寫、多語言翻譯、內容理解/ 摘要,涵蓋全文摘要、章節速覽、發言總結等高階AI 功能。

適用人群或場景:通義千問適用人群較為廣泛,通義萬相適用於藝術繪畫創作,設計師、動漫愛好者;通義聽悟可應用於智能客服、智能家居、智能音箱、智能穿戴設備等領域。
通義千問體驗網址:https://tongyi.aliyun.com/qianwen/
通義萬相體驗網址:https://tongyi.aliyun.com/wanxiang/
通義聽悟體驗網址:https://tingwu.aliyun.com/home
百度2024年1月
統一模態視訊生成系統-UniVG
產品介紹: UniVG是百度推出的統一模態視訊生成系統,其獨特之處在於針對高自由度和低自由度兩種任務採用不同的生成方式,以更好地平衡兩者之間的關係。

產品功能:使用者只需提供一張圖片或一段文字,就能產生一段流暢的視頻,與早期的AI視頻生成工具相比,UniVG所產生的每一幀畫面都更加穩定、連貫。
據悉,UniVG系統引入了「多條件交叉注意力」技術,用於高自由度視訊生成,以產生與輸入影像或文字語義一致的影片。而在低自由度視訊生成方面,採用了「偏置高斯雜訊」的方法,相較於傳統的完全隨機高斯雜訊更能有效地保留輸入條件的原始內容。
適用人群及場景:影片內容創作者
專案網址: https://top.aibase.com/tool/univg
專案示範頁面: https://univg-baidu.github.io/
統一影像生成框架—UNIMO-G
產品介紹:百度推出的UNIMO-G統一影像生成框架,透過多模態條件擴散實現文字到影像生成,克服了文字描述簡潔性對產生複雜細節影像的挑戰。
產品功能:使用者只要給一張圖,然後給出各種提示詞,UNIMO-G就能根據提示詞在圖像基礎上按照提示生成對應圖像,例如上傳一張馬斯克圖像,輸入提示詞給他穿上警服,就能得到穿著警服的馬斯克圖像。

據了解,UNIMO-G的核心組件包括多模態大語言模型和基於編碼的多模態輸入生成影像的條件去噪擴散網路。這個框架也採用了精心設計的資料處理管道,涉及語言基礎和影像分割,以建構多模態提示。
在測試中,UNIMO-G在文字到影像生成和零樣本主題驅動合成方面表現卓越,特別是在處理包含多個影像實體的複雜多模態提示時,產生高保真影像的效果顯著。
適用人群及場景:藝術創作者、漫畫愛好者、攝影師
專案網址:https://top.aibase.com/tool/unimo-g
論文網址:https://arxiv.org/pdf/2401.13388.pdf
2023年3月
文心大模型系列產品-文心一言、文心一格與文心千帆
產品介紹:文心大模型是百度於2019年推出的自然語言處理大模型。此模型基於ERNIE系列模型具備跨模態、跨語言的深度語意理解與生成能力。2023年10月,文心大模型4.0 版本發布,實現基礎模型的全面升級,理解、生成、邏輯、記憶四大能力顯著提升,綜合能力可直接對標GPT-4。
文心一言是百度基於文心大模型打造的生成式AI產品,與阿里的」通義千問」類似,可以進行任何內容的問答對話,可作為生活中的智能小助手。
文心一格是百度基於文心大模型推出的AI藝術創作平台,可以產生多樣化AI創意圖片,輔助創意設計。
文心千帆是百度旗下企業級大模型生產平台,提供包括文心一言在內的大模型服務及第三方大模型服務,也提供大模型開發應用的整套工具鏈。
產品功能:文心一言具有文學創作、商業文案創作、數理邏輯推算、中文理解、音訊、圖像生成等多模態生成能力。例如使用者可以用文心一言解答任何生活及工作問題,幫助使用者撰寫任何領域的文案,解答數學邏輯題,用語音說故事等。
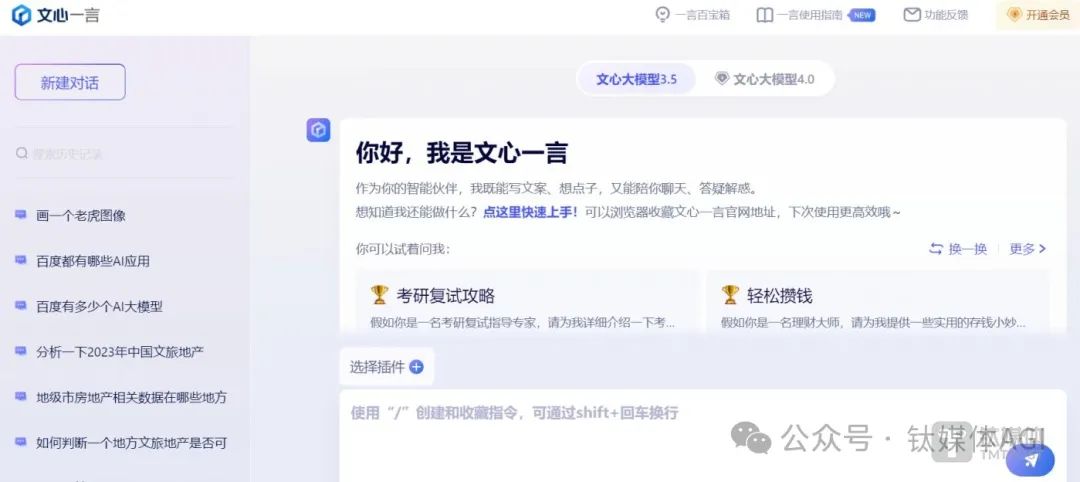
文心一格的主要功能就是影像產生功能。使用者只需要輸入一句話或提示詞,文心一格就能按照指示自動生成圖像,且用戶可以追加更詳細的提示詞對圖像進一步優化或改變圖像風格等。同時文心一格還具有二次編輯圖片和圖片疊加功能,例如可以塗抹掉圖像中不滿意的部分,讓模型重新調整生成。或給出兩張圖片,模型會自動產生一張疊加後的創意圖。此外,文心一格也推出了海報創作、圖片擴充和提升圖片清晰度等功能,提供多種生圖服務滿足用戶需求。
文心千帆主要功能有兩個:其一是文心千帆以文心一言為核心,為企業提供大模型服務,幫助客戶改造產品和生產流程。其二,作為一個大模型生產平台,企業可以在文心千帆上基於任何開源或閉源的大模型,開發自己的專屬大模型。

適用人群及場景:文心一言受眾群廣泛,文心一格適合有繪畫創作和圖像設計需求群。文心千帆主要面向企業級B端客戶。
體驗地址:
文心一言:https://yiyan.baidu.com/
文心一格:https://yige.baidu.com/creation
文心千帆:https://cloud.baidu.com/product/wenxinworkshop
位元組跳動 2024年2月
位元組版DALL·E文生圖模型——SDXL-Lightning
產品介紹: SDXL-Lightning是一款由位元組跳動開發的開源免費的文生圖模型,可根據文字快速產生對應的高解析度影像。
產品功能:使用者在SDXL-Lightning上輸入提示詞,然後選擇推理步驟(選擇範圍為1步—8步),等待數秒即可產生一張高畫質影像。
與以往的文生圖模型相比,SDXL-Lightning的生成速度有顯著提高,能夠在最少步驟內完成文字到1024px解析度影像的生成,適用於需要快速反應的應用場景。

SDXL-Lightning的生成速度之所以能夠顯著提升,主要是因為它透過結合漸進式蒸餾和對抗式蒸餾的方法,解決了擴散模型在生成過程中存在的速度慢和計算成本高的問題,同時保持生成影像的高品質和多樣性,避免了傳統蒸餾方法中存在的影像模糊問題。
使用SDXL-Lightning模型,可在幾秒鐘之內產生高達1024像素解析度的影像。目前,該模型已經在Hugging Face平台上開源,並且下載量超過2200次,登上了Hugging Face流行趨勢第三名,超越了gemma-2b,僅次於最新的谷歌gemma-7b,以及stabilityai/stable -cascade。
適用人群或場景:影片內容創作者、影視製作
體驗網址:https://huggingface.co/spaces/AP123/SDXL-Lightning
文生影片模型—Boximator
產品介紹: Boximator是位元組跳動推出的一款文生影片模型。與Gen-2、Pink1.0等模型不同的是,Boximator可以透過文字精準控制產生影片中人物或物件的動作。
產品功能:與Open AI發布的文生影片模型類似,Boximator也是透過使用者給予文字描述或提示,就能依照指示產生對應的影片。據了解,為了實現對影片中物件、人物的動作控制,Boximator使用了「軟框」和「硬框」兩種約束方法。

硬框可精確定義目標物件的邊界框。使用者可以在圖片中畫出感興趣的對象,Boximator會將其視為硬框約束,在之後的幀中精準定位該對象的位置。
軟框定義一個物件可能存在的區域,形成一個寬鬆的邊界框。物件需要停留在這個區域內,但位置可以有一定變化,實現適度的隨機性。
兩類框都包含目標物件的ID,用於在不同訊框中追蹤相同物件。此外,框還包含座標、類型等資訊的編碼。
不過,據字節跳動相關人士稱,Boximator是視頻生成領域控制對象運動的技術方法研究項目,目前還無法作為完善的產品落地,距離國外領先的視頻生成模型在畫面質量、保真率、視頻時長等方面還有很大差距。
適用人群或場景:短影片創作者、影視製作
論文地址: https://arxiv.org/abs/2402.01566
專案地址: https://boximator.github.io/
文生圖AIGC工具-Dreamina
產品介紹:Dreamina是位元組跳動旗下的AIGC工具,可根據使用者的文字提示產生創意圖片。
產品功能:使用者只需輸入一段文字,Dreamina即可產生四個由AI產生的創意影像。同時Dreamina支援多種圖像風格,包括抽象、寫實等,以滿足不同使用者的美感需求。此外,Dreamina還具備影像調整功能,使用者可以對生成的圖片進行修整,包括調整圖片的大小比例和選擇不同的模板類型。這種靈活性使得使用者可以根據個人喜好或特定需求調整生成的圖像。
適用人群或場景:藝術創作者、漫畫愛好者
體驗網址:https://dreamina.jianying.com/ai-tool/platform
AI 開發平台-Coze釦子
產品介紹: Coze釦子是位元組跳動AI部門Flow開發的一站式AI 開發平台,無論使用者是否有程式設計基礎,都可以利用Coze在30秒內輕鬆創建專屬自己的「AI機器人」。
產品功能:在註冊、登陸帳號之後,使用者可以透過首頁超過60個的插件能力,以及創建Bot,實現多個能力應用。例如,我們希望有一個“新聞搜尋助手”,透過簡單的對話在30秒內就可以自動生成一個AI 機器人,不需要任何代碼編程,小白也能輕鬆上手。
同時,「釦子」平台也有一些自備的bot,涵蓋旅遊、出行和娛樂等場景,可以直接點擊使用,而且還具備可無限擴展的能力集,全面實現個性化定義AI 機器人技術能力。
此外,coze還支援上傳創建自己所需bot的數據,可以與自己的數據進行交互,並且釦子還具備長期的對話記憶能力,透過數據交互和持久記憶為用戶提供更精準的回答。
適用人群或場景:所有使用者均可適用
體驗網址:https://www.coze.cn/store/bot
2024年1月
AI影片生成模型-MagicVideo-V2
產品介紹: MagicVideo-V2 是位元組推出的AI視訊生成模型,它將文字到圖像模型、視訊運動產生器、參考圖像嵌入模組和幀插值模組整合到端到端視訊生成管道中。這種結構使MagicVideo-V2 能夠製作高解析度、美觀的視頻,並具有出色的保真度和流暢度。

產品功能:文字轉圖像功能,MagicVideo-V2 擁有先進的文本到圖像模型,可以將文字轉換為圖像元素,為生成視頻提供基礎素材;視頻運動生成功能:利用視頻運動生成器,可以自動生成視頻,節省使用者的時間和精力;參考影像嵌入功能,MagicVideo-V2 支援參考影像嵌入功能,在產生影片時可以參考指定影像,使影片內容更加準確和多樣化。此外,MagicVideo-V2 的幀插值模組能夠平滑過渡視訊中的每一幀,使生成的視訊更加流暢和連貫。
適用人群或場景:電影製作、創意廣告影片、創意短片
論文網址:https://arxiv.org/abs/2401.04468
專案網站:https://magicvideov2.github.io
2023年12月
AI 劇情互動平台-BagelBell
產品介紹:BagelBell是位元組推出的AI 劇情互動平台,使用者可以透過AI 身分圖、故事名稱和故事介紹了解不同的AI 故事並與自己喜歡的故事互動。
產品功能: BageBel 為使用者提供了一個充滿活力和創造力的虛擬世界,讓使用者可以在這個世界中探索故事、創作角色,並與AI角色互動。這種獨特的體驗不僅可以讓使用者享受故事帶來的樂趣,還可以激發使用者的創造力和想像。目前BagelBell 故事類型十分豐富,涉及狼人、校園、懸疑、霸總、女僕、年下等多個類別,不過多為戀愛題材。
適用群體或場景:劇本創作、遊戲創作
體驗網址:https://www.anybagel.com/
2023年11月
位元組海外版AI智能助理——ChitChop
產品介紹: ChitChop是位元組跳動在海外推出的AI智慧助手,可為使用者提供多達200+的智慧機器人服務,透過提供創意靈感、提高工作效率等方式輔助使用者的工作和生活。
產品功能:首先ChitChop具有豐富的應用場景,提供AI創作、AI繪圖、娛樂休閒、學習提升、工作提效、生活助手六大場景的AI小工具,為用戶提供創造性靈感,提高工作效率。
其次,輸入簡單輸入提示即可互動,只需輸入幾個簡單的提示詞,你就可以把你的想法變成藝術圖像或與A!進行交流互動。
再次,文件智慧分析和總結功能,新增上傳一個文件,即可分析、總結和對文件內容發起討論,幫助使用者有效率地學習和分析內容。
最後是即時網路搜尋功能,可以與人工智慧互動進行搜尋。此外,還內建200多個智慧機器人,可協助使用者提升創造力,學習新話題,甚至與人工智慧虛擬角色玩遊戲。
適用人群或場景:海外用戶均適用
體驗網址:https://www.chitchop.com/tool
2023年8月
AI智慧聊天助理-豆包與Cici
產品介紹:豆包和Cici都是字節跳動基於雲雀模型開發的AI智能聊天助手,可以回答各種問題並進行對話,幫助用戶獲取信息,只不過豆包是針對國內用戶開放的,Cici是豆包的海外版本。
產品功能:豆包與Cici的功能一致,提供問答、智慧創作、聊天等服務。進入豆包/Cici官網首頁登陸後,用戶可直接與豆包/Cici對話,例如可以讓豆包幫助寫爆款文案、生成圖片、英語翻譯等。豆包/Cici還支援創建專屬的智慧助手,例如可以自訂自己的智慧導遊,可以幫助自己做旅遊形成規劃,提供更多包含交通、景點及美食的旅遊相關的資訊。此外,豆包/Cici還有具備許多現成的AI智能體可供使用,涉及生活、娛樂、寫作、情緒和遊戲多領域。
適用人群或場景:所有C端用戶均適用
體驗網址: https://www.doubao.com/chat/bot/discover
https://www.ciciai.com/
位元組跳動大語言模式—雲雀
產品介紹:雲雀是字節跳動自研的大語言模型,該模型採用Transformer 架構,能夠透過便捷的自然語言交互,高效完成互動對話、資訊獲取、協助創作等任務。
產品功能:內容創作功能,可依使用者指令進行內容創作,產生文案大綱及廣告、行銷文案等;智慧問答功能,使用者可透過雲雀快速獲取生活常識、工作技能,協助高效解決工作、生活等各類場景中的問題;邏輯推理能力,可進行思考、常識、科學推理透過分析問題的前提條件和假設來推理出答案或解決方案,給出新的想法和見解;代碼生成功能,作為大語言模型,雲雀具備程式碼產生能力和知識儲備,可高效的輔助程式碼生產場景;資訊擷取能力,雲雀可以深入理解文字資訊之間的邏輯關係,從非結構化的文字資訊中抽取所需的結構化資訊。
體驗網址:https://www.volcengine.com/contact/yunque
多模態大模型—BuboGPT
產品介紹: BuboGPT是位元組研發的多模態大模型,透過整合文字、影像和音訊輸入,可以執行跨模態交互作用並做到對多模態的細粒度理解。

產品功能:首先是多模態理解能力,BuboGPT實現了文字、視覺和音訊的聯合多模態理解和對話功能;其次是視覺對接能力,BuboGPT能夠將文字與圖像中的特定部分進行準確關聯,實現細粒度的視覺對接;再次是音頻理解能力,BuboGPT能夠準確描述音頻片段中的各個聲音部分,即使對人類來說一些音頻片段過於短暫難以察覺;最後是對齊和非對齊理解能力;BuboGPT能夠處理匹配的音訊-影像對,實現完美的對齊理解,並能對任意音訊-影像對進行高品質的回應。
專案網址:https://bubo-gpt.github.io/
論文網址:https://arxiv.org/abs/2307.08581
騰訊 2024年1月
多模態音樂生成模型—M2UGen
產品介紹: M2UGen是一款多模態音樂生成模型,融合了音樂理解和多模態音樂生成任務,旨在協助使用者進行音樂藝術創作。
產品功能: M2UGen具備音樂理解和生成能力,不僅可以從文字生成音樂,它還支援圖像、視訊和音訊生成音樂,還可以編輯生成的音樂。
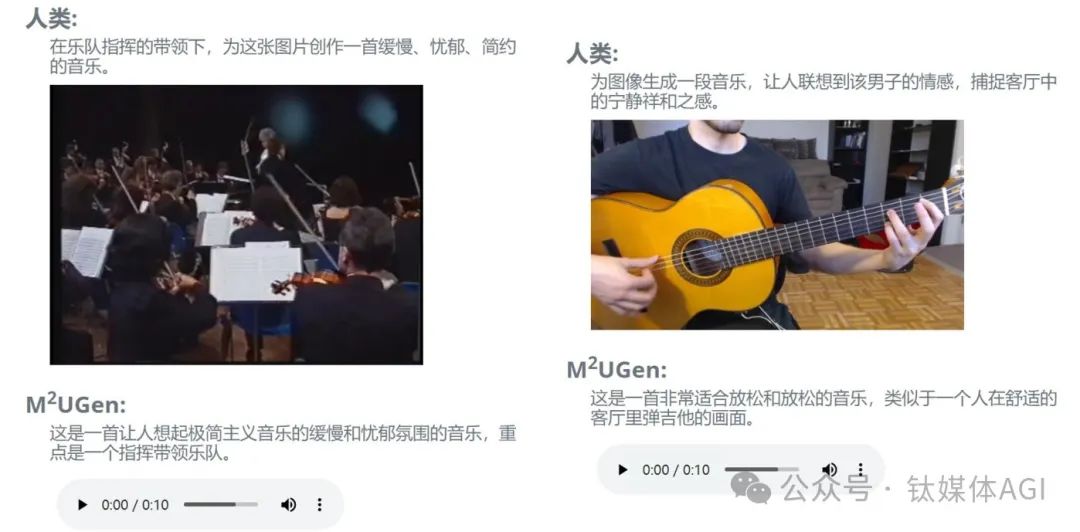
此模型利用MERT等編碼器進行音樂理解,ViT進行影像理解,ViViT進行視訊理解,並使用MusicGen/AudioLDM2模型作為音樂生成模型(音樂解碼器)。使用者可以輕鬆移除或替換特定樂器,調整音樂的節奏和速度。這使得用戶能夠創造出符合其獨特創意的音樂作品。
適用人群或場景:音樂創作、音訊視訊剪輯
論文網址:https://arxiv.org/pdf/2311.11255.pdf
體驗網址: https://crypto-code.github.io/M2UGen-Demo/
2023年12月
AI影片大模型-AnimateZero
產品介紹:AnimateZero是騰訊AI團隊發布的一款AI視訊生成模型,透過改進預先訓練的視訊擴散模型(Video Diffusion Models),能夠更精確地控制影片的外觀和運動。

產品功能:使用者可以透過輸入文字和圖像來產生視頻,例如由動漫人物的圖片生成的視頻,不僅人物動作流暢,還融入了眼睛變色、頭髮蓬蓬的小細節。
而且AnimateZero還能透過插入文字嵌入來控制影片的動態效果,例如將車子顏色變更等。
適用人群或場景:影片內容創作者、影視製作
專案地址:https://vvictoryuki.github.io/animatezero.github.io/
GitHub:https://github.com/vvictoryuki/AnimateZero?tab=readme-ov-file
2023年10月
開源AI視訊生成模型——VideoCrafter
產品介紹:VideoCrafter是由騰訊和香港科技大學聯手打造的AI影片產生大模型,能夠根據使用者提供的文字描述產生高品質、流暢的影片作品。2024年1月,騰訊將VideoCrafter升級更新,推出了VideoCrafter2模型。

產品功能:使用者只需輸入提示字就能產生對應的視頻,並可透過整合編輯器對產生的影片進行編輯修改,在修改調整後,使用者還可以將影片儲存為MP4、MOV和AVI等多種格式。相較於前一代產品,VideoCrafter2採用更先進的影像處理技術,顯著提升影片的視覺質量,使影像更為清晰、細膩;同時VideoCrafter2動態效果明顯增強,不僅關注靜態畫面,也專注於提升影片中的動態效果,使得運動更加流暢自然。
此外, VideoCrafter2在影片概念的組合方面表現出色,能夠更好地整合不同元素,創造出更有深度和創意的影片。
專案地址:https://ailab-cvc.github.io/videocrafter2/
GitHub:https://github.com/AILab-CVC/VideoCrafter
2023年9月
通用多模態大模型—混元大模型
產品介紹:混元大模型是騰訊自研的大語言模型,具備強大的中文創作能力,複雜語境下的邏輯推理能力,以及可靠的任務執行能力。
產品功能:騰訊混元大模型主要功能包含:智慧互動問答、內容創作、邏輯推理及影像生成等。
內容創作方面,模型可在多種場景下處理超長文本,透過位置編碼優化,提升長文的處理效果與效能。結合指令跟隨優化,讓產出內容更符合字數要求。
邏輯推理能力方面,能準確理解使用者意圖,基於輸入資料或資訊進行推理、分析。
2023年10月,混元大模型開放文生圖功能,使用者可根據關鍵字產生圖片,具有強大的中文理解能力。能夠產生各種風格的圖片,包括景觀、人物、動漫等。產生的圖片具有真實感和自然度。
適用人群或場景:適用於文件、會議、廣告行銷等多場景
體驗網址:https://hunyuan.tencent.com/
華為 2024年3月
影像生成模型——PixArt-Σ
產品介紹: PIXART-Σ是華為推出的影像產生模型,採用Diffusion Transformer (DiT) 架構,可直接產生4K 解析度的AI 影像。
產品功能:使用者只需輸入一段文字描述就能產生具有4K高解析度的圖像,相較於前身PixArt-α,它提供了更高的圖像保真度和與文字提示更好的對齊。

具體來看,高品質的訓練資料和高效的Token 壓縮。PIXART-Σ結合了更高品質的影像數據,配對更精確和詳細的影像標題,同時在DiT 框架內提出了一個新的注意力模組,可以壓縮鍵(Key)和值(Value),顯著提高效率,促進超高解析度影像的生成。
正是由於這些改進,PIXART-Σ才能以較小的模型規模(6億參數)實現優於現有文本到圖像擴散模型(如SDXL(26億參數)和SD Cascade(51億參數))的圖像品質和使用者提示遵從能力。此外,PIXART-Σ 能夠生成4K 影像,為創建高解析度海報和壁紙提供了支持,有效地增強了電影和遊戲等行業中高品質視覺內容的製作。
適用人群或場景:藝術創作者、漫畫、繪畫、插畫家
專案地址:https://pixart-alpha.github.io/PixArt-sigma-project/
論文網址:https://arxiv.org/abs/2401.05252
2024年2月
華為微小模型-盤古π系列(PanGu-π-1B Pro 和 PanGu-π-1.5B Pro)
產品介紹: PanGu-π-1B Pro 和PanGu-π-1.5B Pro是華為近期推出的參數規模分別為10億/15億的微小模型。
產品功能:以一個1B 大小的語言模型作為載體,在分詞器裁剪、模型架構調優、參數繼承、多輪訓練等方面具有巨大優勢,GPU 的推理速度和效率遠超GPT-3.5。具體來看,首先,透過分詞器裁剪,刪除低頻詞彙,降低Token 數量,減少計算開銷,為模型主體留足空間。
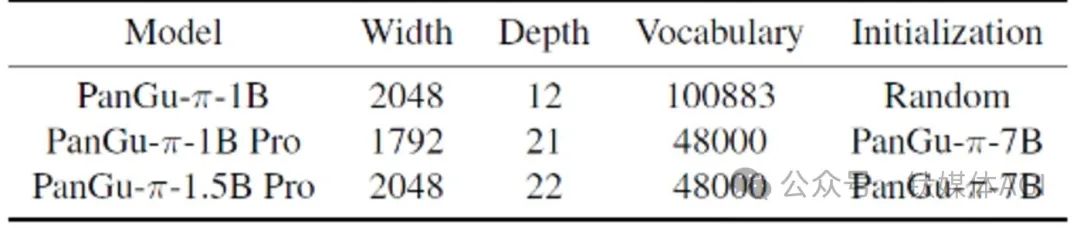
其次,模型架構調優成為關鍵,深度、寬度對小語言模型效果有極大影響。透過深度、寬度和擴展率的實驗,找到了最適合小模型的架構配置。再次,運用參數繼承,有效提升小模型的效果並加速收斂。
最後,與大多數大模型只進行一輪訓練不同,小模型的多輪訓練被證明對於克服遺忘問題非常有效。透過第一輪訓練的資料篩選和精煉,可以優化第二輪訓練的效果。實驗證明,多輪訓練在小模型上表現出色,使得模型在有限的資源下也能顯著提升。
盤古 π 論文連結:https://arxiv.org/pdf/2312.17276.pdf
「小」 模型訓練論文連結:https://arxiv.org/pdf/2402.02791.pdf
GitHub:https://github.com/YuchuanTian/RethinkTinyLM
2023年7月
華為通用多模態大模型—盤古3.0系列
產品介紹:盤古大模型3.0 是一個面向產業的AI大模型系列,旨在提升核心競爭力,協助客戶、合作夥伴、開發者在各產業落地人工智慧並創造價值。
產品功能:盤古大模型3.0系列包含自然語言、視覺、多模態、預測、科學計算大模型等五個基礎大模型,可提供使用者知識問答、文案生成、程式碼生成,以及多模態大模型的圖像生成、圖像理解等能力。
同時盤古模型3.0提供參數範圍從100億到1000億的不同規模參數,可以滿足不同客戶的需求。目前,盤古模型已在金融、製造、藥品研發、煤炭、鐵路等各行業成功落實。
適用人群或場景: B端用戶
體驗網址:https://pangu.huaweicloud.com/
小紅書 2024年1月
小紅書文案生成器-地瓜智語
產品介紹:地瓜智語是一種利用人工智慧技術,自動產生小紅書風格文案的工具。
產品功能:首先是文案生成功能,用戶只需要上傳一張圖片,透過人工智慧技術對圖片內容進行分析,就能產生符合圖片內容的文案。
其次是擁有1500萬小紅書文案庫,這些文案都是經過小紅書用戶驗證過的,符合小紅書平台的風格和用戶需求。使用者可以直接從文案庫中選擇合適的文案,無需自己編寫。
最後是自訂功能,使用者可以自訂關鍵字、文案風格、場景標籤,以產生符合個人需求的文案。例如,使用者可以輸入「椰香雞肉」作為關鍵字,選擇「美食」場景,產生介紹椰香雞肉食材和製作方法的文案。
適用人群或場景:小紅書創作者
體驗網址:https://space.chinaz.com/
2023年9月
AI聊天機器人-Davinic達文西
產品介紹:達文西是小紅書正在內測的一款AI聊天助手,它是基於Meta旗下的LLAMA大模型進行訓練的,可以為用戶提供智能問答等AI聊天功能。
產品功能:達文西可以提供使用者偏向好物生活類的問答,包括旅遊攻略、美食攻略、地理和文化常識、生活技巧、個人成長和心理建議,以及活動推薦等。例如可以推薦用戶適合春季遊玩景點,推薦高性價比廚房用品等。透過與"達文西"的互動,使用者可以獲得準確、有用的信息和建議,節省時間和精力,提升生活品質和幸福感。

適用人群或場景:適合所有用戶
體驗地址:內測地址,暫無鏈接
2023年8月
AI繪畫平台—TrikAI
產品介紹: Trik AI是小紅書推出的AI圖像創作平台,專注於「一眼中國風」方向的無限探索。
產品功能:使用者輸入文字提示,就能產生具有「中國風」卡通或動漫影像。使用者可以透過該平台將設計作品融入東方文化的美學元素中,實現化繁為簡的效果。

適用人群或場景:適合中式美學設計師、繪畫者
體驗網址:https://www.trikai.com/
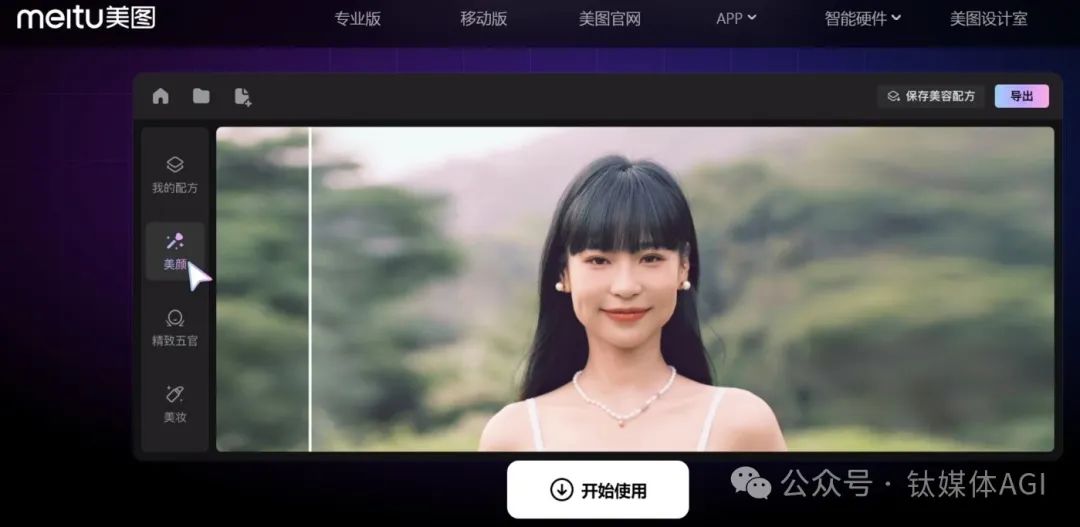
美圖公司 2023年6月
AI 視覺大模型-MiracleVision 奇想智能
產品介紹:美圖AI 視覺大模型MiracleVision(奇想智能)於2023 年6 月內測,具備強大的視覺表現力與創作力,為美圖秀秀、美顏相機、Wink、美圖設計室、WHEE 、美圖雲修等知名影像與設計產品提供AI 模型能力的同時,也幫助美圖公司建構起由底層、中間層和應用層建構的人工智慧產品生態。

產品功能: MiracleVision(奇想智能)的主要功能包含文生圖、圖生圖、文生影片、圖生影片與模型訓練、圖片局部修改等,目前已應用於美圖旗下多個產品,例如美圖秀、WHEE等,用戶可自行前往官網或下載APP體驗。
據悉,MiracleVision(奇想智能)目前已升級至4.0 版本,除全面應用於美圖旗下產品,還在逐步協助電商、廣告、遊戲、動漫、影視五大產業。
適用人群或場景:影視製作、動漫、遊戲
體驗網址:http://www.miraclevision.com/
AI藝術創作平台-WHEE
產品介紹: WHEE 是美圖基於MiracleVision 大模型打造的AI生圖藝術創作平台,旨在為使用者提供一站式AI 視覺創作服務,為視覺創作提供更多想像和靈感。
產品功能: WHEE 主要功能包括文生圖、圖生圖、風格模型訓練、AI超清、AI生影片和AI改圖等。文生圖不多贅述,圖生圖可以根據上傳的圖片產生一幅風格類似的圖片;風格模型訓練適合設計或繪畫等專業人士,可以訓練生成自己的繪畫模型;AI超清是最近上新的一鍵修復舊照片功能,可還原照片高清畫質;AI影片功能目前顯示在內測,不過經測試,文生影片產生速度較快,但畫面真實感欠缺,圖生影片產生時長需幾分鐘,影片畫面略顯僵硬,不夠自然。

值得一提的是,2023年12月,WHEE行動端App正式上線,使用者可自行下載在手機端就可即時體驗AI賦能藝術創作的魅力。
適用人群或場景:藝術創作者、設計師、插畫家
體驗網址:https://www.whee.com/
AI口播影片工具-WHEE
產品介紹:開拍是一款幫助口播影片創作者從腳本靈感到高清畫質拍攝、影片人像精修、後期智慧剪輯全連結的影像生產力工具。
產品功能:內含AI 腳本、數位人主播、提詞器、高畫質畫質、美顏美妝等。AI腳本是用戶可以輸入關鍵字一鍵產生口播文案或幫助產生小紅書爆款文案、潤飾文案內容;數位人主播是用戶可以自訂或創建數位人主播,支援更換人物形象和影片背景;提詞器功能讓口播不用背稿,勻速模式支援自訂字幕滾動速度;高清畫質功能,提升影片清晰度,支援4K 畫質錄影、濾鏡調節,同時支援美顏功能,可自訂參數,素顏也可以錄影。
適用人群或場景:影片內容創作者、主播
體驗網址:https://www.kaipai.com/home
AI影片剪輯工具-Winkstudio
產品介紹:Winkstudio是一款AI影片人像精修工具,旨在提升攝影師、後期師、MCN機構、自媒體部落客影片剪輯效率。
產品功能: WinkStudio提供配方批量出片、智慧畫質修復、智慧髮絲級摳像、批量色調統一等功能,滿足不同使用者的個人需求。同時,WinkStudio支援高質視頻輸出,最高支援導出4K超清視頻,確保高清流暢的視覺體驗。
適用人群或場景:影片內容創作者、攝影師、影片後期
體驗網址:https://wink.meitu.com/?channel=wsllbd7&bd_vid=12130296699805568259
商業設計工具—美圖設計室
產品介紹:美圖設計室是美圖推出的AI商業設計工具,旨在協助提升商業設計製圖效率。
產品功能: AI商品圖功能,上傳商品圖後,AI可自動摳出產品主體,支持美容、鞋帽、家居等十餘種產品品類識別,百餘種推薦場景幫你生成多種風格,還原真實使用情境;AI LOGO功能,給予提示字和商品slogan就能幫助自動產生商品logo;AI模特兒功能,使用者只需上傳衣服或假髮等商品圖,選擇系統AI模特兒和場景就能產生全新商品圖,不僅可以提升製作商品圖效率,同時也降低了邀請模特兒拍攝成本;AI海報功能,可以幫助產生商品封面圖、活動優惠圖以及各種活動行銷封面。

此外,還有AI消除和智慧摳圖功能,可以對影片或圖片進行一鍵塗抹去除不要的影像元素。
適用人群或場景:電商、帶貨
體驗網址:https://www.x-design.com/logo-design/?from=home
AI數位人生成工具-DreamAvatar
產品介紹: DreamAvatar是美圖旗下的AI數位人生成工具,專注於數位人和AIGC技術的深度融合, 為推動數位時尚、行銷推廣、企業數位化的創新帶來更多想像。
產品功能: DreamAvatar「AI演員」數位人的生成,不需要專業設備,一台手機就能輕鬆搞定。使用者只需要將拍攝好的影片素材導入,並指定影片裡的人物,AI會進行人體偵測、追蹤、擦除、替換,以及背景修復,自動把真人替換成數位人。利用3D人體姿態估計和驅動演算法,DreamAvatar的AI演員能夠做到動作與真人完美同步。
DreamAvatar還能透過相機姿態估計和跟踪,以及光照估計演算法,讓數位人和環境自然融合,更具真實感。最後,將前面這一系列AI處理,匯總到3D渲染並輸出。

目前,DreamAvatar「AI演員」支援最長10秒影片的轉化,共推出了機器人、獸人、類人三大題材共計11個不同風格的數位人形象,每個題材從造型風格、渲染風格都做了不同方向的細化,給予使用者多樣性的體驗與選擇。
適用人群或場景: AI模特兒、AI主播、AI客服、AI演員
體驗網址:https://www.dreamavatar.com/
美圖AI助理——RoboNeo
產品介紹: RoboNeo是美圖推出的AI助手,透過與其對話可幫助使用者修圖、設計和繪畫 。
產品功能: RoboNeo的特色在於能將自然語言轉換為修圖指令。透過與RoboNeo對話,使用者能夠輕鬆完成以往需要手動操作的影像創作任務。例如告訴RoboNeo “幫我消除路人甲”、“幫我製作視頻宣傳片”、“幫我設計海報”, RoboNeo都能一一實現。

由於修圖過程透過對話進行,使用者擁有更高的自由度。RoboNeo的創作效果也不會受限於本地客戶端的功能或素材約束,能激發無限的創意。
此外,RoboNeo還能根據語言指示對圖片進行效果改進,提升創作者的生產效率。
適用人群或場景:設計師、插畫家、美術創作者
科大訊飛
2024年1月
AI語音模型-星火語音大模型
產品介紹:星火語音大模型是一種AI語音模型,該模型能將辨識、翻譯和多語種分類等多種功能統一交換並進行訓練,實現多種任務資訊的共通,使語音辨識效果大幅提升。

產品功能:主要是大模型語音辨識和超擬人語音合成,前者能將短音頻(≤60秒)精準識別成文字,除中文普通話和英文外,支援37個語種自動判別,說話過程中可以無縫切換語種,並即時回傳對應語種的文字結果。
超擬人語音合成功能,透過口語化及副語言現象建模,還原真人口語表達和語流變化等韻律特點,實現生動自然更接近真人的語音合成能力,滿足不同場景個性化需求。
適用人群或場景:語音搜尋、智慧客服、人機互動、聊天輸入、語音助理等
體驗網址:https://xinghuo.xfyun.cn/speechllm
2023年12月
一站式AIGC內容創作平台-星火內容營運大師
產品介紹:星火內容營運大師是一個集選題,寫作,配圖,排版,潤色,發布,數據分析等一體的內容運營工作平台。該平台基於訊飛星火大模型打造,致力於為內容營運、品牌內容等職缺提供易用的生產力工具。
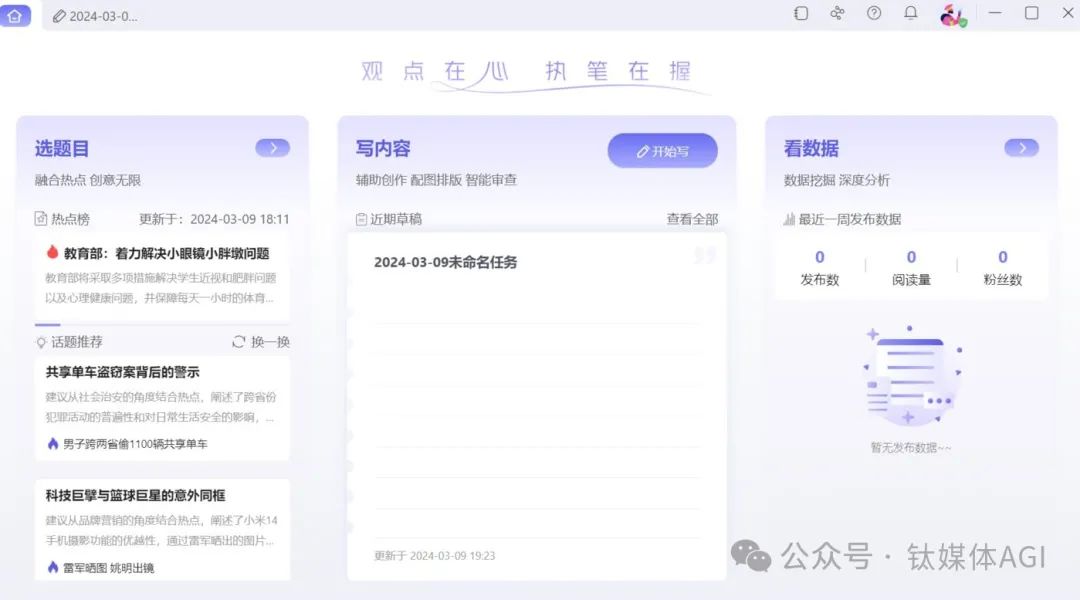
產品功能: AI選題推薦,AI智能生成標題,緊跟熱點,激發創作靈感;AI文章創作,輸入主體,AI一鍵寫稿,還支持模仿生成和選擇風格生成;AI審查校對,提供校對文本、審查糾錯、合規風險提示等功能,讓創作者能夠更專注於內容創作;AI配圖排版,AI可以根據關鍵字生成圖片,一鍵排版,圖文並茂;支持多平台內容分發,支持分發到今日頭條和微信公眾號,並可監控數據。
適用人群或場景:自媒體創作者、媒體作者、文案策劃等
體驗網址:https://turbodesk.xfyun.cn/home?channelid=bd6&bd_vid=11782091658338351641
2023年11月
人工智慧文檔平台-訊飛智文
產品介紹:訊飛智文是科大訊飛基於星火認知大模型推出的一款人工智慧PPT生成工具,只需輸入一句話或添加要演示的文稿即可一鍵生成PPT。

產品功能:主題創建模式,一句話式主題輸入,快速把你的想法變為PPT 文檔,可根據需求進行AI改寫,完善文檔內容;文本創建模式,添加一段話或者一篇文章,AI 幫你總結、分割、精煉,最終產生高度相關的PPT文件;PPT文案優化,內建SPARK AI助手,可以進行文案的潤飾、擴充、翻譯、縮寫、分割、總結、提煉、糾錯、改寫等;演講備註功能,可秒速生成備註內容,幫你將演講內容梳理清晰,避免PPT演講中途卡頓;此外,平台內置多種模板可一鍵為PPT切換主題和模板,讓你的創作更出色更有效率。
適用人群及場景:會議演講、工作報告
體驗網址:https://zhiwen.xfyun.cn/
2023年8月
認知智能大模型—訊飛星火
產品介紹:訊飛星火是科大訊飛推出的新一代認知智能大模型,擁有跨領域的知識與語言理解能力,能基於自然對話方式理解與執行任務。
產品功能:內容生成能力,可以進行多風格多任務長文本生成,例如郵件、文案、公文、作文、對話等;語言理解能力,可以進行多層次跨語種語言理解,實現語法檢查、要素抽取、語篇歸整、文本摘要、情感分析、多語言翻譯等;知識問答能力,可以回答各種各樣的問題,包括生活知識、工作技能、醫學知識等;推理能力,擁有基於思維鏈的推理能力,能夠進行科學推理、常識推理等;多題型步驟級數學能力,具備數學思維,能理解數學問題,涵蓋多種題型,並能給出解題步驟; 代碼理解與生成能力,可以進行代碼理解、程式碼修改以及程式碼產生等工作。

2024年1月,星火認知大模型V3.5發布,實現了在文本生成、語言理解、知識問答、邏輯推理、數學能力、代碼能力以及多模態能力等方面的全面提升。具體來看,文本生成提升7.3%,語言理解提升7.6%,知識問答提升4.7%,邏輯推理提升9.5%,數學能力提升9.8%,程式碼能力提升8.0%,多模態能力提升6.6%。
與同類競品相比,據稱星火認知大模型V3.5在語言理解和數學方面的能力已經超過了GPT-4 Turbo,代碼能力達到了GPT-4 Turbo的96%,而多模態理解能力則達到了GPT-4V的91%。
適用人群或場景:適合所有用戶
體驗網址:https://xinghuo.xfyun.cn/&wd=&eqid=addca757000746550000000664993589
全端國產化開源大模型—星火開源 -13B
產品介紹:星火開源 -13B是科大訊飛發布的全端國產化開源大模型,它是首個基於全國產化算力平台”飛星一號”的開源大模型。擁有130 億參數,包含基礎模型iFlytekSpark-13B-base、精調模型iFlytekSpark-13B-chat,開源了微調工具iFlytekSpark-13B-Lora、人設定製工具iFlytekSpark-13B-Charater。學術企業研究可以基於全端自主可控的星火優化套件,更方便地訓練自己的專用大模型。
產品功能:具備通用任務處理能力和生產力功能,如聊天、問答、文本提取、分類、數據分析和代碼生成等,同時基於強大的AI能力,支持企業和學術研究訓練專用大模型,優化學習輔助、數學推理等領域的應用。
適用人群或場景:適合需要進行 AI模型訓練和應用開發B端企業
體驗網址:https://xihe.mindspore.cn/modelzoo/iflytekspark/introduce
AI寫作工具-訊飛寫作
產品介紹:訊飛寫作是一款全能線上AI寫作工具,旨在為使用者提供高效、準確的文本生成服務。
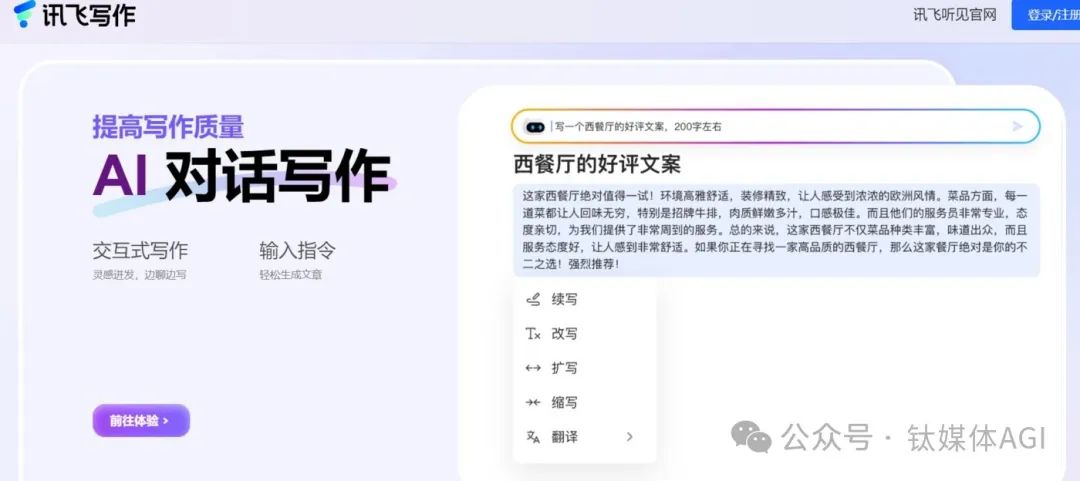
產品功能:對話寫作,訊飛寫作採用對話式互動設計,使用者只需輸入關鍵字指令,系統就會根據使用者需求產生對應的文字內容;AI範本寫作,訊飛寫作具備豐富的範本庫,涵蓋了各種類型的文本,如會議記錄、演講稿、財經新聞、實務報告等。使用者可以依照自己的需求選擇合適的模板,然後進行資訊填寫,就可以完成文字創作;AI素材寫作,訊飛寫作內建了多種AI工具,如擴充、縮寫、改寫、續寫、文字校對等。這些工具可以幫助使用者優化文字結構,提高表達效果。此外,為提升寫作效率,訊飛寫作也支援導音頻、影片、文字等多種格式的素材,方便使用者在文字中插入和使用。使用者可以將這些素材直接拖曳到編輯器中,輕鬆實現基於素材內容的文字創作。
適用群體或場景:內容創作者、演講、報告工作
體驗網址:https://huixie.iflyrec.com/?from=xfxzpz
360公司 2024年1月
360AI搜尋
產品介紹: 360 AI搜尋是新一代智慧搜尋產品,主要為最複雜的搜尋查詢提供更相關、更全面的答案。
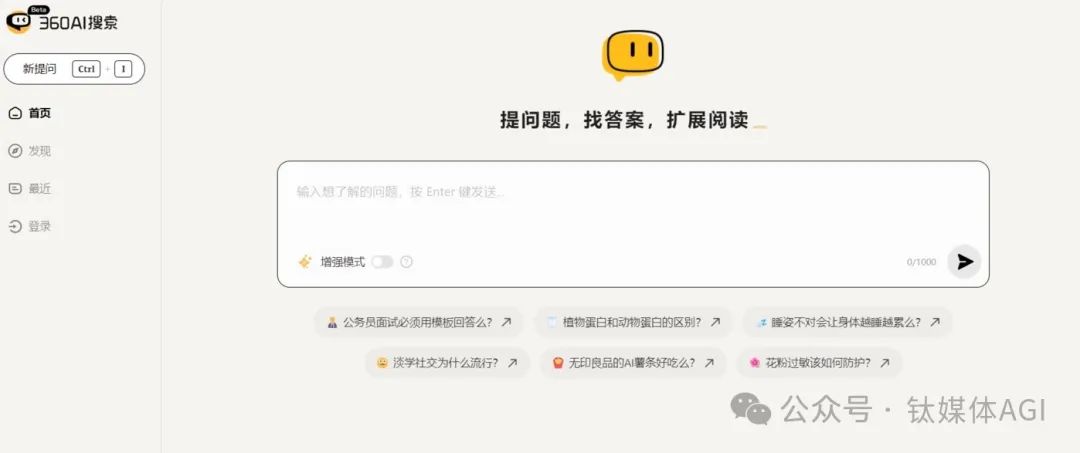
產品功能:本產品主要包括AI搜尋和增強模式兩個新功能。其中,AI 搜尋是用戶提出問題後,AI將透過搜尋引擎進行檢索,讀取並分析多個網頁的內容,最後輸出精準的結論;增強模式是在用戶提問後,AI將進行語義分析並追問以補充更多信息,然後AI將問題拆分為多組關鍵字進行搜尋引擎檢索,深度閱讀更多的網頁內容,最終生成邏輯清晰、準確無誤的答案。
體驗網址:https://so.360.com/?ref=aihub.cn
2023年11月
奇元大模型
產品介紹及功能: 11月4日,360大模型「奇元大模型」透過備案落地。從大模型定位和應用角度來看,奇元大模型具備充足的靈活性和可擴展性,商業化和產品定位以B端用戶為主,後期將會聚焦更多的商業化應用和垂直領域,幫助使用者提升工作效率。
2023年9月
中文原生AI繪畫模型—BDM
產品介紹: BDM是360 人工智慧研究院發布的中文原生AI繪畫模型,該模型能夠精確生成中文語義圖像,相容於英文社群插件,實現中英雙語繪畫。

產品功能:高品質影像生成,BDM 使用先進的擴散模型技術,可以產生具有高度細節和真實感的影像;多模態輸入,BDM 支援輸入,如文字、影像和音訊等多類型,可以處理各種創意任務; 強大的風格遷移能力,BDM 可以將一種藝術風格應用到任何影像上,從而創造出獨特的視覺效果;即時預覽和編輯,提供即時影像預覽和編輯功能,使用者可以在生成過程中進行調整和最佳化;個人化定制,BDM 允許用戶根據自己的需求和喜好進行個性化設置,例如調整參數、添加自訂元素等。跨平台相容,BDM 適用於各種作業系統和設備,如Windows、macOS、Linux、Android 和iOS。
論文網址:https://arxiv.org/pdf/2309.00952.pdf
2023年3月
認知型通用大模型—360智腦
產品介紹: 360智腦是360自研認知型通用大模型,依托360多年累積的大算力、大數據、工程化等關鍵優勢,整合了360GPT大模型、360CV大模型、360多模態大模型技術能力。

產品功能: 360智腦大模型具備生成創作、多輪對話、程式碼能力、邏輯推理、知識問答、閱讀理解、文本分類、翻譯、改寫、多模態十大核心能力、數百項細分功能,重塑人機協作新範式,全面升級生產效率。
使用人群或場景:內容創作、文件處理
體驗網址:https://ai.360.com/
總結:上述8家中國互聯網大廠的50款大模型及應用,能否超越GPT-4?這似乎需要用時間來證明一切。(鈦媒體AGI)